 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 人工智能
人工智能 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 自治系统
自治系统 定量金融学
定量金融学教一个新人教微积分深学习者
两个月前我写了一篇博客文章教微积分学深。我们写的代码在一个下午在MathWorks布斯暹罗年会。当天早些时候,在他的邀请,麻省理工学院的教授吉尔斯特朗曾自发地想知道它会可以教微积分深度学习计算机程序。我们的展位是深度学习的专家。
但MathWorks有深度学习的专家。当他们看到我的帖子,他们毫不犹豫地表明一些重大改进。特别是,康纳戴利,在我们的英国办公室MathWorks,贡献了以下文章的代码。康纳占用吉尔的挑战,开始学习的过程衍生品。
我们将使用两个不同的神经网络,一个卷积神经网络,这是通常用于图像,和复发性神经网络,通常用于声音和其他信号。
是一个导数更像一个图像或声音吗?
内容
函数及其衍生物
这里有功能和衍生品,我们会考虑。
F = {@ x (x), @ x (x)。^ 2,@ x (x)。^ 3,@ x (x)。^ 4,…@ (x)罪(π* x) @ (x), cos(π* x)};dF = {@ (x)的(大小(x)), @ x (x) 2 * @ * x (x) 3。^ 2,@ (x) 4 * x ^ 3。…@ (x)π。* cos(π。* x) @ (x) -π*罪(π* x)};Fchar = {“x”,“x ^ 2”,“x ^ 3”,“x ^ 4”,“罪(\πx)”,“因为(\πx)”};dFchar = {' 1 ',“2 x”,“3 x ^ 2”,' 4 x ^ 3 ',“\πcos (x \π)”,”——\π罪(\πx) '};
参数
设置一些参数。首先,随机数发生器的状态。
rng (0)
一个函数来生成均匀随机变量[1]。
randu = @ (m, n)(2 *兰德(m, n) 1);
一个函数来生成随机+ 1或- 1。
randsign = @()符号(randu (1,1));
函数的数量。
m =长度(F);
重复的次数,即独立的观察。
n = 500;
样本的数量区间。
nx = 100;
白噪声水平。
噪音=措施;
训练集
产生训练集的预测指标X和反应T。
X =细胞(n * m, 1);= T细胞(n * m, 1);为j = 1: n x = (randu (nx));为i = 1: m k = i + (j - 1) * m;x %预测,一个随机向量从1,1,+ / - f (x)。胡志明市= randsign ();{k} = [X;胡志明市* F{我}(x) +噪声* randn (nx)];%响应+ / - f (x)T {k} =胡志明市* dF{我}(x) +噪声* randn (nx);结束结束
区分训练集和测试集。
idxTest = ismember (1: n * m, randperm (n * m, n));XTrain = X (~ idxTest);TTrain = T (~ idxTest);XTest = X (idxTest);tt = T (idxTest);
选择一些测试指标。
它=找到(idxTest);idxM =国防部(找到(idxTest), m);idxToPlot = 0(1米);为k = 0 (m - 1): im =找到(idxM = = k);如果k = = 0 idxToPlot (m) = im (1);其他的idxToPlot (k) = im (1);结束结束
卷积神经网络(CNN)
需要格式化您所需要的数据。
[XImgTrain, TImgTrain] = iConvertDataToImage (XTrain TTrain);[XImgTest, TImgTest] = iConvertDataToImage (XTest tt);
这里是CNN层架构。请注意,“ReLU”或“修正线性单元”,我很自豪的在我以前的文章已经换成了更合适“leakyRelu”不完全切断负值。
层= […imageInputLayer ([1 nx 2],“归一化”,“没有”)convolution2dLayer ([1 5], 128,“填充”,“相同”)batchNormalizationLayer () leakyReluLayer (0.5) convolution2dLayer ([1 5], 128“填充”,“相同”)batchNormalizationLayer () leakyReluLayer (0.5) convolution2dLayer ([1 5], 1“填充”,“相同”)regressionLayer ()];
这里是CNN的选项。解算器是“个”,它代表“随机梯度下降势头”。
选择= trainingOptions (…“个”,…“MaxEpochs”30岁的…“阴谋”,“训练进步”,…“MiniBatchSize”,200,…“详细”假的,…“GradientThreshold”,1…“ValidationData”,{XImgTest, TImgTest});
火车CNN
培训网络。这需要超过3分钟在我的笔记本电脑。我没有一个GPU。
事先= trainNetwork (XImgTrain、TImgTrain层,选择);
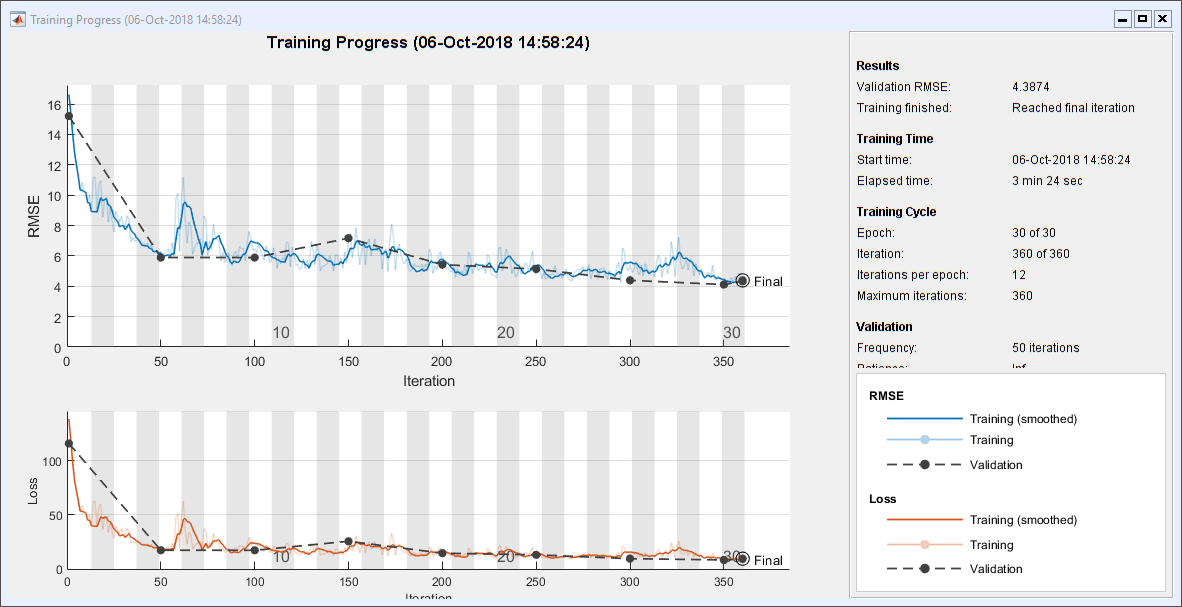
情节的测试结果
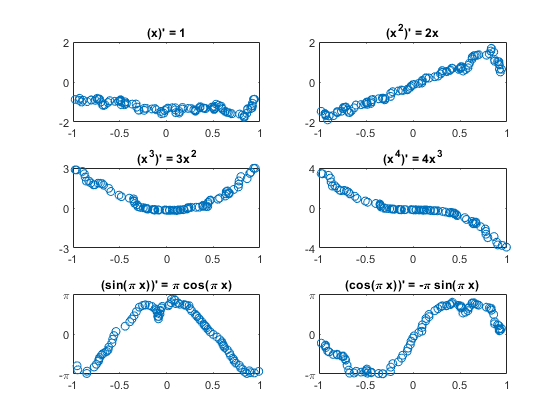
这里有块随机选择的结果。y轴上的限制将理论最大和最小。三个六块翻转迹象。
PImgTest =事先。预测(XImgTest);为k = 1: m次要情节(3 2 k);情节(XImgTest (1: 1, idxToPlot (k), TImgTest (1: 1, idxToPlot (k)),“。”)情节(XImgTest (1: 1, idxToPlot (k), PImgTest (1: 1, idxToPlot (k)),“o”)标题(“(”Fchar {k}”)= 'dFchar {k}]);开关k情况下{1,2},集(gca),“ylim”(2 - 2))情况下{3、4},集(gca),“ylim”(k - k),“ytick”(0 k - k))情况下{5、6},集(gca),“ylim”(π-π),“ytick”(π-π0),…“yticklabels”,{' - \π' 0 '“\π”})结束结束
递归神经网络(RNN)
这里有RNN的层次体系结构,包括“bilstm”代表“双向短期记忆。”
层= […sequenceInputLayer (2) bilstmLayer (128) dropoutLayer () bilstmLayer (128) fullyConnectedLayer (1) regressionLayer ()];
这是RNN选项。“亚当”不是一个缩略词;它是随机梯度下降法的扩展来自自适应估计。
选择= trainingOptions (…“亚当”,…“MaxEpochs”30岁的…“阴谋”,“训练进步”,…“MiniBatchSize”,200,…“ValidationData”{XTest, tt},…“详细”假的,…“GradientThreshold”1);
火车RNN
培训网络。这需要将近22分钟在我的机器上。这让我希望我有一个GPU。
recNet = trainNetwork (XTrain、TTrain层,选择);
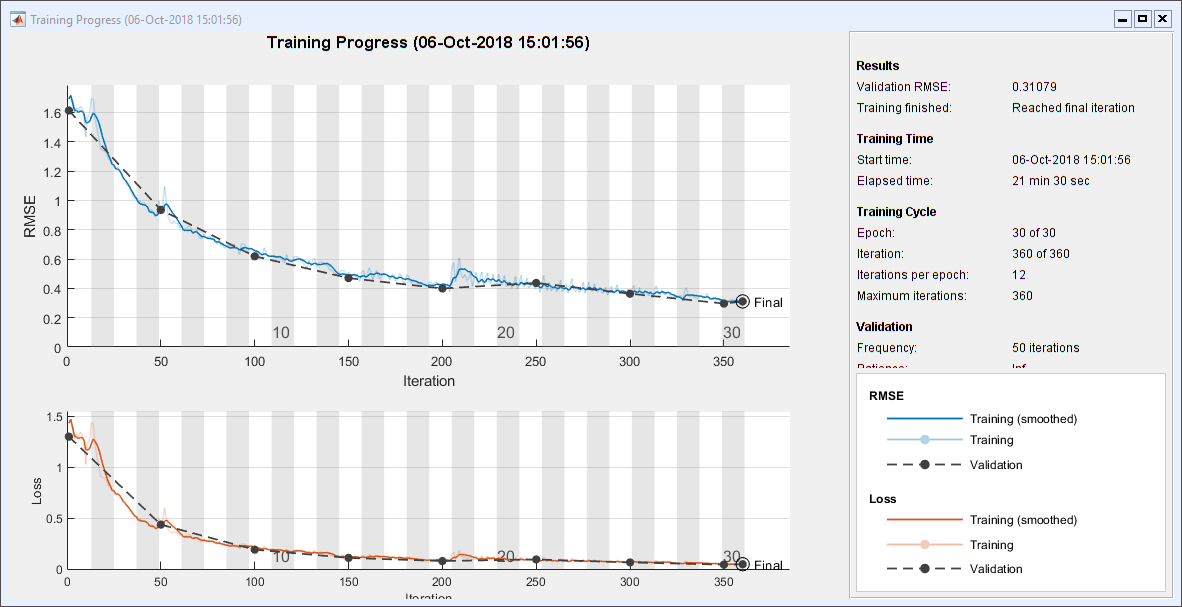
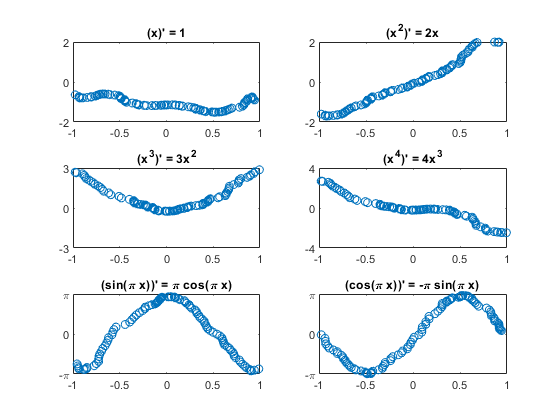
情节的测试结果
pt = recNet。预测(XTest);为k = 1: m次要情节(3 2 k);情节(XTest {idxToPlot (k)} (1:), tt {idxToPlot (k)} (1:)“。”)情节(XTest {idxToPlot (k)} (1:), pt {idxToPlot (k)} (1:)“o”)标题(“(”Fchar {k}”)= 'dFchar {k}]);开关k情况下{1,2},集(gca),“ylim”(2 - 2))情况下{3、4},集(gca),“ylim”(k - k),“ytick”(0 k - k))情况下{5、6},集(gca),“ylim”(π-π),“ytick”(π-π0),…“yticklabels”,{' - \π' 0 '“\π”})结束结束
将数据转换为CNN格式
函数[XImg, TImg] = iConvertDataToImage (X, T)%将数据转换为CNN格式%为CNN需要格式化您所需要数据XImg =猫(4 X {:});XImg =排列(XImg [3 2 1 4]);TImg =猫(4 T {:});TImg =排列(TImg [3 2 1 4]);结束
结论
我曾经教微积分。我一直批评有时教微积分和更多的方式学习。这是一个典型的场景。
教练:x ^ 4美元的导数是什么?
学生:4 x ^ 3美元。
教练:为什么?
学生:你4美元,把它放在前面,然后减去3美元一个,把它的4美元。
我怕我们这样做。学习者只是寻找模式。是没有意义的速度,加速度,或变动率。微分表达式几乎是不可能的,不是在训练集,没有乘法法则,没有链式法则,没有微积分基本定理。
简而言之,几乎没有理解。但也许这是一个机器学习的批评。








댓글
댓글을남기려면링크를클릭하여MathWorks계정에로그인하거나계정을새로만드십시오。