zscore
标准化z分数
语法
描述
Z= zscore(X)X这样的列X集中到均值0,缩放到标准差1。Z的尺寸与相同X.
如果
X是向量吗Z是向量z分数。如果
X是一个矩阵,然后Z的大小与相同的矩阵X,每一列Z具有平均为0,标准偏差为1。为多维数组,z分数在
Z沿着第一个nonsingleton维度的X.
例子
两个数据向量的Z-Scores
计算和绘制 -scores两个数据载体,然后比较其结果。
加载示例数据。
负载lawdata
两个变量加载到工作区中:平均绩点和LSAT..
在相同的坐标轴上绘制两个变量。
情节((gpa, lsat))传说(“成绩”,'LSAT',“位置”,“东”)
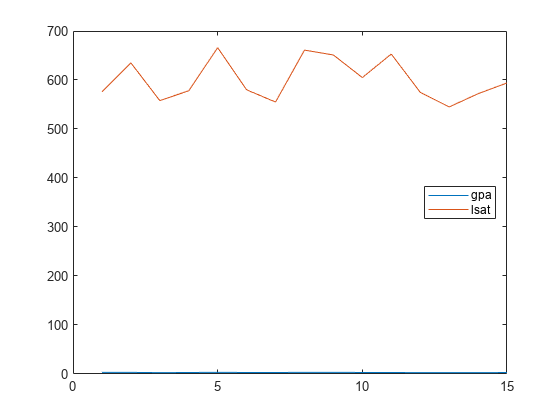
很难比较这两种措施,因为它们的规模非常不同。
绘出
的-scores平均绩点和LSAT.在相同的坐标轴上。
Zgpa = zscore(GPA);Zlsat = zscore(LSAT);积([Zgpa,Zlsat])图例(“gpa z分数”,“LSAT Z评分”,“位置”,“东北”)
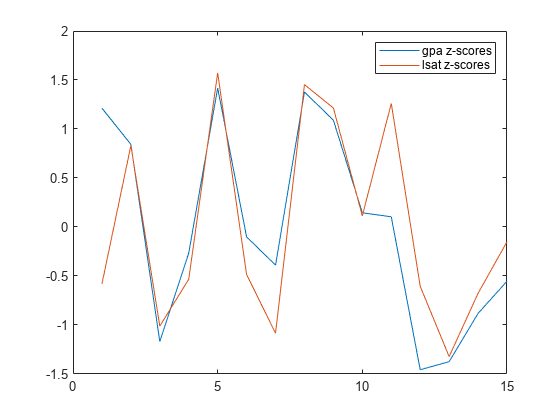
现在,你可以看到个体的相对表现平均绩点和LSAT.结果。例如,第三个人平均绩点和LSAT.结果均低于样本均值一个标准差。11个人的平均绩点是否在样本均值附近,但有一个LSAT.得分比样本平均水平高出近1.25个标准差。
检查的平均值和标准偏差 创建分数。
意思是([Zgpa Zlsat])
ans =1×210-14×-0.1088 - 0.0357
性病([Zgpa Zlsat])
ans =1×21 1
根据定义,
的-scores平均绩点和LSAT.均值为0,标准差为1。
Z值的数对样品
加载示例数据。
负载lawdata
两个变量加载到工作区中:平均绩点和LSAT..
计算
的-scores平均绩点使用标准偏差的人口式。
Z1 = zscore (gpa, 1);%的人口公式Z0 = zscore(GPA,0);%样本公式disp ((Z1 Z0))
1.2554 1.2128 0.8728 0.8432 -1.2100 -1.1690 -0.2749 -0.2656 1.4679 1.4181 -0.1049 -0.1013 -0.4024 -0.3888 1.4254 1.3771 1.1279 1.0896 0.1502 0.1451 0.1077 0.1040 -1.5076 -1.4565 -1.4226 -1.3743 -0.9125 -0.8815 -0.5724 -0.5530
对于从群体,人口标准偏差公式与样品 在分母中对应的是总体标准差的最大似然估计,可能是有偏的。另一方面,样本标准差公式是一个样本总体标准差的无偏估计量。
数据矩阵的Z-Scores
计算 -使用沿着数据矩阵的列或行计算的平均值和标准偏差得到的分数。
加载示例数据。
负载流感
数据集的数组流感是在工作场所。流感对11个变量进行了52次观察。第一个变量包含日期(以周为单位)。其他变量包括美国不同地区的流感估计值
将数据集数组转换为数据矩阵。
flu2 =双(流感(:,2:结束));
新的数据矩阵,flu2,是一个52乘10的双数据矩阵。行对应于周,列对应于数据集数组中的美国地区流感.
规范流感估计每个区域(列的flu2).
Z1 = zscore(flu2,[],1);
你可以看到
-scores在变量编辑器中通过双击矩阵Z1在工作区中创建的。
将每周的流感估计标准化行的flu2).
Z2 = zscore(flu2,[],2);
多维数组的Z值
通过指定到标准化沿不同维度中的数据找到一个多维阵列的z分数。使用时比较结果“所有”,昏暗的,vecdim输入参数。
创建一个3 × 4 × 2的数组。
X =重塑(1:24,[3 4 2])
X = X(:,:,1)= 1 4 7 10 2 5 8 11 3 6 9 12 X(:,:,2)= 13 16 19 22 14 17 20 23 15 18 21 24
标准化X用中所有值的均值和标准差X.
卓尔= zscore(X,0,“所有”)
Zall(:,:,2) = Zall(:,: 1) = -1.6263 -1.2021 -0.7778 -0.3536 -1.4849 -1.0607 -0.6364 -0.2121 -1.3435 -0.9192 -0.4950 -0.0707
得到的多维z分数数组的均值为0,标准差为1。例如,计算的平均值和标准差卓尔.
mZall =平均值(卓尔(:,:,:),“所有”)
mZall = -9.2519 e-18
sZall =性病(Zall (:,:,:), 0,“所有”)
sZall = 1.0000
现在规范X沿着第二个维度。
Zdim = zscore (X 0 2)
Zdim(:,: 1) = -1.1619 -0.3873 0.3873 1.1619 -1.1619 -0.3873 0.3873 1.1619 -1.1619 -0.3873 0.3873 1.1619
的每页每行中的元素Zdim均值为0,标准差为1。例如,计算的第二页第一行的平均值和标准偏差Zdim.
mZdim =意味着(Zdim (1: 2),“所有”)
mZdim = 0
sZdim =性病(Zdim (1: 2), 0,“所有”)
sZdim = 1
最后,规范X基于第二和第三维度。
Zvecdim = zscore(X,0,[2 3])
Zvecdim = Zvecdim(:,: 1) = -1.4289 -1.0206 -0.6124 -0.2041 -1.4289 -1.0206 - 0.6206 -0.2041 -1.4289 -1.0206 -0.2041 -1.4289 -1.0206 - 0.6206 -0.2041
在每个元件Zvecdim(我::)切片的均值为0,标准差为1。例如,计算中元素的平均值和标准偏差Zvecdim (1::).
mZvecdim =平均值(Zvecdim(1,:,:),“所有”)
mZvecdim = 2.7756 e-17
sZvecdim =性病(Zvecdim (1::), 0,“所有”)
sZvecdim = 1
Z-Scores, Mean和Standard Deviation
返回用于计算的平均值和标准偏差 分数。
加载示例数据。
负载lawdata
两个变量加载到工作区中:平均绩点和LSAT..
返回
的-分数、平均值和标准偏差平均绩点.
[Z, gpamean, gpastdev] = zscore (gpa)
Z =15×11.2128 0.8432 -1.1690 -0.2656 1.4181 -0.1013 -0.3888 1.3771 1.0896 0.1451⋮
gpamean = 3.0947
gpastdev = 0.2435
输入参数
输出参数
更多关于
算法
zscore返回南S适用于任何含有南年代。
zscore返回0■对于恒定(所有值都相同)的任何样品。例如,如果X是相同数值的向量吗Z是向量0年代。
扩展能力
你也可以从以下列表中选择一个网站:
