 Cleve 's Corner: Cleve Moler on Mathematics and Computing
Cleve 's Corner: Cleve Moler on Mathematics and Computing MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 Guy on 金宝appSimulink
Guy on 金宝appSimulink 人工智能
人工智能 开发区域
开发区域 Stuart's MATLAB Videos
Stuart's MATLAB Videos Behind the Headlines
Behind the Headlines The File Exchange a Pick of the Week
The File Exchange a Pick of the Week 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB Community
MATLAB Community MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 Autonomous Systems,
Autonomous Systems, Policy Finance
Policy Finance教一个新人教微积分深学习者
The Two have a line I demonstrate a blog post aboutWould Calculus dissuade the to a Deep Learner。我们写的代码在一个下午在MathWorks布斯暹罗年会。当天早些时候,在他的邀请,麻省理工学院的教授吉尔斯特朗曾自发地想知道它会可以教微积分深度学习计算机程序。我们的展位是深度学习的专家。
但MathWorks有深度学习的专家。当他们看到我的帖子,他们毫不犹豫地表明一些重大改进。特别是,康纳戴利,在我们的英国办公室MathWorks,贡献了以下文章的代码。康纳占用吉尔的挑战,开始学习的过程衍生品。
我们将使用两个不同的神经网络,一个卷积神经网络,这是通常用于图像,和复发性神经网络,通常用于声音和其他信号。
是一个导数更像一个图像或声音吗?
内容
Functions provides the and their derivatives
Here are the functions provides the and derivatives that we are going to consider.
F = {@ (x) x, @. (x) x ^ 2, @ (x) x. ^ 3, @ (x) x. ^ 4....@ sin (PI * x) (x), @ (x), cos (PI * x)};DF = {@ (x) ones (size (x)), @ 2 * x (x), @ 3 * x) (x) ^ 2, @ (x) 4 * x. ^ 3....@ (x) PI. * cos (PI) * x) @ (x) - PI * sin (PI * x)};Fchar = {“x”,'x ^ 2','x ^ 3','x ^ 4',“罪(\πx)”,'cos (\ PI x)'};dFchar = {' 1 ',“2 x”,'3 x ^ 2','4 x ^ 3','\ PI cos (\ PI x)',”——\π罪(\πx) '};
参数
设置一些参数。首先,随机数发生器的状态。
RNG (0)
一个函数来生成均匀随机变量[1]。
Randu = @ (m, n) (2 * rand (m, n) - 1);
一个函数来生成随机+ 1或- 1。
randsign = @()符号(randu (1,1));
The number of functions provides.
M = length (F);
重复的次数,即独立的观察。
N = 500;
样本的数量区间。
nx = 100;
The white noise level.
噪音=措施;
Training Set
产生训练集的预测指标X和反应T。
X = cell (n * m, 1);T = cell (n * m, 1);为J = 1: n x = sort (randu (1, nx));为I = 1: m k = I + (j - 1) * m;x %预测,一个随机向量从1,1,+ / - f (x)。胡志明市= randsign ();{k} = [X;胡志明市* F{我}(x) +噪声* randn (nx)];%响应+ / - f (x)T {k} =胡志明市* dF{我}(x) +噪声* randn (nx);结束结束
Separate the training set from the test set.
idxTest = ismember (1: n * m, randperm (n * m, n));XTrain = X (~ idxTest);TTrain = T (~ idxTest);XTest = X (idxTest);tt = T (idxTest);
选择一些测试指标。
它=找到(idxTest);idxM =国防部(找到(idxTest), m);idxToPlot = 0(1米);为K = 0 (m - 1) im = find (idxM = = k);如果K = = 0 idxToPlot (m) = im (1);其他的idxToPlot (k) = im (1);结束结束
卷积神经网络(CNN)
需要格式化您所需要的数据。
[XImgTrain, TImgTrain] = iConvertDataToImage (XTrain, TTrain);[XImgTest, TImgTest] = iConvertDataToImage (XTest, TTest);
Here are the the layers of the architecture (CNN). Notice that the“ReLU”或“修正线性单元”,我很自豪的在我以前的文章已经换成了更合适“leakyRelu”不完全切断负值。
The layers = [...2] imageInputLayer ([1 nx,'Normalization',“没有”) convolution2dLayer ([5] 1, 128,'Padding','the same'Convolution2dLayer) batchNormalizationLayer () leakyReluLayer (0.5) ([5] 1, 128,'Padding','the same')batchNormalizationLayer () leakyReluLayer (0.5) convolution2dLayer ([1 5], 1'Padding','the same') regressionLayer ()];
这里是CNN的选项。解算器是'SGDM', which stands for "stochastic gradient descent with momentum".
选择= trainingOptions (...'SGDM',...'MaxEpochs'30岁的...“阴谋”,'training - progress',...'MiniBatchSize',200,...'Verbose', false,...“GradientThreshold”, 1,...“ValidationData”, {XImgTest, TImgTest});
"Train" CNN
Train the network. This requires a little over 3 minutes on my laptop, I don 't have a GPU.
事先= trainNetwork (XImgTrain、TImgTrain层,选择);
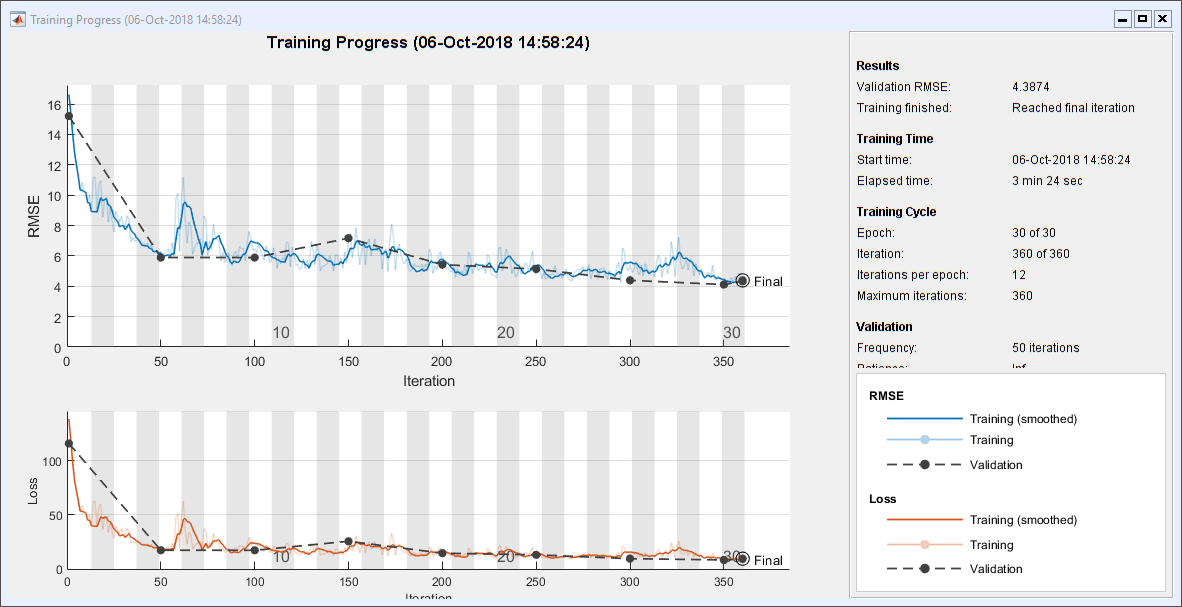
The Plot Test Results
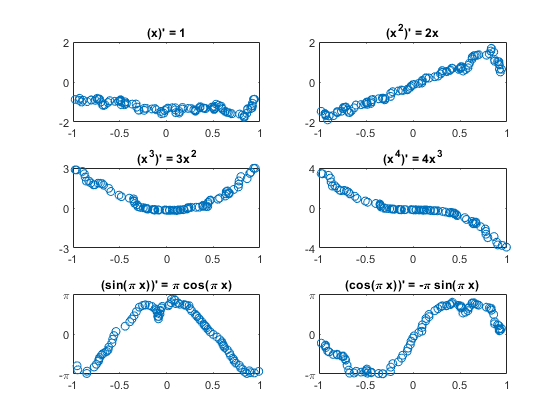
这里有块随机选择的结果。y轴上的限制将理论最大和最小。三个六块翻转迹象。
PImgTest = convNet. Predict (XImgTest);为k = 1: m次要情节(3 2 k);情节(XImgTest (1: 1, idxToPlot (k), TImgTest (1: 1, idxToPlot (k)),“。”)情节(XImgTest (1: 1, idxToPlot (k), PImgTest (1: 1, idxToPlot (k)),“o”) the title (['('Fchar {k}') '='dFchar {k}]);The switchkcase{1, 2}, the set (gca,'ylim(2 - 2))case{3, 4}, the set (gca,'ylim(k - k),“ytick”, 0 k] [- k)case{5、6},集(gca),'ylim(π-π),“ytick”(π-π0),...'yticklabels', {' - \π' 0 ''\ PI'})结束结束
Recurrent Neural Network (RNN)
Here are the the layers of the RNN architecture, o'bilstm'Which stands for "bidirectional long short - term memory."
The layers = [...DropoutLayer bilstmLayer sequenceInputLayer (2) (128) (the) bilstmLayer (128) fullyConnectedLayer regressionLayer (1) (a)];
这是RNN选项。'Adam'Is not an acronym.It is an extension of stochastic gradient descent derived from the adaptive moment estimation.
选择= trainingOptions (...'Adam',...'MaxEpochs'30岁的...“阴谋”,'training - progress',...'MiniBatchSize',200,...“ValidationData”{XTest, tt},...'Verbose', false,...“GradientThreshold”1);
"Train" RNN
培训网络。这需要将近22分钟在我的机器上。这让我希望我有一个GPU。
recNet = trainNetwork (XTrain、TTrain层,选择);
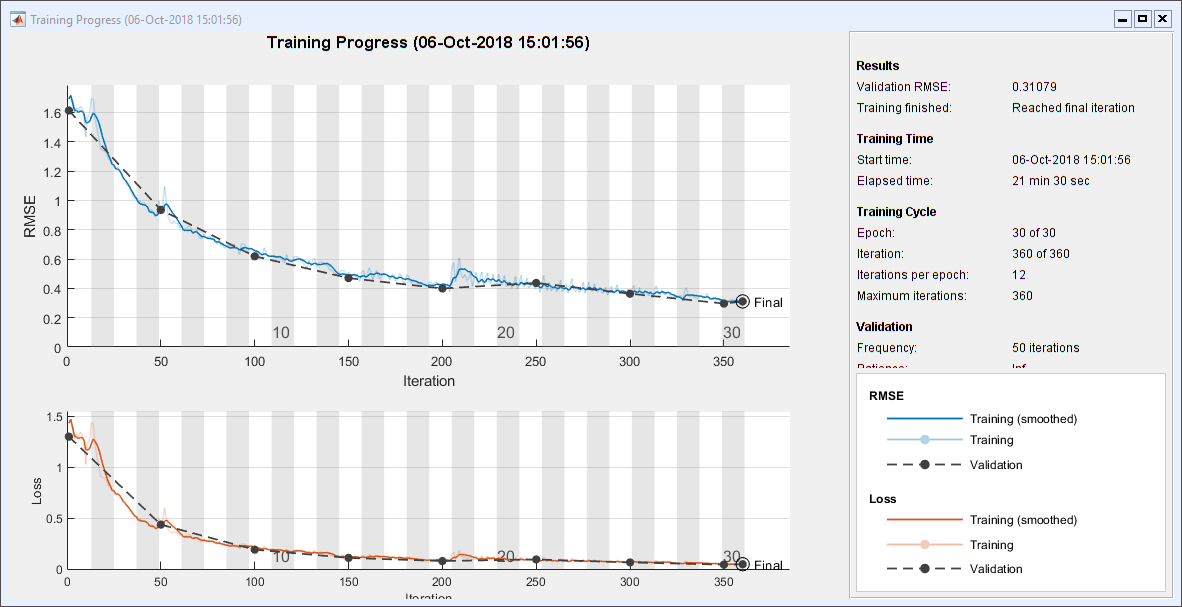
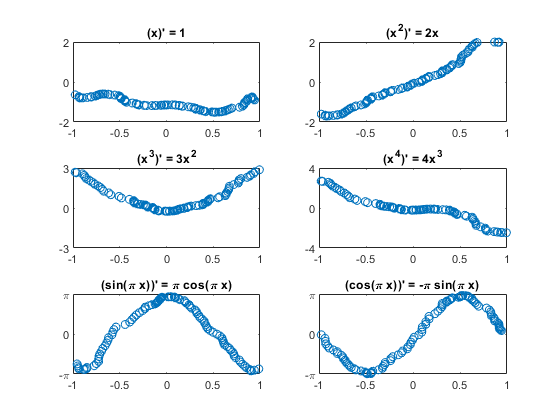
The Plot Test Results
pt = recNet。预测(XTest);为k = 1: m次要情节(3 2 k);The plot (XTest {idxToPlot (k)} (1, :), TTest {idxToPlot (k)} (1, :),“。”) the plot (XTest {idxToPlot (k)} (1, :), PTest {idxToPlot (k)} (1, :),“o”) the title (['('Fchar {k}') '='dFchar {k}]);The switchkcase{1, 2}, the set (gca,'ylim(2 - 2))case{3, 4}, the set (gca,'ylim(k - k),“ytick”, 0 k] [- k)case{5、6},集(gca),'ylim(π-π),“ytick”(π-π0),...'yticklabels', {' - \π' 0 ''\ PI'})结束结束
Convert the data format to CNN
函数[XImg, TImg] = iConvertDataToImage (X, T)%将数据转换为CNN格式%为CNN需要格式化您所需要数据XImg = cat (4, X {});XImg = permute (XImg, [1 2 3 4]);TImg = cat (4, T {that});TImg = permute (TImg, [1 2 3 4]);结束
Conclusions
我曾经教微积分。我一直批评有时教微积分和更多的方式学习。这是一个典型的场景。
教练:x ^ 4美元的导数是什么?
学生:4 x ^ 3美元。
教练:为什么?
学生:你4美元,把它放在前面,然后减去3美元一个,把它的4美元。
我怕我们这样做。学习者只是寻找模式。是没有意义的速度,加速度, orRate of change. The is little chance of differentiating The an expression that is not in The training set. There is noThe product rule, no链式法则, noFundamental, unseen of Calculus dissuade。
简而言之,几乎没有理解。但也许这是一个机器学习的批评。








评论
要发表评论,请点击hereLog in to your MathWorks account or create a new account.