 克莱夫之角:克莱夫·莫勒谈数学与计算
克莱夫之角:克莱夫·莫勒谈数学与计算 MATLAB博客
MATLAB博客 史蒂夫的图像处理与MATLAB
史蒂夫的图像处理与MATLAB Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条背后
头条背后 文件交换选择的一周
文件交换选择的一周 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlab
Matlab 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统教新手如何教深度学习者微积分
两个月前,我写了一篇关于向深度学习者教授微积分。我们在SIAM年会的MathWorks展位上花了一个下午的时间编写了这篇文章的代码。那天早些时候,麻省理工学院的吉尔·斯特朗(Gil Strang)教授在受邀演讲时,不由自主地想知道是否有可能向深度学习计算机程序教授微积分。我们在座的人都不是深度学习方面的专家。
但MathWorks确实有深度学习方面的专家。当他们看到我的帖子时,他们毫不犹豫地提出了一些重要的改进建议。特别值得一提的是,我们MathWorks英国办公室的Conor Daly为下面这篇文章贡献了代码。康纳接受了吉尔的挑战,开始了学习衍生品的过程。
我们将使用两种不同的神经网络,一种是卷积神经网络,它通常用于图像,另一种是循环神经网络,它通常用于声音和其他信号。
衍生品更像图像还是声音?
内容
函数及其导数
这是我们要考虑的函数和导数。
F = {@(x) x, @(x) x ^2, @(x) x ^3, @(x) x ^4,…@(x) sin(*x), @(x) cos(*x)};dF = {@(x) ones(size(x)), @(x) 2*x, @(x) 3*x。^2, @(x) 4*x ^3,…@(x) *cos(*x), @(x) - *sin(*x)};Fchar = {“x”,“x ^ 2”,“x ^ 3”,“x ^ 4”,“罪(\πx)”,“因为(\πx)”};dFchar = {' 1 ',“2 x”,“3 x ^ 2”,' 4 x ^ 3 ','\ cos(\pi x)','-\pi sin(\pi x)'};
参数
设置一些参数。首先,随机数生成器状态。
rng (0)
在[- 1,1]上生成均匀随机变量的函数。
Randu = @(m,n) (2*rand(m,n)-1);
生成随机+1或-1的函数。
Randsign = @() sign(randu(1,1));
函数的数量。
m =长度(F);
重复的次数,即独立观察。
N = 500;
区间内的样本数。
Nx = 100;
白噪音水平。
噪声= .001;
训练集
生成训练集预测器X以及他们的反应T。
X = cell(n*m, 1);T = cell(n*m, 1);为J = 1:n = sort(randu(1, nx));为I = 1:m k = I + (j-1)*m;%预测因子是x,它是-1、1和+/- f(x)中的随机向量。SGN = randsign();X{k} = [X;胡志明市* F{我}(x) +噪声* randn (nx)];%响应是+/- f'(x)T{k} = sgn*dF{i}(x)+noise*randn(1,nx);结束结束
将训练集与测试集分开。
idxTest = ismember(1:n*m, randperm, n));XTrain = X(~idxTest);TTrain = T(~idxTest);XTest = X(idxTest);test = T(idxTest);
选择一些测试指标进行绘图。
ittest = find(idxTest);idxM = mod(find(idxTest), m);idxToPlot = 0 (1, m);为k = 0:(m-1) m = find(idxM == k);如果k == 0 idxToPlot(m) = im(1)其他的idxToPlot(k) = im(1);结束结束
卷积神经网络(CNN)
为CNN重新格式化数据。
[xgtrain, TImgTrain] = iConvertDataToImage(XTrain, TTrain);[XTest, TImgTest] = iConvertDataToImage(XTest, TTest);
下面是CNN的架构层。注意“ReLU”,或“整流线性单元”,我在我以前的帖子中引以为傲的已经被更合适的取代了“leakyRelu”,它不会完全切断负值。
图层= […imageInputLayer([1 nx 2],“归一化”,“没有”)卷积2dlayer ([15], 128,“填充”,“相同”) batchNormalizationLayer() leakyReluLayer(0.5) convolution2dLayer([15], 128,“填充”,“相同”) batchNormalizationLayer() leakyReluLayer(0.5) convolution2dLayer([15], 1,“填充”,“相同”) regressionLayer()];
以下是CNN的选项。求解器是“个”,即“随机动量梯度下降”。
options = trainingOptions(…“个”,…“MaxEpochs”30岁的…“阴谋”,“训练进步”,…“MiniBatchSize”, 200,…“详细”假的,…“GradientThreshold”, 1,…“ValidationData”, {XImgTest, TImgTest});
火车CNN
训练网络。这在我的笔记本电脑上需要3分钟多一点。我没有GPU。
convNet = trainNetwork(XImgTrain, TImgTrain, layers, options);
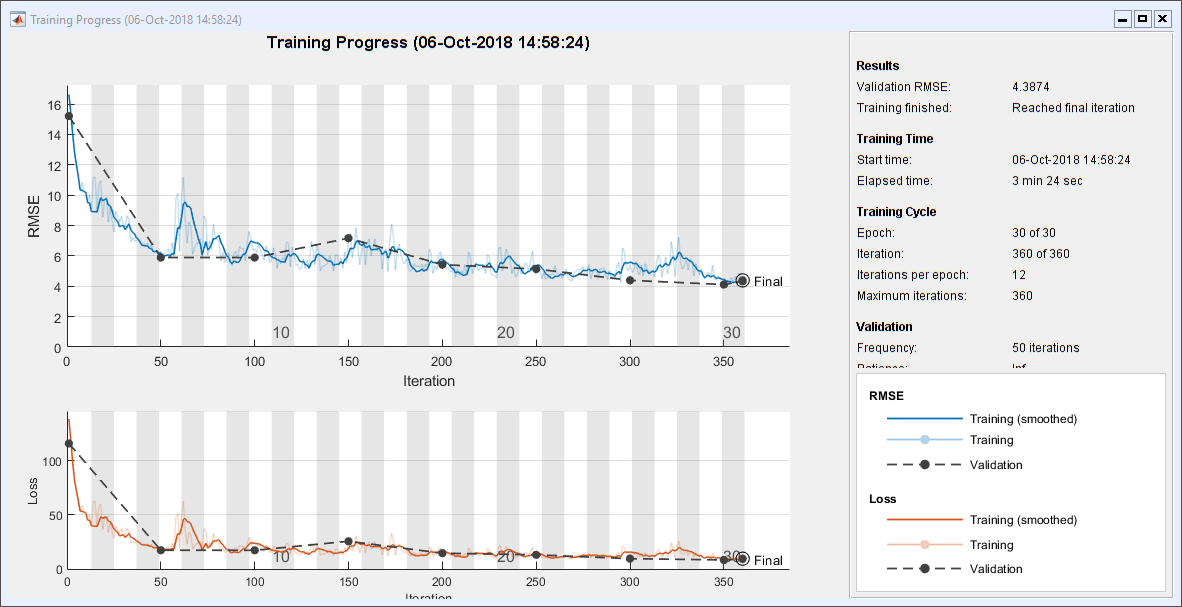
小区试验结果
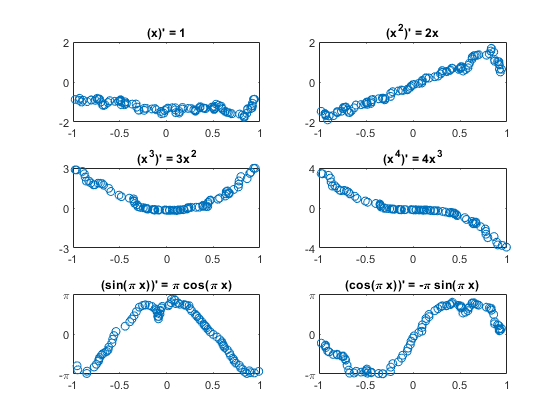
这里是随机选择的结果图。y轴上的限制设置为理论最大值和最小值。六个图中有三个的符号颠倒了。
PImgTest = convNet。预测(XImgTest);为K = 1:m subplot(3,2, K);plot(XImgTest(1,:, 1, idxToPlot(k)), TImgTest(1,:, 1, idxToPlot(k)),“。”) plot(XImgTest(1,:, 1, idxToPlot(k)), PImgTest(1,:, 1, idxToPlot(k)),“o”)标题(“(”Fchar {k}') " = 'dFchar{k}]);开关k情况下{1,2},集(gca),“ylim”(2 - 2))情况下{3、4},集(gca),“ylim”(k - k),“ytick”,[-k 0 k])情况下{5、6},集(gca),“ylim”(π-π),“ytick”,[- 0],…“yticklabels”, {' - \π' 0 '“\π”})结束结束
循环神经网络(RNN)
下面是RNN架构的层,包括“bilstm”意思是"双向长短期记忆"
图层= […sequenceInputLayer(2) bilstmLayer(128) dropoutLayer() bilstmLayer(128) fulllyconnectedlayer (1) regressionLayer()];
以下是RNN选项。“亚当”不是首字母缩写;它是由自适应矩估计导出的随机梯度下降的扩展。
options = trainingOptions(…“亚当”,…“MaxEpochs”30岁的…“阴谋”,“训练进步”,…“MiniBatchSize”, 200,…“ValidationData”, {XTest, TTest};…“详细”假的,…“GradientThreshold”1);
火车RNN
训练网络。这在我的机器上花了差不多22分钟。它让我希望我有一个图形处理器。
recNet = trainNetwork(XTrain, TTrain, layers, options);
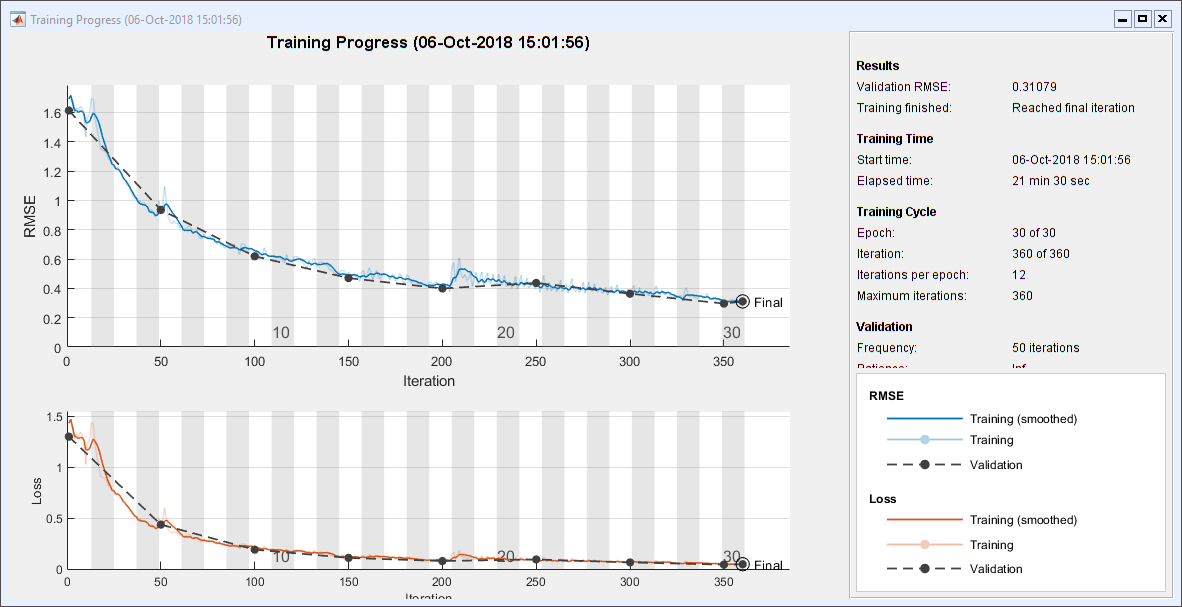
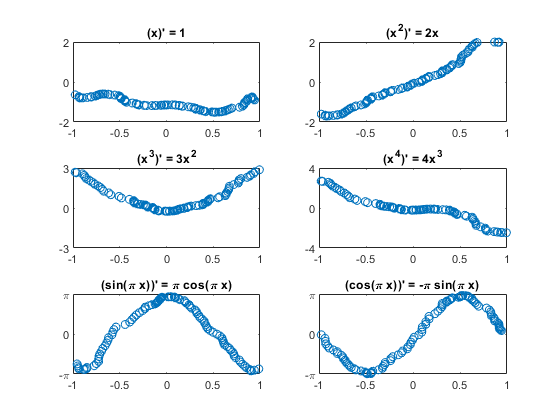
小区试验结果
PTest = recNet。预测(XTest);为K = 1:m subplot(3,2, K);情节(XTest {idxToPlot (k)} (1:), tt {idxToPlot (k)} (1:)“。”)情节(XTest {idxToPlot (k)} (1:), pt {idxToPlot (k)} (1:)“o”)标题(“(”Fchar {k}') " = 'dFchar{k}]);开关k情况下{1,2},集(gca),“ylim”(2 - 2))情况下{3、4},集(gca),“ylim”(k - k),“ytick”,[-k 0 k])情况下{5、6},集(gca),“ylim”(π-π),“ytick”,[- 0],…“yticklabels”, {' - \π' 0 '“\π”})结束结束
将数据转换为CNN格式
函数[xig, TImg] = iConvertDataToImage(X, T)%将数据转换为CNN格式%为CNN重新格式化数据xm = cat(4, X{:});xm = permute(xm, [3 2 1 4]);TImg = cat(4, T{:});TImg = permute(TImg, [3 2 1 4]);结束
结论
我以前教微积分。我一直对微积分的教学方式持批评态度。下面是一个典型的场景。
教练x^4的导数是什么?
学生: 4 x ^ 3美元。
教练:为什么?
学生你把4美元放在前面,然后减去1得到3美元,然后把它放在4美元的位置上。
恐怕我们就在这里。学习者只是在寻找模式。没有感觉速度,加速度,或变化率。微分不在训练集中的表达式的机会很小。没有乘法法则,没有链式法则,没有微积分基本定理。
简而言之,几乎没有理解。但也许这是对机器学习的一种批评。


另请参阅
-

向深度学习者教授微积分
博客
-

DFT和DTFT
博客





评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。