nlpredci.
非线性回归预测置信度间隔
句法
描述
例子
非线性回归曲线的置信区间
加载样本数据。
s = load('反应');x = s.readants;y = s.rate;beta0 = s.beta;
使用初始值将Hougen-Watson模型适合速率数据Beta0.。
[beta,r,j] = nlinfit(x,y,@ hougen,beta0);
在平均反应物水平下获得预测的响应和95%置信区间半宽度,用于曲线的值。
[ypred,delta] = nlpredci(@ hougen,平均(x),beta,r,'雅各比亚'j)
Ypred = 5.4622.
delta = 0.1921.
计算曲线值的95%置信区间。
[ypred-delta,ypred + delta]
ans =.1×25.2702 5.6543
新观察预测间隔
加载样本数据。
s = load('反应');x = s.readants;y = s.rate;beta0 = s.beta;
使用初始值将Hougen-Watson模型适合速率数据Beta0.。
[beta,r,j] = nlinfit(x,y,@ hougen,beta0);
获得预测的响应和95%预测间隔半宽,用于与反应水平的新观察[100,100,100]。
[ypred,delta] = nlpredci(@hougen,[100,100,100],beta,r,'雅各比亚',j,......'predopt'那'观察')
Ypred = 1.8346.
delta = 0.5101.
计算新观察的95%预测间隔。
[ypred-delta,ypred + delta]
ans =.1×21.3245 2.3447
坚固符合曲线的同步置信区间
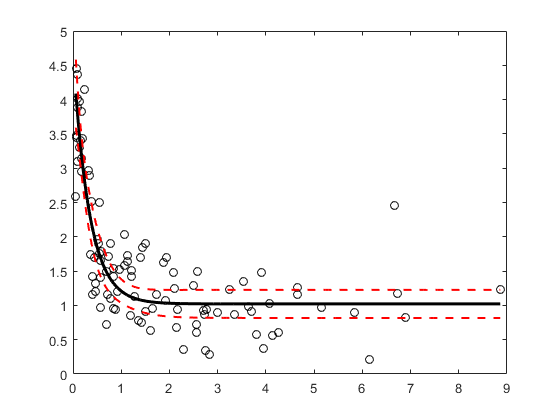
从非线性回归模型生成示例数据 , 在哪里 那 , 和 是系数,误差项通常以平均值0分布,标准偏差0.5。
modelfun = @(b,x)(b(1)+ b(2)* exp(-b(3)* x));RNG('默认')重复性的%B = [1; 3; 2];x = EXPRND(2,100,1);y = modelfun(b,x)+ normrnd(0,0.5,100,1);
使用强大的拟合选项拟合非线性模型。
opts = statset('nlinfit');opts.robustwgtfun ='Bisquare';beta0 = [2; 2; 2];[Beta,R,J,CoVB,MSE] = NlinFit(x,y,modelfun,beta0,选择);
绘制拟合的回归模型,同时95%的置信度。
xrange = min(x):01:max(x);[ypred,delta] = nlpredci(modelfun,xrange,beta,r,'COVAR',covb,......'妈妈',MSE,'simopt'那'在');较低= ypred - delta;upper = ypred + delta;图()绘图(x,y,'ko')%观察到的数据抓住在绘图(Xrange,Ypred,'K'那'行宽',2)绘图(Xrange,[降低;上部],'r--'那'行宽',1.5)
使用观察重量的置信区间
加载样本数据。
s = load('反应');x = s.readants;y = s.rate;beta0 = s.beta;
指定用于观察权重的函数句柄,然后使用指定的观察权重函数将Hougen-Watson模型适合速率数据。
a = 1;B = 1;权重= @(yhat)1./((+ b * abs(yhat))。^ 2);[beta,r,j,covb] = nlinfit(x,y,@ hougen,beta0,'重量',重量);
计算95%的预测间隔,以进行反应水平的新观察[100,100,100]使用观察重量函数。
[ypred,delta] = nlpredci(@hougen,[100,100,100],beta,r,'雅各比亚',j,......'predopt'那'观察'那'重量',重量);[ypred-delta,ypred + delta]
ans =.1×21.5264 2.1033
使用非符合误差模型的置信区间
加载样本数据。
s = load('反应');x = s.readants;y = s.rate;beta0 = s.beta;
使用组合的误差方差模型将Hougen-Watson模型拟合到速率数据。
[Beta,R,J,CoVB,MSE,S] = nlinfit(x,y,@ hougen,beta0,'errormodel'那“合并”);
计算95%的预测间隔,以进行反应水平的新观察[100,100,100]使用拟合误差方差模型。
[ypred,delta] = nlpredci(@hougen,[100,100,100],beta,r,'雅各比亚',j,......'predopt'那'观察'那'errormodelinfo',s);[ypred-delta,ypred + delta]
ans =.1×21.3245 2.3447
输入参数
输出参数
更多关于
尖端
算法
如果是雅各比亚,
j,没有完整的列等级,那么一些模型参数可能是不合格的。在这种情况下,nlpredci.试图建造可估计预测的置信区间和回报南对于那些不是。
参考
[1] Lane,T.P.和W.H. Dumouchel。“多元回归中的同步置信区间。”美国统计学家。卷。48,4,1994,第315-321页。
[2] SEBER,G. A. F.和C. J. Wild。非线性回归。Hoboken,NJ:Wiley-Interscience,2003。
您还可以从以下列表中选择一个网站:
