以下是来自Mohammad Muquit的一篇客座文章,讨论如何实现多阶建模来提高深度学习模型的准确性。
在典型的分类问题中,深度神经网络(DNN)的准确性是通过对地面事实的正确分类预测的百分比来衡量的。然而,DNN的最后一层不仅包含类名,还包含DNN中每个类的概率密度数组。因此,典型的方法可能会忽略大量的输出数据。
在这个博客中,我们使用这个想法
概率密度的数组本身可以作为一组预测器进行额外建模,并研究在哪些情况下可以利用这些丢失的信息来提高DNN的准确性。
图1所示。显示所提议方法背后的基本思想。

我们在这里介绍一个质量保证(QA)应用程序作为示例。
对于将要被检查的给定样品产品,该样品的多个图像被用作输入。图像是通过在QA成像系统前旋转样品产品来捕获的,每个样品捕获60张图像。在本案例研究中,总共使用了135个独特的样品,其中55个样品有一些缺陷,其余80个样品是正常的。我们将这些数据分为培训和测试数据如下:
|
训练数据 |
测试数据 |
| 正常的样品: |
57 |
23 |
| 叛逃的样本: |
43 |
12 |
| 总独特的样品: |
One hundred. |
35 |
| 总图像: |
6000 |
2100 |
首先使用GoogleNet进行迁移学习的训练图像生成DNN。2100张测试图像的总体准确率为67.43%,其中
正常的和
叛逃图像分别为67.05%和87.18%。尽管它能以更高的准确率识别单个缺陷图像,但在近三分之一的情况下无法识别正常图像。
注意,这些结果仅在单个图像到类的级别,但我们每个样本有60张图像。即使这60个预测结果的准确性非常低
单独,将它们整理在一起以获得额外的模型(如图2所示)可能会获得非常高的准确性,我们将在下一节中探讨这一点。

图2:将同一样本的图像整理在一起,形成一个很长的预测器数组,作为第二个模型的输入。这个图显示了……的想法二阶模型,但请注意,这可以进一步扩展到多顺序建模。
多阶建模方法
我将介绍4种从最简单到最复杂的多阶建模方法,所有这些方法都提高了从单个图像到类的原始精度。重现这些实验和绘图的代码可在
文件交换
天真的方法
我们设定了一个规则,如果
N在60张图像中,预测有缺陷的,那么样本将被称为缺陷。图3显示了Normal和defect的精度水平随n值的变化而变化。图4显示了ROC曲线。
负载ReadyVariables。mat numImg = width(TrainDataTable)-1;dfctIndx = TestProdLabels = =“叛逃”;nrIndx = ~ dfctIndx;Nnr =总和(nrIndx);Ndf =总和(dfctIndx);SA = sum(table2array(TestDataTable) <= 0.5,2);nAcr = 0 (numImg, 1);dAcr = 0 (numImg, 1);for k = 1:numImg rslt = SA >= k;ddr (k) = sum(rslt == 1 & dfctIndx == 1)/Ndf;ncr (k) = sum(rslt == 0 & nrIndx == 1)/Nnr;结束
由Fig3中两条精度曲线的重合可以看出,当N为17或18时,可以检测到Normal和defect样本,准确率分别低至4.35%和8.33%。我们知道,这种方法对单个图像的预测精度非常低的模型的输出并不是有效的。

作为机器学习预测器的正常-缺陷模式
在第二种方法中,我们只使用所有60幅图像的类别预测来训练第二种模型。因此,对于每个单独的样本,我们创建一个1 x 60的二进制值数组,即,赋值为1或0(即,
正常:1或
叛逃:0).我们为训练样本创建数组,训练模型,然后为测试样本创建数组来评估模型。结果表明,该方法的精度提高到90%以上。而不是只看0或1的个数,而是看0或1在数组中的排列方式在求导样本时更有效。
DiscTestDataTable = double(table2array(TestDataTable(:,1:end)) > 0.5);array2table(DiscTestDataTable);%数组到表的转换
对于测试和训练数据,如果数据正常则设为1,如果数据有缺陷则设为0。这是由原始概率密度表中大于0.5的数据表示的。
所以使用测试数据中的第一个样本,转换看起来像这样:
测试样本1,图像1-20:
| 0.841 |
0.457 |
0.685 |
0.137 |
0.983 |
0.808 |
0.904 |
0.928 |
0.979 |
0.796 |
0.988 |
0.285 |
0.976 |
0.542 |
0.411 |
0.235 |
0.912 |
0.287 |
0.614 |
0.484 |
阈值为0.5的测试样本1:
| 1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
我们训练了一个机器学习分类器来识别0和1的模式来区分正常和有缺陷的样本。
bTM = trainClassifier (DiscTrainDataTable numImg);英国石油(bP) = bTM.predictFcn (DiscTestDataTable);bAcc = 100 * (bP = = TestProdLabels) /元素个数之和(bP);disp([' threshold Data Accuracy:', num2str(bAcc),'%'])
阈值数据准确性:91.4286%
概率分布值作为机器学习的预测器
在前面的方法中,不能保证0.5是将预测器划分为两个不同类的最佳值。因此,使用概率密度值本身(一个连续值)作为预测器可能是下一步改进的步骤。我们训练和评估模型,如下面的代码所示。由于减少了信息损失,我们看到该方法的准确率(97.14%)较前一种方法(91.43%)有了很好的提高。
%使用连续模式建模为%关于测试数据的预测(Sample-to-Class level Prediction) acc = 100*sum(P==TestProdLabels)/numel(P);disp([正常数据的准确性:,num2str (acc), ' % '])
训练LSTM神经网络
最后还有一个点,即对60幅图像以时间序列的方式获取的60个概率密度值之间的相干性。这个想法是:对于一个给定的缺陷样本,缺陷应该在60张图像中的一些图像上可见。因此,对于此类缺陷样本,表示缺陷条件的概率密度值应该是一串的。而对于一个给定的Normal样本,即使错误地出现了某个表示有缺陷的概率密度值,也应该是由于噪声或其他因素而随机出现的。
在本节中,我们使用概率密度数据来训练LSTM神经网络,并评估其准确性。这次用100个epoch训练的神经网络准确率达到100%。
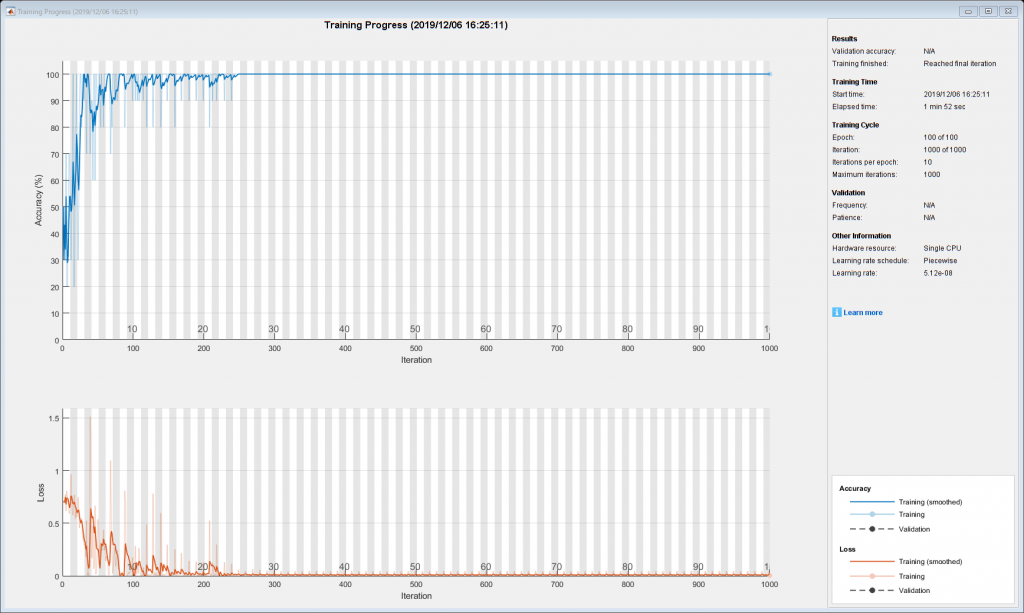
%%对LSTM网络的评估PL= classify(net,tstLstm);%对测试数据的预测lAcc = 100*sum(PL==TestProdLabels)/numel(PL);%计算准确率(['LSTM accuracy:',num2str(lAcc),'%'])
LSTM精度:100%
最后的评论
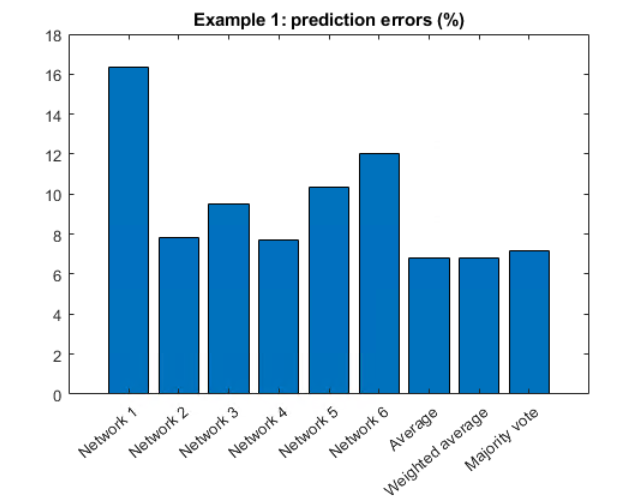
在这篇博客中,我们展示了将神经网络的输出数据解释为单个决策的一般方法可能不是获得最佳结果的最佳实践。我们所介绍的方法表明,使用精度很低的先验深度神经网络(DNN)的输出进行多阶建模,最终可以在实际应用中获得较高的精度。
我们还介绍了不同的多阶建模方法,以表明使用概率分布值代替预测类有助于获得更好的精度。此外,对于以时间序列方式获取输入图像的情况,基于LSTM的方法可能会进一步有助于提高精度。
完整的代码可在这里:
//www.tatmou.com/matlabcentral/fileexchange/79092-multiple-order-modeling-for-deep-learning
对穆罕默德有什么意见或问题吗?请在下方留言。
 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 我们在这里介绍一个质量保证(QA)应用程序作为示例。对于将要被检查的给定样品产品,该样品的多个图像被用作输入。图像是通过在QA成像系统前旋转样品产品来捕获的,每个样品捕获60张图像。在本案例研究中,总共使用了135个独特的样品,其中55个样品有一些缺陷,其余80个样品是正常的。我们将这些数据分为培训和测试数据如下:
我们在这里介绍一个质量保证(QA)应用程序作为示例。对于将要被检查的给定样品产品,该样品的多个图像被用作输入。图像是通过在QA成像系统前旋转样品产品来捕获的,每个样品捕获60张图像。在本案例研究中,总共使用了135个独特的样品,其中55个样品有一些缺陷,其余80个样品是正常的。我们将这些数据分为培训和测试数据如下:









评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。