 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家C ^ 5,克里夫的角落收集卡片目录
我一直写书,程序,通讯列和博客自1990年以来。我现在收集所有这些材料到一个存储库中。克里夫的角落收集由458名“文档”,在互联网上所有可用的。有
- 150年博客帖子从克里夫的角落。
- 43列从克里夫的角落版新闻和笔记。
- 用MATLAB 33章从两本书,实验和数值计算与MATLAB。
- 218年从克里夫的实验室项目,EXM两种。
- 14从麻省理工学院公开课程和其他地方的视频记录。
C ^ 5是一个应用程序,一个搜索工具,它就像一个传统的图书馆卡片目录。它允许您进行基于关键字的搜索通过收集和链接网上的材料。响应查询命令生成的分数潜在语义索引、大规模集成电路,使用一个文档矩阵的奇异值分解的关键字。
内容
打开图
这是打开窗口C ^ 5。
c5

输入一个查询,通常只是一个关键词,在顶部的编辑框。这是一个术语。不同的名字文档相关的术语然后显示,一次一个,文档中框。
箭头键允许扫描文档列表和改变。大规模集成电路的分数决定了列表的排序。项数的次数,如果任何,查询词在文档中出现。网页按钮在互联网上访问文档的一个副本。
Knuth不
我的第一个例子,让我们寻找材料我写了提到斯坦福大学名誉教授计算机科学,Donald Knuth。在查询框中输入“knuth”或在命令行上。
c5knuth

第一个文档名称“博客/ c5_blog。m”指的是这篇文章,所以有点自我引用情况。文件后缀。m因为我的博客的源文本是MATLAB程序处理发布命令。
10数”一词,10/29”表示“knuth”出现了10次在本文档中,到目前为止,我们已经看到10的29倍“knuth”出现在整个集合。
点击登录按钮,然后单击右箭头上的十几倍。此日志的连续显示打印命令窗口。文档名称、日期和期限计数降序显示LSI得分。
% knuth%箭头文档项计数lsi日期%的博客/ c5_blog。m 10 10/29 0.594 28日- 8月- 2017博客/ easter_blog % >。18 - 3月- 2013 m 5 15/29 0.553博客/ lambertw_blog % >。米3 18/29 0.183 02 - 9 - 2013% >新闻/ stiff_equations。txt 2 0.182 01 - 2003年5月,20/29博客/ hilbert_blog % >。米2 22/29 0.139 02 - 2月- 2013博客/ random_blog % >。米2 24/29 0.139 17 - 4月- 2015% > exmm /复活节。0.112 m 1 25/29 2016人% >博客/ gef。米3 28/29 0.100 07 - 1月- 2013% > ncmm / ode23tx。2016 0 28/29 0.086% >新闻/ normal_behavior。txt 0 0.070 01 - 2001年5月,28/29博客/ magic_2 % >。05 - 11月- 2012 m 0 28/29 0.059% ..........% > >博客/ denorms。米1 29/29 0.010 21 - 7 - 2014 .........
第二个最相关的文档,”easter_blog。m”,是一篇从2013年开始,描述了一种算法,由Knuth推广,计算日期每年在西方,或公历,复活节是庆祝。这个词数是5,15/29“,所以第一两个文档占总额略超过一半的表象的搜索词。
接下来的六行告诉我们,“knuth”出现在博客的兰伯特W函数,希尔伯特矩阵,随机数字,和乔治活力四射(gef),以及MATLAB新闻和Notes列在2003年对僵硬的微分方程,和实际的MATLAB程序从EXM计算复活节日期。
以下结果与词项零不包含“knuth”的博客文章,但分数LSI表明他们可能相关。最后,博客名为“denorms”denormal浮点数。是通过右键单击右箭头跳过文件与词项为零。
c5setup
我不知道如何解析. html或. pdf文件,所以我收集了所有我写过的原始材料,现在可以在网上使用。有。m博客和MATLAB程序文件,.tex文件乳胶书的章节,. txt文件简报列和记录的视频。总计有458个文件大约3.24 mb的文本。
我有一个计划,c5setup,我自己的笔记本电脑上运行提取所有的单词并生成文档矩阵。这是一个稀疏矩阵的(j, k)th条目的次数kth术语出现在jth文档。它是保存在c5database.mat使用的c ^ 5应用程序。
这个设置处理消除了经常出现的英语单词,如“的”,名单上stopwords。
长度(stopwords)
ans = 177
c5database
清晰的负载c5database谁
类属性名称大小字节16315 x458 16315双稀疏D 458 x1 40628 L字符串1 x1 120156结构T 16315 x1 16315字符串
- 一个是文档矩阵。
- D是一个字符串数组的文件名我个人存储库的源文件。
- l是一个结构体,其中包含字符串数组用于生成文件的url。
- T是一个字符串数组的关键词或条款。
稀疏
文档的稀疏矩阵是百分之一多一点。
稀疏= nnz (A) /元素个数(个)
稀疏= 0.0130
间谍
间谍阴谋文档的第一个1000行矩阵。
clf间谍((1:1000:))

最常见术语
行总结总词数。
ttc =和(2);
找到发生的条件至少1000次。
k =找到(ttc) > = 1000);流(“-10年代% % 6 s \ n”,(T (k) num2str (ttc (k))))
函数1806 1407 matlab矩阵1499一1262两个1090年
惊喜。我写了很多关于MATLAB和矩阵。
奇异值
我们不妨计算所有完整的矩阵的奇异值。需要不到一秒。重要的是要使用产生的经济版本的圣言U一样的大小一个。否则我们会有一个16315 - 16315U。
抽搐(U, V) =圣言(完整的(A),“经济学”);toc
运行时间是0.882556秒。
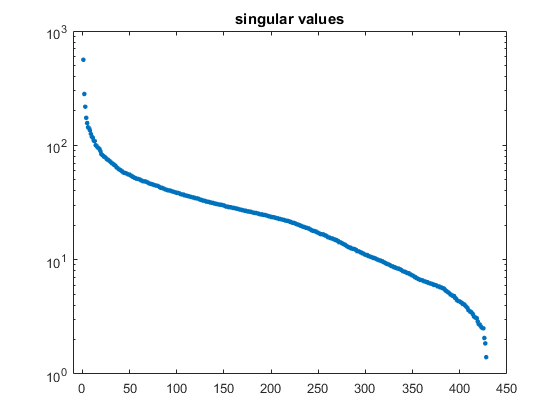
奇异值的对数图表明,他们不迅速减少。
clf semilogy(诊断接头(S),“。”,“markersize”,10)轴((-10 450 1000))标题(的奇异值)
降低等级近似
我写了一篇文章潜在语义索引一个月前。大规模集成电路采用降低等级近似文档矩阵。c ^ 5有一个滑动条选择等级。的情节奇异值表明,近似的准确性很大程度上独立于所选的值。以外的任何值非常小的值或大值附近满秩给出一个近似一至百分之十。大规模集成电路的力量并不来自近似精度。我通常把排名列数的一半。
n =大小(2);k = n / 2;英国= U (:, 1: k);Sk = S (1: k 1: k);Vk = V (:, 1: k);relerr =规范(英国* Sk * Vk - a) /年代(1,1)
relerr = 0.0357
箭头键
三个箭头键c ^ 5应用程序可以被点击鼠标向左或向右(或控件单击单键鼠标)。
- 左>:下一个文档,任何项数。
- 具有非零项数正确的>:下一个文档。
- 左<:以前的文档,任何项数。
- 对具有非零项数<:之前的文档。
- 离开^:使用查询的当前文档的根源。
- 对^:使用一个随机的查询。
反复点击向上箭头正确的按钮(一个alt点击)是一个很好的方式来浏览整个集合。
洛萨Collatz
让我们看看日志两个更多的例子。洛萨Collatz短日志。
c5Collatz

% collatz%%箭头文档项计数lsi日期%的博客/ threenplus1_blog。19 - 1月- 2015 m 9 9/19 0.904% > >博客/ collatz_inequality。m 4 13/19 0.108 16 - 3月- 2015% > >博客/ c5_blog。米5 18/19 0.075 8月28 - - 2017% > >不合格品/介绍。特克斯1 19/19 -0.003 2004
Collatz从2015年出现在两篇文章,一个在他的3 n + 1问题,一个在一个优雅的不平等,会产生惊人的图形,而在这个博客的部分c ^ 5你现在读书,他还在介绍中提到的不合格品的书,但LSI的价值很小。双箭头的每一行表示一个右键点击,跳过文件没有提到他。
21点
我写了很多关于纸牌游戏21点。
c521点
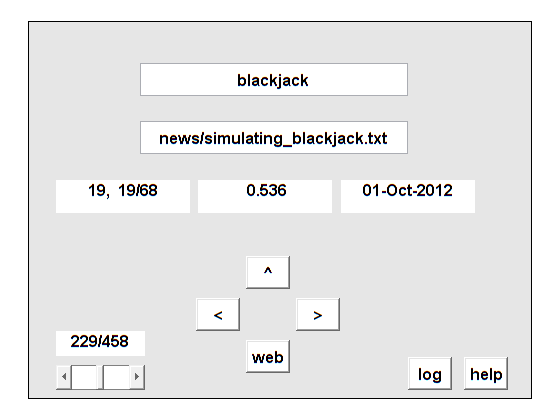
% 21点%箭头文档项计数lsi日期%新闻/ simulating_blackjack。txt 19 0.536 01 - 2012年10月,19/68% > > ncmm / ncmgui。2016 4 23/68 0.372% > >博客/ random_blog2。m 4 27/68 0.266 04 - 5 - 2015% > > ncmm /内容。2 29/68 0.244 2016% > >博客/ c5_blog。米5 34/68 0.206 8月28 - - 2017% > >不合格品/随机的。特克斯13 47/68 0.148 2004% > >实验室/ thumbnails2。2 49/68 0.088 2017% > >实验室/ lab2。0.061 m 1 50/68 2017人% > >新闻/ numerical_computing。txt 1 51/68 0.025 01 - jun - 2004% > >博客/ lab_blog。0.004 m 1 52/68 2016年- 10月31日% > > ncmm / 21点。2016 8 60/68 -0.023% > >实验室/ 21点。2017 8 68/68 -0.026
我们可以看到两个通讯列,三个博客,本章的一部分,一些代码段,和两份21点的应用程序,我用正确的点击。
Levenshtein距离
我最近写了一篇博客文章Levenshtein字符串之间的编辑距离。如果c ^ 5不承认一个查询的关键字,它使用Levenshtein距离这个词列表中找到最接近的匹配识别查询。这很容易纠正简单的拼写错误,像丢失的信件。例如失踪的“我”在纠正“polynomal”成为“多项式”。和“Levenstein”变成了“levenshtein”。
我收到了一个惊喜,当我进入“摩尔”,期望它成为“硅藻土”。相反,我得到了“极地”,因为只有一个替换需要“摩尔”转换为“极”,但两个替换要求将“摩尔”变成“硅藻土”。(Microsoft Word拼写校正用于“MATLAB”变成“肉丸”。)
多词查询
我不太清楚如何处理查询组成的多个词。什么是预期响应查询的“威尔金森多项式”,例如?它包含的文档吗要么“威尔金森”或“多项式”?这是大规模集成电路提供。但它可能是更好的寻找文档,包含这两个“威尔金森”和“多项式”。我不知道如何做到这一点。
更糟的是,我不能找两个单词的精确匹配字符串“威尔金森多项式”,因为安装程序所做的第一件事是将文本分解成单个单词。
阻止
这个项目是没有完成。如果我工作了,我要学习刮,阻止和词元化的源文本。这涉及到相对简单的任务删除所有格和复数和更复杂的任务像所有的单词结合同一根或引理。这个句子
“那只敏捷的棕色狐狸跳过了懒惰的狗回来了”
就变成了
“那只敏捷的棕色狐狸跳过lazi狗回来”
罗兰的嘉宾博客古原竹内发布了一篇文章2015年与MATLAB潜在语义分析。他引用MATLAB代码阻止。
解析查询
我可以想象做一个更好的解析查询,虽然我无法像谷歌或方法的复杂系统Siri。
限制
我所写的一个重要部分不是散文,它是数学或代码。它不能被解析的技术文本分析。例如,源文本的书不合格品和EXM数百片段的乳胶
\ {eqnarray *}开始V \方程式U \σ,\ \ U \方程式V ^ H \σ^ H。结束\ {eqnarray *}
早些时候,我在这篇文章里
抽搐(U, V) =圣言(完整的(A),“经济学”);toc
我的c5setup项目现在必须跳过这样的一切。这样做,它就会错失很多消息。
软件
我有更新克里夫的实验室包括在中央文件交换c5.m和c5database.mat。


另请参阅
-
复活节,重新审视
博客





コメント
コメントを残すには,ここをクリックしてMathWorksアカウントにサインインするか新しいMathWorksアカウントを作成します。