主要内容
簇
利用高斯混合分布构造聚类
语法
描述
例子
群集数据
通过使用mvnrnd函数。使用fitgmdist函数。然后,使用簇函数将数据划分为由拟合的GMM组件确定的两个簇。
定义两个二元高斯混合分量的分布参数(均值和协方差)。
mu1=[2];%第一分量的平均值sigma1=[20;01];%第一分量的协方差mu2=[-2-1];%第二分量的平均值sigma2=[10;01];%第二分量的协方差
从每个组件生成相等数量的随机变量,并将两组随机变量组合在一起。
rng(“默认”)%为了再现性r1=mvnrnd(mu1,sigma11000);r2=mvnrnd(mu2,sigma21000);X=[r1;r2];
组合数据集X包含两个二元高斯分布混合后的随机变量。
将双组分GMM安装到X.
gm=fitgmdist(X,2);
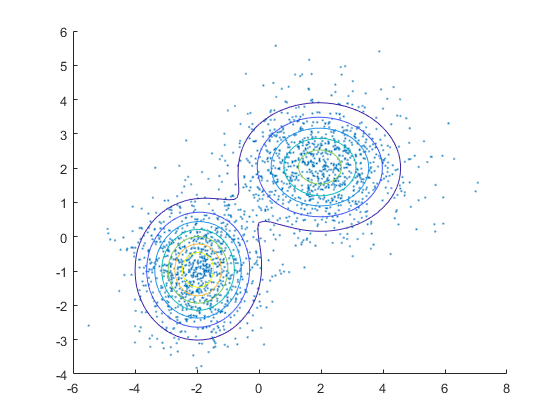
情节X利用分散.可视化安装的模型转基因的利用pdf和福康图尔.
数字散点(X(:,1),X(:,2),10,'.')%点大小为10的散点图持有在…上gmPDF=@(x,y)arrayfun(@(x0,y0)pdf(gm,[x0-y0]),x,y);fcontour(gmPDF,[-68-46])
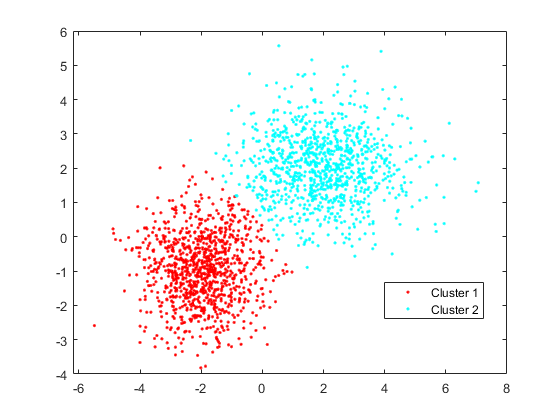
通过将拟合的GMM和数据传递给簇.
idx=簇(gm,X);
使用gscatter创建按分组的散点图的步骤idx.
图;gscatter(X(:,1),X(:,2),idx);图例(“集群1”,“集群2”,“位置”,“最好的”);
输入参数
输出参数
在R2007b中引入
您还可以从以下列表中选择网站:
