我们来谈谈线性二次调节器,或LQR控制。LQR是一种基于状态空间表示的最优控制。在这个视频中,我想从一个非常高的层次来介绍这个主题,这样你们就能对控制问题有一个大致的了解,并且在学习控制问题背后的数学知识时可以以此为基础。我会讲到什么是最优的,如何考虑LQR问题,然后我会给你们看一些MATLAB中的例子我想这会帮助你们对LQR有一些直观的了解。我是Brian,欢迎来到MATLAB技术讲座。
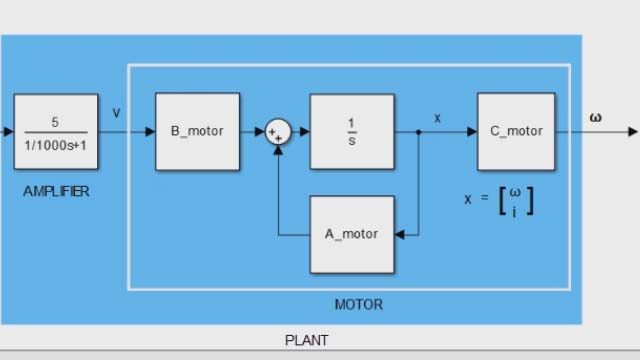
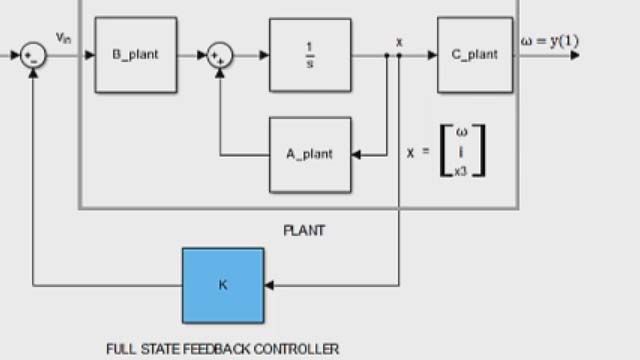
首先,让我们比较我们在第二视频和LQR控制器中覆盖的极点放置控制器的结构。这样你就有一些事情是如何不同的。通过极点放置,我们发现,如果我们在状态向量中回馈每个状态并将它们乘以增益矩阵,则我们有能力在我们选择的任何地方放置闭环极点,假设系统是可控的和可观察的。然后我们缩放了参考术语以确保我们没有稳定的态参考跟踪错误。
另一方面,LQR结构反馈完整的状态向量,然后将其乘以增益矩阵K,并从缩放的参考中减去它。正如你所看到的,这两个控制律的结构是完全不同的,实际上,它们是完全相同的。它们都是全状态反馈控制器,我们可以用相同的结构从LQR和极点配置实现结果。
关于这个结构的一个简短的注释:我们可以设置它来反馈输出的积分,或者我们可以将增益应用到状态误差上。所有这三种实现都可以产生零稳态误差,并且可以与极点配置或LQR的结果一起使用。如果你想了解更多关于这两种反馈结构的信息,我在描述中留下了一个很好的来源。
好吧,我们回来了。那么,如果这两个控制器的实现方式完全相同,为什么我们要给它们不同的名称呢?好吧,钥匙在这里。实现方法是一样的,但是我们如何选择K是不同的。
对于极点的布置,我们通过选择闭环极点的位置来求出K。我们想的地方他们在一个特定的地点。这是太棒了!但这个方法的一个问题是找出闭环极点的好位置。对于高阶系统和带有多个执行器的系统,这可能不是一个非常直观的答案。
对于LQR,我们不选择极点位置。我们通过选择对我们来说很重要的闭环特性来找到最优的K矩阵——具体来说,就是系统的性能如何,以及获得这种性能需要付出多少努力。这种说法可能没有什么意义,所以让我们快速进行一个思考练习,我认为会有帮助。
我借用并修改了Christopher Lum的例子,他有自己的关于LQR的视频,如果你想更深入地解释数学,值得一看。我在描述中链接了他的视频。但它的大意是:
让我们说你试图找出从你家工作的最佳方式或最优越的方式。您有几个可供选择的交通选择。你可以驾驶你的车,你可以骑自行车,乘坐公共汽车,或者装备直升机。问题是,这是最佳选择?这一问题本身无法回答,因为我没有告诉过你一个好的结果意味着什么。所有这些选项都可以让我们从家里工作,但他们这样做的不同,我们需要弄清楚对我们很重要。如果我说时间是最重要的事情,那么尽快工作,那么最佳的解决方案就是采取直升机。另一方面,如果我说你没有多少钱并尽可能便宜地工作是一个好的结果,那么骑自行车就是最佳的解决方案。
当然,在现实生活中,你没有无限的金钱来最大化性能,也没有无限的时间来最小化支出,但你要在两者之间找到平衡。所以你可能会认为你有一个提前的会议,因此珍惜去上班所花费的时间,但你不是独立的富人,所以你关心它需要多少钱。因此,最佳的解决方案是自己开车或坐公交车。
现在,如果我们想用一种有趣的方法来从数学上评估哪种交通方式是最优的,我们可以建立一个函数,将出行时间和每种选择所花费的金钱相加。然后我们可以用乘数来衡量时间和金钱的重要性。我们将根据自己的个人偏好对每个矩阵进行加权。我们称它为代价函数,或目标函数,你可以看到它很大程度上受到权重参数的影响。如果Q高,我们就会惩罚花费更多时间的选项,如果R高,我们就会惩罚花费大量金钱的选项。一旦我们设置了权重,我们就会计算每个选项的总成本,并选择总成本最低的选项。这是最优解。
有趣的是,根据性能和支出的相对权重,会有不同的最佳解决方案。金宝搏官方网站不存在普遍的最优解,只有给定用户需求的最佳解。CEO可能会乘坐直升机,而大学生可能会骑自行车,但考虑到他们的偏好,两者都是最佳选择。
这与我们在设计控制系统时确切的推理是完全相同的推理。我们可以考虑并评估系统在系统表现的程度之间以及我们想要花多少绩效来评估对我们重要的事情。当然,通常我们想要花费多少不是以美元衡量,而是在执行器的努力中,或所需的能量。
这就是LQR如何找到最优增益矩阵。我们建立了一个成本函数,将性能和努力总时间的加权和相加,然后通过解决LQR问题,它返回产生最低成本的增益矩阵,给定系统的动力学。
现在我们与LQR一起使用的成本函数看起来与我们为旅行示例开发的功能不同,但概念完全相同;通过调整Q,我们通过调整Q来惩罚不良表现,通过调整R来惩罚执行器努力。
让我们看看性能对于这个成本函数意味着什么。性能由状态向量来判断。现在,我们假设每个状态都是零,回到初始平衡点。因此,如果系统在非零状态下初始化,它返回零的速度越快,性能就越好,成本也就越低。我们可以通过观察曲线下的面积来测量它恢复到期望状态的速度。这就是积分的作用。面积较小的曲线比面积较大的曲线更接近目标。
然而,状态可以是负的,也可以是正的,我们不想让负值从总成本中减去,所以我们将值平方以确保它是正的。这样做的效果是惩罚更大的错误比惩罚更小的错误更严重,但这是一个很好的妥协,因为它将我们的代价函数变成了一个二次函数。二次函数,如z = x^2 + y^2是凸的,因此有一个确定的最小值。服从线性动力学的二次函数仍然是二次的所以我们的系统也会有一个确定的最小值。
最后,我们希望有能力衡量每个州的相对重要性。因此,Q不是一个单独的数而是一个方阵它的行数和状态数相同。Q矩阵需要是正定的这样当我们将它与状态向量相乘时,得到的值是正的且非零。通常它只是一个对角矩阵沿着对角线是正的。有了这个矩阵,我们可以通过使Q矩阵中相应的值非常大来锁定误差非常小的状态,而我们不太关心的状态则使这些值非常小。
成本函数的另一半是驱动成本的总和。以非常类似的方式,我们看输入向量,我们平方这些项以确保它们是正的,然后用R矩阵对它们进行加权它的对角线上有正的乘数。
我们可以把它写成下面这个更大的矩阵形式,虽然你不经常看到代价函数这样写,但它帮助我们形象化一些东西。Q和R是这个更大的权重矩阵的一部分,但是这个矩阵的非对角项是零。我们可以用N填充这些角,这样整个矩阵仍然是正定的但是现在N矩阵惩罚了输入和状态的叉乘。下载188bet金宝搏虽然用N矩阵来设置代价函数是有用处的,但对于我们来说,我们将保持事情简单,将它设为零,只关注Q和R。
所以通过设置Q和R的值,我们现在有一种方法来明确什么对我们来说是重要的。如果其中一个驱动器非常昂贵而我们想要节省能量,我们就会通过增加相应的R矩阵值来惩罚它。如果你用推进器来控制卫星可能会出现这种情况因为它们会耗尽燃料,而燃料是有限的资源。在这种情况下,你可以接受一个较慢的反应或更多的状态错误,这样你就可以节省燃料。
另一方面,如果性能真的至关重要,那么我们可以通过增加与我们关心的状态对应的Q矩阵值来惩罚状态误差。当使用反作用轮进行卫星控制时,可能会出现这种情况,因为它们使用的能量可以存储在电池中,并通过太阳能电池板补充。因此,为低误差控制使用更多的能量可能是一个很好的权衡。
现在最大的问题是,我们如何解决这个优化问题?最令人失望的答案是解的推导超出了这个视频的范围。但是我在描述部分留了一个很好的链接,如果你想仔细阅读的话。
然而,好消息是,作为一个控制系统设计师,通常你进行LQR设计的方式不是通过手工解决优化问题,而是通过开发一个系统动力学的线性模型,然后通过调整Q和R权重矩阵指定什么是重要的,然后在MATLAB中运行LQR命令求解优化问题,返回最优增益集,然后对系统进行仿真,必要时重新调整Q和R。所以只要你理解Q和R是如何影响闭环行为的,它们是如何惩罚状态误差和执行器努力的,并且你理解这是一个二次优化问题,那么在MATLAB中使用LQR命令来找到最优增益集就相对简单了。
对于LQR,我们将设计问题从如何放置杆子转移到如何设置Q和r。不幸的是,并没有一种适用于所有人的方法来选择这些权重;然而,我认为设置Q和R比选择极点位置更直观。例如,你可以从Q和R的单位矩阵开始,然后通过反复试验和对系统的直觉来调整它们。为了帮助你建立一些直觉,让我们看一些MATLAB中的例子。
好吧,这需要一个稍微解释。让我们从代码开始。我在无摩擦环境中具有非常简单的旋转质量模型,系统具有两个状态,角度和角度率。我正在使用LQR设计一个全态反馈控制器,它真的不可能更简单。我将从第一个对角线条目绑定到角度误差的Q的标识矩阵开始,并且第二个对角线条目与角速率相关联。该系统只有一个致动输入,这是四个旋转推进器,使得所有行动都在一起以创建单个扭矩命令。因此,R只是一个值。
现在我使用LQR命令解决最佳反馈增益,并构建表示闭环动态的状态空间对象。使用控制器设计,我可以模拟对初始条件的响应,即设置为3个弧度。这几乎是整个事情。此脚本中的所有其他内容只是使这个花哨的情节使其更容易理解结果。
好的,让我们运行这个脚本。您可以看到UFO将其初始化为3个弧度。在顶端,我正在跟踪机动所带来的动作是多长时间的性能,以及用多少燃料来完成机动。所以让我们把它踢掉,看看控制器的表现如何。
看,它在5.8秒内用15单位燃料完成了这个动作,牛也在这个过程中,这是重要的部分。当推进器被激活时,它们会产生一个扭矩,随着时间的推移加速UFO。因此,燃油使用量与加速度积分成正比。所以我们加速的时间越长,消耗的燃料就越多。
现在让我们看看我们是否可以用更少的燃料通过惩罚推进器更多。我将R提升到2,然后重新运行模拟。
我们少用了2单位燃料,但代价是多花了3秒。问题是,在这种组合下,它超出了目标一点,不得不浪费时间回来。所以让我们试着放慢最大旋转速度,希望它不会超过。我们要通过惩罚Q矩阵的角速率部分来做到这一点。现在,任何非零利率的成本都是以前的两倍。让我们试试吧。
我们节省了大约一秒因为它没有超调,在这个过程中又减少了一个单位的燃料。好了,小事情说够了。现在让我们通过放松角度误差权重来节省燃料。
好了,现在进展真的很慢了。让我把视频加速一下。最后,我们用了5单位的燃料,不到以前的一半。我们也可以用另一种方法来调整一个非常激进的控制器。
是的,那样快多了。不到两秒,我们的加速度就破纪录了。这样才能把牛抱起来。不幸的是,这是以消耗近100单位燃料为代价的,所以凡事都有不好的一面。好了,希望你们开始看到我们如何通过调整这两个矩阵来调整和调整控制器。这很简单。
现在,我知道这个视频有点拖了,但是用一个不同的脚本,我想快速地向你们展示一个东西,那就是LQR如何比杆位更强大。这里,我有一个不同的状态空间模型,它有三个状态和一个驱动器。我已经定义了Q和R矩阵并解出了最优增益。和之前一样,我会生成一个闭环状态空间模型然后运行初始条件为(1,0,0)的响应。然后画出第一个状态的响应,即从1到0这一步;执行机构工作;以及闭环极点和零点的位置。
让我们运行这个,看看会发生什么。第一个状态可以很好地追踪到0,但代价是大量的驱动。我没有建立任何特别的模型但是假设执行器的努力是所需的推力。这个控制器需要10单位的推力。但是,假设推进器只能产生2单位的推力。这种控制器设计会使推进器饱和我们就得不到我们想要的响应。现在,如果我们使用极点布置来开发这个控制器,现在的问题是我们应该移动这三个极点中的哪个来减少执行器的作用?这不是很直观,对吧?
但对于LQR,我们可以很容易地找到R矩阵,通过提高单个值来惩罚执行器的使用。我会重播脚本。我们看到响应较慢,如预期,但驱动器不再饱和。看看这个,所有三个闭环极点都随着r的单一调整而移动,所以如果我们使用极点放置,我们必须知道像这样移动这些极点,以减少驱动器的努力。那将是相当困难的。
这节课就讲到这里。LQR控制非常强大,希望你能够看到它的设置非常简单,并且能够相对直观地进行调整和调整。最重要的是,它会根据你对表现和努力的衡量,返回一个最佳增益矩阵。所以最终取决于你希望系统如何运行。
如果你不想错过下一个Tech Talk视频,别忘了订阅这个频道。此外,如果你想看看我的频道,控制系统讲座,我也涵盖了更多的控制理论主题。谢谢收看。下次见。