trainYOLOv2ObjectDetector
火车yolo v2对象探测器
语法
描述
火车一个检测器
探测器= trainyolov2objectdetector(trainingData,LGRAPH.,选项)LGRAPH.这个选项输入指定检测网络的训练参数。
恢复训练探测器
探测器= trainyolov2objectdetector(trainingData,检查站,选项)
你可以使用这个语法:
添加更多的训练数据并继续训练。
提高通过增加迭代的最大数量的训练精度。
微调检测器
探测器= trainyolov2objectdetector(trainingData,探测器,选项)
例子
列车YOLO v2车辆检测网络
将车辆检测的训练数据加载到工作空间。
data =负载('vevicletrainingdata.mat');培训数据=数据。车辆培训数据;
指定存储培训样本的目录。在培训数据中添加文件名的完整路径。
dataDir=fullfile(toolboxdir(“愿景”),'VisionData');trainingData。我mageFilename = fullfile(dataDir,trainingData.imageFilename);
随机洗牌数据进行训练。
rng (0);shuffledIdx = randperm(高度(trainingData));trainingData = trainingData (shuffledIdx:);
使用表中的文件创建一个imageDatastore。
IMDS = imageageAtastore(trainingData.ImageFilename);
使用表中的标签列创建BoxLabeldAtastore。
建筑物= boxLabelDatastore (trainingData(:, 2:结束));
组合数据存储。
Ds = combine(imds, blds);
加载预初始化的YOLO v2对象检测网络。
网=负载(“yolov2VehicleDetector.mat”);lgraph = net.lgraph
LGRAPHE=LayerGraph,属性:Layers:[25×1 nnet.cnn.layer.layer]连接:[24×2表格]输入名称:{'input'}输出名称:{'YOLOV2OUTPUTTALYER'}
检查YOLO V2网络中的图层及其属性。您还可以按照所提供的步骤创建YOLO V2网络创建YOLO V2目标检测网络.
lgraph.Layers
ANS = 25×层阵列层:1 '输入' 图像输入128x128x3图像2 'conv_1' 卷积16分3×3的卷积与步幅[1 1]和填充[1 1 1 1] 3 'BN1' 批量标准化批正常化4 'relu_1'RELU RELU 5 'maxpool1' 最大池2x2的最大蓄留与步幅[2 2]和填充[0 0 0 0] 6 'conv_2' 卷积32分3×3的卷积与步幅[1 1]和填充[1 1 1 1] 7“BN2'批量标准化批正常化8 'relu_2' RELU RELU 9 'maxpool2' 最大池2x2的最大蓄留与步幅[2 2]和填充[0 0 0 0] 10 'conv_3' 卷积64分3×3的卷积与步幅[1 1]和填充[1 1 1 1] 11 'BN3' 批量标准化批正常化12 'relu_3' RELU RELU 13 'maxpool3' 最大池2x2的最大蓄留与步幅[2 2]和填充[0 0 0 0] 14 'conv_4' 卷积128 3x3的与步幅[1 1]和填充[1 1 1 1] 15 'BN4' 批量标准化批正常化16 'relu_4' RELU RELU 17 'yolov2Conv1' 卷积128分的3×3的卷积与步幅[1 1卷积]和p一个dding 'same' 18 'yolov2Batch1' Batch Normalization Batch normalization 19 'yolov2Relu1' ReLU ReLU 20 'yolov2Conv2' Convolution 128 3x3 convolutions with stride [1 1] and padding 'same' 21 'yolov2Batch2' Batch Normalization Batch normalization 22 'yolov2Relu2' ReLU ReLU 23 'yolov2ClassConv' Convolution 24 1x1 convolutions with stride [1 1] and padding [0 0 0 0] 24 'yolov2Transform' YOLO v2 Transform Layer. YOLO v2 Transform Layer with 4 anchors. 25 'yolov2OutputLayer' YOLO v2 Output YOLO v2 Output with 4 anchors.
配置网络培训选项。
选择= trainingOptions ('SGDM',......“InitialLearnRate”,0.001,......“放牧”,真的,......'MiniBatchSize'16,......'maxepochs',30,......“洗牌”,'绝不',......“详细频率”,30,......“CheckpointPath”,Tempdir);
培训YOLO v2网络。
[探测器,信息] = Trainyolov2ObjectDetector(DS,LGraph,选项);
************************************************************************* 培训YOLO v2意思对象探测器以下对象类:*车辆培训单CPU。|========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习 | | | | ( hh: mm: ss) | RMSE | |率损失 | |========================================================================================| | 1 | 1 | 00:00:01 | 7.13 | 50.8 | 0.0010 | | 2 |3.0|00:00:14 | 1.35 | 1.8 | 0.0010 | | 4 | 60 | 00:00:27 | 1.13 | 1.3 | 0.0010 | | 5 | 90 | 00:00:39 | 0.64 | 0.4 | 0.0010 | | 7 | 120 | 00:00:51 | 0.65 | 0.4 | 0.0010 | | 9 | 150 | 00:01:04 | 0.72 | 0.5 | 0.0010 | | 10 | 180 | 00:01:16 | 0.52 | 0.3 | 0.0010 | | 12 | 210 | 00:01:28 | 0.45 | 0.2 | 0.0010 | | 14 | 240 | 00:01:41 | 0.61 | 0.4 | 0.0010 | | 15 | 270 | 00:01:52 | 0.43 | 0.2 | 0.0010 | | 17 | 300 | 00:02:05 | 0.42 | 0.2 | 0.0010 | | 19 | 330 | 00:02:17 | 0.52 | 0.3 | 0.0010 | | 20 | 360 | 00:02:29 | 0.43 | 0.2 | 0.0010 | | 22 | 390 | 00:02:42 | 0.43 | 0.2 | 0.0010 | | 24 | 420 | 00:02:54 | 0.59 | 0.4 | 0.0010 | | 25 | 450 | 00:03:06 | 0.61 | 0.4 | 0.0010 | | 27 | 480 | 00:03:18 | 0.65 | 0.4 | 0.0010 | | 29 | 510 | 00:03:31 | 0.48 | 0.2 | 0.0010 | | 30 | 540 | 00:03:42 | 0.34 | 0.1 | 0.0010 | |========================================================================================| Detector training complete. *************************************************************************
检查探测器的属性。
探测器
detector = yolov2ObjectDetector带有属性:ModelName: 'vehicle' Network: [1×1 DAGNetwork] TrainingImageSize: [128 128] AnchorBoxes: [4×2 double] ClassNames: vehicle
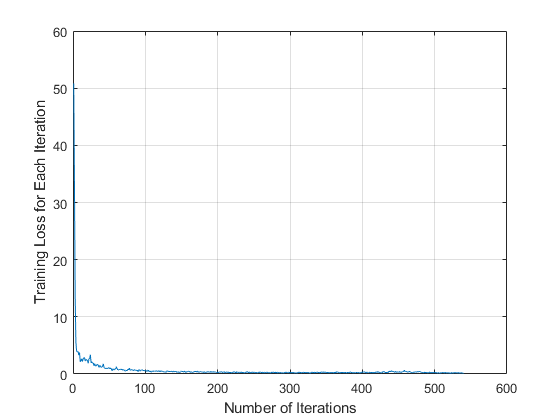
您可以通过检查每个迭代训练损失验证训练精度。
图图(info.TrainingLoss)网格在xlabel('迭代数量')ylabel('每次迭代的训练损失')
将测试图像读入工作区。
IMG = imread('detectcars.png');
运行车辆检测测试图像的训练YOLO V2对象检测器。
[bboxes,分数]=检测(探测器,img);
显示检测结果。
如果(~isempty(bboxes)) img = insertObjectAnnotation(img,“矩形”,bboxes,分数);结束图imshow (img)

输入参数
trainingData- - - - - -标记地面真像
数据存储|表格
标记地面真值图像,指定为数据存储或表。
如果使用数据存储,则必须设置数据,以便将数据存储调用
读和readall函数返回具有两列或三列的单元格数组或表。当输出包含两列时,第一列必须包含包围框,第二列必须包含标签,{盒子,标签}。当输出包含三列时,第二列必须包含边界框,第三列必须包含标签。在这种情况下,第一列可以包含任何类型的数据。例如,第一列可以包含图像或点云数据。数据 盒子 标签 第一列可以包含数据,例如点云数据或图像。 第二列必须是一个单元阵列,其中包含米-形式的边界框的by-5矩阵[x中央,y中央,宽度,高度,偏航].矢量代表每个图像中对象的边界框的位置和大小。 第三列必须是包含的单元数组米-包含对象类名的by-1分类向量。数据存储返回的所有分类数据必须包含相同的类别。 欲了解更多信息,请参阅用于深度学习的数据存储(深学习工具箱).
如果使用表,则该表必须有两个或更多列。表的第一列必须包含带有路径的图像文件名。图像必须是灰度或真彩色(RGB),他们可以在任何格式的支持金宝app
Imread..每个剩余列必须是包含的单元格向量米-by-4矩阵,表示单个对象类,例如车辆,花, 或者停止标志这个columns contain 4-element double arrays of米格式的边界框[x,y,宽度,高度].该格式指定了相应图像中边界框的左上角位置和大小。要创建一个地面真值表,可以使用图片标志应用程序或贴标签机视频应用程序。若要从产生地面实况训练数据表,使用objectDetectorTrainingData函数。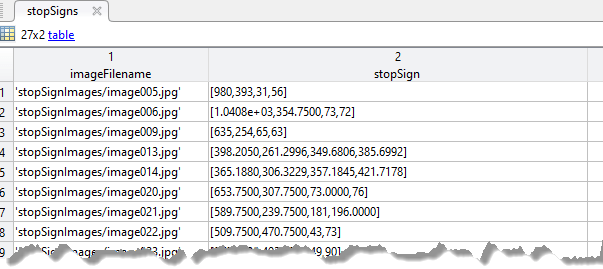

请注意
当使用表指定训练数据时,trainYOLOv2ObjectDetector功能检查这些条件
边界框值必须是整数。否则,该函数会自动将每个非整数值舍入到最接近的整数。
边界框不能为空,且必须在图像区域内。而训练网络,该函数忽略空包围盒并且位于部分或完全的图像区域外的边界框。
LGRAPH.- - - - - -层图
LayerGraph对象
图层图,指定为LayerGraph对象。层图描述了YOLO v2的网络结构。您可以使用yolov2Layers函数。或者,您可以使用yolov2TransformLayer,yolov2reorglayer., 和yolov2OutputLayer职能。有关创建自定义YOLO V2网络的更多详细信息,请参阅设计一个YOLO V2探测网.
选项- - - - - -培训方案
TrainingOptionsSGDM.对象|培训选项RMSPROP对象|培训选项ADAM对象
检查站- - - - - -保存探测器检查点
yolov2ObjectDetector对象
保存的检查点检测器,指定为yolov2ObjectDetector对象。在每个时代保存探测器,设置“CheckpointPath”的名称-值参数培训选项函数。建议在每个epoch之后保存一个检查点,因为网络训练可能需要几个小时。
要为先前训练过的检测器加载检查点,请从检查点路径加载mat -文件。例如,如果检查点路径指定的对象的属性选项是“/checkpath”,您可以使用此代码加载检查点mat文件。
data =负载('/checkpath/yolov2_checkpoint__216__2018_11_16__13_34_30.mat');检查点= data.detector;
MAT文件的名称包括探测器检查点时的迭代号和时间戳。探测器保存在探测器该文件的变量。通过这个文件回trainYOLOv2ObjectDetector功能:
yoloDetector=trainYOLOv2ObjectDetector(训练数据、检查点、选项);
探测器- - - - - -以前训练的YOLO V2对象检测器
yolov2ObjectDetector对象
以前训练的YOLO V2对象检测器,指定为ayolov2ObjectDetector对象。使用此语法继续使用额外的训练数据训练检测器,或执行更多的训练迭代以提高检测器的准确性。
训练- - - - - -用于多尺度训练的图像尺寸集
[](默认)|米-by-2矩阵
用于多尺度训练的图像尺寸集合,指定为米-by-2矩阵,其中每行的形式如下[高度宽度].对于每个训练时期,输入训练图像被随机地调整到的一个米此集中指定的图像大小。
如果不指定训练,函数将该值设置为YOLO v2网络的图像输入层中的大小。网络将所有训练图像的大小调整为这个值。
请注意
输入训练为多尺度培训指定的值必须大于或等于图像输入层中的输入大小LGRAPH.输入参数。
输出参数
更多关于
提示
要生成地面真相,请使用图片标志或者贴标签机视频应用程序。若要从产生地面实况训练数据表,使用
objectDetectorTrainingData函数。为了提高预测精度,,
增加可以用于训练网络的图像数量。您可以通过数据增强来扩展训练数据集。有关如何将数据增强应用于预处理的信息,请参见深度学习的图像预处理(深学习工具箱).
进行多尺度训练
trainYOLOv2ObjectDetector函数。要做到这一点,指定'TeacherivageSize.'的论点trainYOLOv2ObjectDetector培训网络的功能。选择适合于数据集的锚框以培训网络。你可以使用
extimateanchorboxes.函数直接从训练数据计算锚盒。
工具书类
[1]约瑟。R, S. K. Divvala, R. B. Girshick和F. Ali。“你只看一次:统一的、实时的物体检测。”在在IEEE会议计算机视觉与模式识别(CVPR)论文集,第779-788页。内华达州拉斯维加斯:CVPR,2016年。
[2]约瑟。R和f。“YOLO 9000:更好、更快、更强。”在在IEEE会议计算机视觉与模式识别(CVPR)论文集, 6517 - 6525页。檀香山,HI: CVPR, 2017。
另请参阅
应用
功能
objectDetectorTrainingData|trainFasterRCNNObjectDetector|trainFastRCNNObjectDetector|trainrcnnobjectdetector|yolov2Layers|培训选项(深学习工具箱)
对象
你也可以从以下列表中选择一个网站:
