降维和特征提取
主成分分析,因素分析,特征选择,特征提取,等等
特征变换技术通过将数据转换为新特性来降低数据的维数。特征选择技术是优选的,当变量变换是不可能的,例如,当存在在数据分类变量。用于特征选择技术,该技术特别适合于最小二乘拟合,见逐步回归。
功能
对象
主题
特征选择
了解特征选择算法和探索可供特征选择的功能。
本主题引入了顺序特征选择和提供了选择功能依次使用自定义标准和示例sequentialfs功能。
邻域成分分析(NCA)是一种非参数的特征选择方法,其目标是最大化回归和分类算法的预测精度。
在不损害模型的预测能力去除预测做一个更强大和更简单的模型。
使用交互测试算法为随机森林选择分裂预测因子。
t-SNE多维可视化
叔SNE是用于通过非线性还原可视化高维数据,以两个或三个维度,同时保留原始数据的某些特征的方法。
这个例子中示出了T-SNE如何产生高维数据的有用的低维嵌入。
该示例示出的各种效果tsne设置。
t-SNE的输出函数描述和例子。
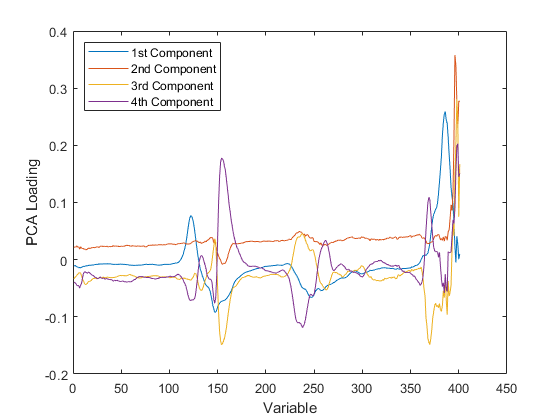
因子分析
因子分析是一种将模型拟合到多元数据的方法,用来估计被测变量对较少数量的未观察(潜在)因素的相互依赖性。
使用因子分析来调查同一行业内的公司是否经历了类似的每周股价变化。
这个例子展示了如何使用统计数据和机器学习工具箱执行因子分析。
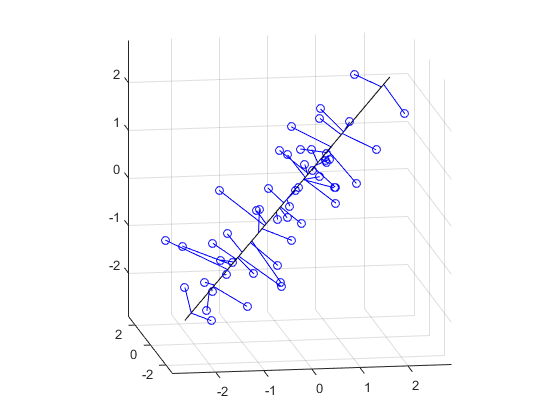
多维标度
多维标度允许您可视化不同距离或不同度量的点之间的距离,并可以在少量维中生成数据的表示。
使用cmdscale执行经典(度量)多维标度,也称为主坐标分析。
此示例演示如何使用cmdscale功能在统计和机器学习工具箱™。
这个例子展示了如何使用多维标度(MDS)的非经典形式来可视化不同的数据。
使用非经典多维缩放mdscale。
精选示例

你也可以从以下列表中选择一个网站:
