主要内容
损失
回归误差
描述
输入参数
输出参数
例子
计算样本中的MSE
加载carsmall数据集。考虑位移,马力,及重量作为反应的预测因子英里/加仑.
负载carsmallX =[排量马力重量];
使用所有的观察结果生长一棵回归树。
树= fitrtree (X, MPG);
估计样本内MSE。
L=损失(树,X,MPG)
L = 4.8952
找出产生最佳样本损失的修剪水平
加载carsmall数据集。考虑位移,马力,及重量作为反应的预测因子英里/加仑.
负载carsmallX =[排量马力重量];
使用所有的观察结果生长一棵回归树。
Mdl = fitrtree (X, MPG);
查看回归树。
视图(Mdl,“模式”,“图”);

找出产生最佳样本损失的最佳修剪水平。
[L、se、NLeaf、bestLevel]=损失(Mdl、X、MPG、,“子树”,“全部”);bestLevel
bestLevel = 1
最佳的修剪级别是第1级。
将树修剪到第1级。
pruneMdl =修剪(Mdl,“水平”, bestLevel);视图(pruneMdl,“模式”,“图”);

检查每个子树的MSE
未运行的决策树倾向于过度拟合。平衡模型复杂性和样本外性能的一种方法是修剪树(或限制其增长),以使样本内和样本外性能都令人满意。
加载carsmall数据集。考虑位移,马力,及重量作为反应的预测因子英里/加仑.
负载carsmallX =[排量马力重量];Y = MPG;
将数据分成训练集(50%)和验证集(50%)。
n =大小(X, 1);rng (1)%的再现性idxTrn=false(n,1);idxTrn(randsample(n,round(0.5*n)))=true;%训练集逻辑索引idxVal = idxTrn == false;%验证设置逻辑索引
使用训练集生长回归树。
Mdl = fitrtree (X (idxTrn:), Y (idxTrn));
查看回归树。
视图(Mdl,“模式”,“图”);
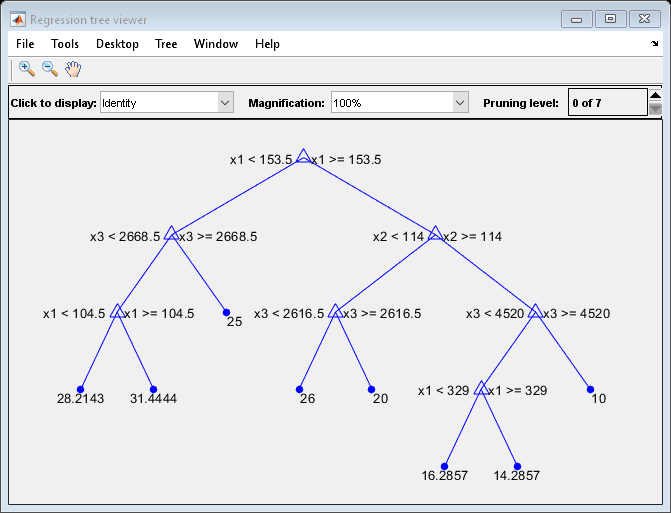
回归树有七个修剪级别。级别0是完整的、未修剪的树(如所示)。第7级只是根节点(即没有分割)。
检查每个子树(或修剪层次)的训练样本MSE,排除最高层次。
m = max(Mdl.PruneList) - 1;trnLoss = resubLoss (Mdl,“子树”,0:m)
特朗罗斯=7×15.9789 6.2768 6.8316 7.5209 8.3951 10.7452 14.8445
完整的未运行树的MSE约为6个单位。
修剪到级别1的树的MSE约为6.3个单位。
修剪至第6级的树木(即树桩)的MSE约为14.8个单位。
检查除最高水平外的每个水平的验证样本MSE。
valLoss =损失(Mdl X (idxVal:), Y (idxVal),“子树”,0:m)
瓦尔洛斯=7×132.1205 31.5035 32.0541 30.8183 26.3535 30.0137 38.4695
对于完整的,未修剪的树(级别0)的MSE大约是32.1个单位。
修剪到4级的树的MSE约为26.4个单位。
修剪到5级的树的MSE约为30.0单位。
修剪到第6级(即树桩)的树木的MSE约为38.5个单位。
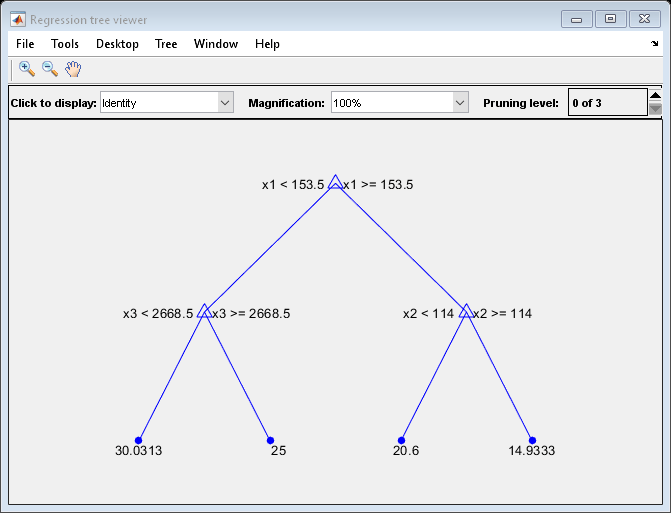
要平衡模型复杂性和样本外性能,请考虑修剪Mdl到4级。
pruneMdl =修剪(Mdl,“水平”4);视图(pruneMdl,“模式”,“图”)
更多关于
扩展功能
您还可以从以下列表中选择网站:
