入门YOLO V2
在你只-看一次(永乐)V2对象检测器使用单级物体检测网络。YOLO V2比其他两级深学习对象的检测器,诸如与卷积神经网络区域更快(更快速的R-细胞神经网络)。
该YOLO V2模型运行了深刻的输入图像,产生网络预测学习CNN。对象检测器解码的预测,并生成边界框。

在图像预测对象
YOLO V2采用锚箱检测图像中的对象的类。有关详细信息,请参阅锚箱物体检测. YOLO v2预测每个锚盒的这三个属性:
路口过工会(IOU) - 预测每个锚箱的对象性得分。
锚箱偏移 - 细化锚箱位置
类概率 - 预测分配给每个锚箱类的标签。
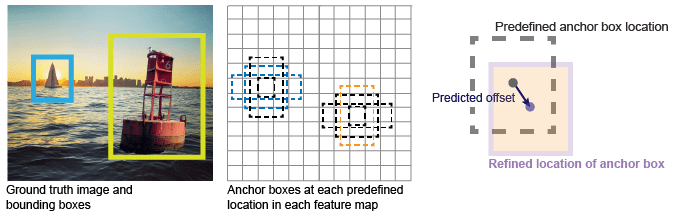
图中显示了特征图中每个位置的预定义锚框(虚线),以及应用偏移量后的细化位置。与类匹配的方框是彩色的。
迁移学习
随着迁移学习,你可以使用预训练CNN作为一个YOLO V2检测网络的特征提取。使用yolov2Layers函数来创建从任何预训练CNN一个YOLO V2检测网络,例如MobileNet V2。对于预训练的细胞神经网络的列表,请参阅预先训练的深度神经网络(深学习工具箱)
你也可以设计一个自定义模型基于一个预先训练的图像分类CNN。有关详细信息,请参阅设计一个YOLO V2探测网。
设计一个YOLO V2探测网
您可以一层一层地设计一个定制的YOLO v2模型。模型从一个特征提取器网络开始,这个特征提取器网络可以从一个预先训练好的CNN初始化,也可以从零开始训练。检测子网络包含一系列的Conv,批量规范,RELU层,随后通过变换层和输出层,yolov2TransformLayer和yolov2OutputLayer对象,分别。yolov2TransformLayer将原始CNN输出到一个窗体需要以产生对象的检测。yolov2OutputLayer定义锚盒参数并实现用于训练检测器的丢失函数。

您也可以使用深层网络设计师应用程序来手动创建的网络。设计师采用了计算机视觉工具箱™YOLO V2功能。
设计一个YOLO V2探测网有个重组层
重组层(使用所创建的yolov2ReorgLayer对象)和深度级联层(使用所创建的depthConcatenationLayer对象)被用来低水平和高水平的功能结合起来。这些层通过加入低水平的图像信息,并提高检测精度更小的物体提高检测。典型地,重组层附着到特征提取网络的输出特征图比特征提取层输出大内的层。
小费
调整
“跨越论”财产的yolov2ReorgLayer对象,使得其输出尺寸相匹配的输入大小depthConcatenationLayer对象。为了简化网络设计,使用交互式深层网络设计师应用程序和
analyzeNetwork功能。

有关如何建立这种网络的更多详细信息,请参阅创建YOLO V2目标检测网络。
训练一个对象检测器,并使用YOLO v2模型检测对象
要了解如何使用YOLO深度学习技术和CNN训练目标探测器,请参见对象检测使用YOLO V2深度学习的例子。
代码生成
要了解如何生成CUDA®代码使用YOLO v2对象检测器(使用yolov2ObjectDetector对象)见代码生成物体检测利用YOLO V2。
标签的训练数据进行深度学习
您可以使用图片标注,视频贴标机, 要么地面真相贴标机(在自动驾驶的工具箱™提供)应用程式交互式标签像素和出口标签的数据进行训练。这些应用也可以用于标记的物体检测,场景标签图像分类利息(投资回报)的矩形区域,并且像素语义分割。
参考文献
[1] Redmon, J.和A. Farhadi。“YOLO9000:更好、更快、更强。”IEEE会议计算机视觉与模式识别(CVPR),6517-6525。檀香山,HI:CVPR 2017年。
[2]雷德曼,J.,S. Divvala,R. Girshick,和A.法哈迪。“你只能看一次:统一,实时的目标检测。”IEEE计算机视觉和模式识别(CVPR)会议记录,779-788。拉斯维加斯,内华达州:CVPR年,2016年。
也可以看看
应用
对象
depthConcatenationLayer|yolov2ObjectDetector|yolov2OutputLayer|yolov2ReorgLayer|yolov2TransformLayer
职能
相关的例子
更多关于
- 锚箱物体检测
- 入门与R-CNN,快速R-CNN,以及更快的R-CNN
- MATLAB中的深度学习(深学习工具箱)
- 预先训练的深度神经网络(深学习工具箱)
你也可以从以下列表中选择一个网站:
