文本数据准备
导入文本数据到MATLAB®和它进行预处理分析
功能
主题
进口
这个例子说明了如何从文本,HTML的Microsoft®Word,PDF,CSV和Microsoft Excel档案提取文本数据,并将其导入MATLAB®进行分析。
此示例示出了如何解析HTML代码并提取从特定元件的文本内容。
发现数据集各种文本分析任务。
预处理
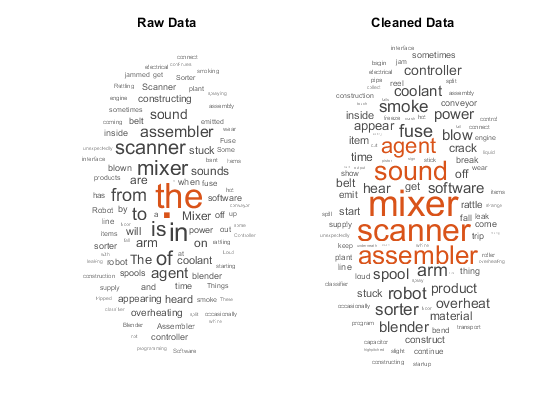
此示例示出了如何创建一个功能,其清洗并预处理的文本数据进行分析。
这个例子说明了如何分析包含表情符号,文本数据。
这个例子说明了如何使用中的hunspell文件正确拼写。
这个例子显示了如何创建一个扩展的hunspell字典拼写校正。
这个例子展示了如何正确拼写使用编辑距离和搜索的已知字的词汇。
精选示例


您还可以选择从下面的列表中的网站:
