 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 Loren在Matlab的艺术上
Loren在Matlab的艺术上 史蒂夫在图像处理与matlab
史蒂夫在图像处理与matlab 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创公司,加速器和企业家
初创公司,加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー
先进的阿尔茨海默氏症研究与失速捕手- MATLAB基准代码
今天的博客由Neha Goel撰写,他是MathWorks学生竞赛团队的深度学习技术布道者。
你好!我们MathWorks与DrivenData合作,很高兴为您带来这一挑战。通过这个挑战,你可以帮助找到在未来一到两年内可以达到的治疗阿尔茨海默病的目标。你还可以获得使用老鼠大脑的实时视频数据集的真实体验。我们还鼓励您使用MATLAB通过提供免费的MATLAB许可证来训练您的模型。
这一挑战的目的是将概述的血管分段分类为
- “流动”——如果血液在血管中流动
- 如果船只没有血液,则“停滞不前”。
解决这一挑战的主要资产是视频本身!每个视频都由其识别文件名,这是一个数字字符串,后跟.mp4,例如,100000. mp4.所有的视频都存放在一个公共的s3桶中。
完整的培训数据集包含超过580,000个视频,该视频约为1.5 Terabytes!为了帮助促进更快的模型原型设计,数据集有两个子集版本,称为n另和微。
除了视频外,您还可以观看“train_metadata.csv.”和“test_metadata.csv”文件。这些文件包括文件名、每个文件的URL、每个视频的帧数、纳米和微子集指示。“train_labels.csv是训练数据的标签文件。
有关数据集的详细信息,请查看问题描述在竞争网页上。

Matlab入门
我们在MATLAB上提供了一个基本的基准测试启动代码纳米DataSet的子集版本。在此代码中,我们通过基本的分类模型,在那里我们结合了预先训练的图像分类模型和LSTM网络。然后,我们将使用此模型预测测试数据上的船只的类型,并以挑战所需的格式保存CSV文件。你也可以在此处下载此MATLAB基准代码。
这可以作为基本代码,您可以在其中开始分析数据,并使用更多可用的培训数据来开发更有效,优化和准确的模型。此外,我们提供了一些在完整的1.5TB数据集上工作的提示和技巧。关于挑战问题描述页面,提供视频,标签性能和提交指标的所有必需细节。
所以,让我们开始使用这个数据集!
负载培训数据
从文件中访问变量值train_metadata.csv.,加载文件的形式tabulartext数据存储在工作区中。
ttds = tabulartextdataStore(“train_metadata.csv”,“readsize”,'file',“texttype”,“string”);火车=读(TTD);
然后我们可以预览数据存储。这将可视化文件的前8行。
预览(运输大亨)

您还可以在MATLAB中导入csv文件使用可阅读函数。在这里,我们从train_labels.csv文件并以表格的表格存储。然后,我们将停滞的变量的值转换为分类,因为大多数深度倾斜函数使用接受分类值。
TrainLabels = Readtable(“train_labels.csv”);trainlabels.stalled =分类(trainlabels.stalled);
在此启动器代码中,我们将使用数据库的Nano子集。在这里,我们从上面创建的表中检索纳米子集的文件和标签,并将其保存在变量中nanotrain和nanotrainlabels.(要使用完整的数据集,您将不需要这个步骤。)
nanotrain =火车(火车。纳米= =‘真正的’,:);nanotrainlabels = trainlabels(火车。纳米= =‘真正的’,:);
访问和处理视频文件
MATLAB的数据存储是一种方便的方式和代表一个太大而无法一次适合内存的数据的集合。它是读取单个文件或文件或数据集合的对象。数据存储器充当具有相同结构和格式化的数据的存储库。要了解有关不同数据存储的更多信息,请查看以下文件:
在这篇博客那我们使用了filedatastore.使用其URL读取每个文件。然后使用每个文件使用readvideo.辅助函数,在本博客的最后定义。
我们将数据存储保存在一个mat文件中tempdir或当前文件夹,然后继续下一节。如果MAT文件已经存在,则从MAT文件加载数据存储,而不重新评估它们。
tempfds = fullfile (tempdir fds_nano.mat);if exist(tempfds,'file') load(tempfds,'fds') else fds = fileDatastore(nanotrain. txt . txt);url, ReadFcn, @readVideo);文件= fds.Files;保存(tempfds fds);结尾
提示:使用完整的数据集(〜1.5tb)那使用培训数据的文件夹位置创建数据存储('S3:// Drivendata-竞争 - 丢失/火车'),而不是每个urlURL.节省时间和记忆。这个步骤可能需要很长时间来运行。
(可选)我们可以预览数据存储,并确保每个视频帧现在被裁剪在概述段。
dataout =预览(fds);瓷砖= inmtile(dataout);imshow(瓷砖);

分类
创建视频分类深度学习网络:
- 使用预先训练的卷积神经网络(如GoogLeNet)将视频转换为特征向量序列,从每一帧中提取特征。
- 培养一个短期内记忆(LSTM)网络上的网络预测视频标签。
- 组装一个网络,通过合并来自两个网络的层直接对视频进行分类。
下图说明了网络架构。
- 要向网络输入图像序列,使用序列输入层。
- 使用卷积层提取特征,即对视频的每一帧单独进行卷积操作,先使用序列折叠层,再使用卷积层。
- 为了恢复序列结构并将输出重塑为向量序列,请使用序列展开层和平坦层。
- 为了对所得到的矢量序列进行分类,包括LSTM层,然后包括输出层。

负载预训练卷积网络
为了将视频帧转换为特征向量,我们使用了预先训练的网络的激活。加载一个预先训练的GoogLeNet模型使用googlenet函数。此功能需要深度学习工具箱™模型为了google网络支持包金宝app.
netCNN = googlenet;
将帧转换为特征向量
通过在将视频帧输入到网络时,使用卷积网络作为特征提取器。
该图说明了通过网络的数据流。

输入大小应该与预先训练的网络的输入大小匹配,这里是GoogLeNet网络。属性将数据存储调整为输入大小变换函数。
inputSize = netCNN.Layers (1) .InputSize (1:2);fdsReSz = transform(fds,@(x) imresize(x,inputSize));
将视频转换为特征向量序列,其中特征向量为的输出激活函数的最后一个池层的GoogLeNet网络("pool5-7x7_s1“)。为了分析概述段内的堵塞血管的每一个尺寸和位置,我们不会在此处修改序列的长度。
提示:将视频转换为序列后,将序列保存在MAT文件中tempdir文件夹中。如果MAT文件已经存在,则从MAT文件加载序列而不重新转换它们。这个步骤可能需要很长时间来运行。
layerName = " pool5-7x7_s1”;tempFile = fullfile (tempdir sequences_nano.mat);if exist(tempFile,'file') load(tempFile,"sequences") else numFiles = numel(files);序列=细胞(numFiles, 1);为了我= 1:numfilesfprintf("读取文件%d…\n",我,numFiles);序列{i,1} =激活(netcnn,读取(fdsresz),layername,'outputas'那'列'那'executionenvironment'那“汽车”);结尾保存(TempFile,“序列”);结尾
然后我们查看前几个序列的大小。每个序列都是D.——- - - - - -S.数组,D.是功能数量(池池层的输出大小)和S.是视频的帧数。
序列(1:10)

准备培训数据
在这里,我们通过将数据划分为训练和验证分区来准备训练数据。我们将90%的数据分配给训练分区,10%分配给验证分区。
标签= nanotrainlabels.stalled;numObservations =元素个数(序列);idx = randperm (numObservations);N = floor(0.9 * numobations);idxTrain = idx (1: N);sequencesTrain =序列(idxTrain);labelsTrain =标签(idxTrain);idxValidation = idx (N + 1:结束);sequencesValidation =序列(idxValidation);labelsValidation =标签(idxValidation);
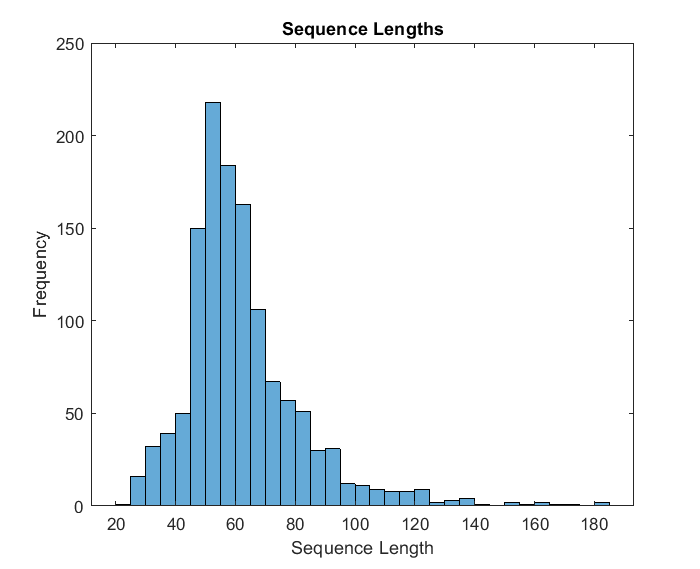
然后,我们获得训练数据的序列长度并在直方图图中可视化它们。
numobservationstrain = numel(sequencestain);Sequencelengths =零(1,numobservationstrain);对于i = 1:numobservationstrain序列= sequencestain {i};Sequencelengths(i)=大小(序列,2);结束图直方图(Sequencelengs)标题(“序列长度”)XLabel(“序列长度”)Ylabel(“频率”)
创建LSTM网络
接下来,创建一个短期内记忆(LSTM)该网络可以对表示视频的特征向量序列进行分类。
然后定义LSTM网络体系结构并指定以下网络层。
- 一种序列输入层输入大小对应于特征向量的特征维度
- 一种BiLSTM层有2000个隐藏单元辍学层要为每个序列只输出一个标签,可以设置OutputMode.'Bilstm层的选项'去年'
- 一种完全连接层输出大小对应于类的数量,asoftmax层和A.分类层.
numFeatures =大小(sequencesTrain {1}, 1);numClasses = 2;层= [sequenceInputLayer(numFeatures,'Name','sequence') bilstmLayer(2000,'OutputMode','last','Name','bilstm') dropoutLayer(0.5,'Name','drop') fullconnectedlayer (numClasses,'Name','fc') softmaxLayer('Name','softmax') classificationLayer('Name','classification')];
指定培训选项
作为下一步,我们使用trainingOptions功能:
- 设置小批量16,初始学习率为0.0001,梯度阈值为2(防止梯度爆炸)。
- 截断每个迷你批处理中的序列,使其具有与最短序列相同的长度。
- 每纪元播放数据。
- 每次时代验证网络一次。
- 在绘图中显示训练进度并抑制冗长的输出。
miniBatchSize = 16;numObservations =元素个数(sequencesTrain);numIterationsPerEpoch = floor(nummobations / miniBatchSize);options = trainingOptions('adam',…MiniBatchSize, MiniBatchSize,……“InitialLearnRate”,1的军医,…“GradientThreshold”,2,…“洗牌”、“every-epoch’,……ValidationData, {sequencesValidation, labelsValidation},…ValidationFrequency, numIterationsPerEpoch,…… 'Plots','training-progress', ... 'Verbose',false, ... 'ExecutionEnvironment','auto');
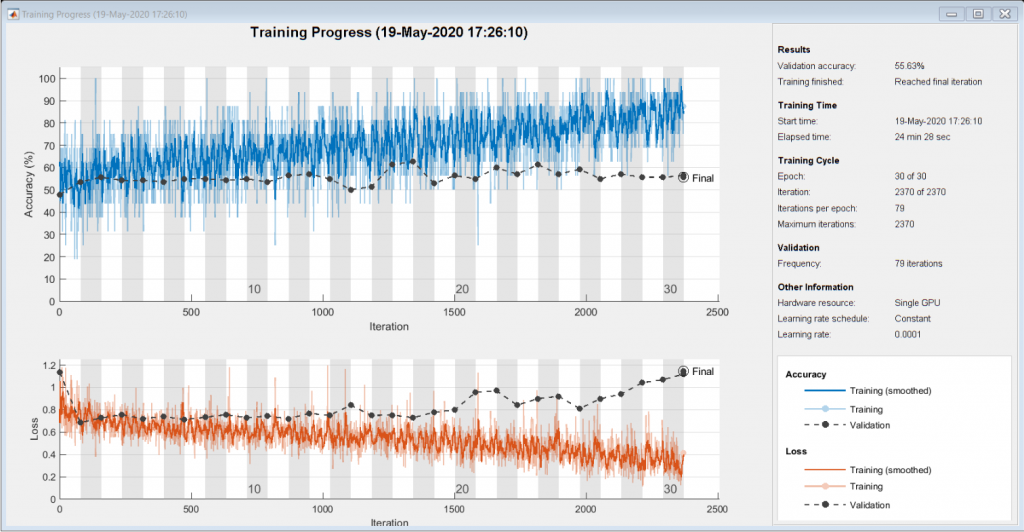
火车LSTM网络
然后我们使用的是培训网络Trainnetwork.函数。注意,由于涉及的计算,这个函数可能需要很长时间才能运行。
[netLSTM,信息]= trainNetwork (sequencesTrain、labelsTrain层,选择);
作为下一步,我们计算使用验证设置的网络的分类准确性分类函数。您可以使用与培训选项相同的批量批量尺寸。
ypred =分类(netlstm,semencessvalidation,'minibatchsize',minibatchsize);yvalidation = labelsvalidation;精度=均值(ypred == yvalidation)
组装视频分类网络
要创建直接对视频进行分类的网络,请使用来自所有创建的网络的图层组装网络。使用来自卷积网络的图层将视频转换为矢量序列和从LSTM网络的层进行分类矢量序列。
下图说明了网络架构。
- 要向网络输入图像序列,使用序列输入层。
- 使用卷积层提取特征,即对视频的每一帧单独进行卷积操作,先使用序列折叠层,再使用卷积层。
- 为了恢复序列结构并将输出重塑为向量序列,请使用序列展开层和平坦层。
- 为了对所得到的矢量序列进行分类,包括LSTM层,然后包括输出层。

添加卷积层
首先,我们创建了GoogLeNet网络的层图。
cnnlayers = layergraph(netcnn);
然后我们删除输入层(“数据")和用于激活的池化层之后的层("pool5-drop_7x7_s1“,”损失3分类器“,”概率”、“输出“)。
layerNames = ["data" "pool5-drop_7x7_s1" "loss3-classifier" "prob" "output"];cnnLayers = removeLayers (cnnLayers layerNames);
添加序列输入层
我们创建一个序列输入层接受包含与Googlenet网络相同的输入大小的图像的图像序列。使用与Googlenet网络相同的平均图像标准化图像,设置“正常化“序列输入层的选项”zerocenter'和'的意思是'rooglenet的输入层的平均图像的选项。
inputSize = netCNN.Layers (1) .InputSize (1:2);普生图像= netcnn.layers(1).mean;InputLayer = sequenceInputLayer([inputsize 3],...'归一化','zerocenter',...'均值',ulimage,...'名称','输入');
然后我们将序列输入层添加到层图中。为了将卷积层独立应用于序列图像,我们通过在序列输入层和卷积层之间加入序列折叠层来去除图像序列的序列结构。然后我们将序列折叠层的输出连接到第一卷积层的输入(”conv1-7x7_s2“)。
layers = [inputLayer sequenceFoldingLayer('Name','fold')];lgraph = addLayers (cnnLayers层);lgraph = connectLayers (lgraph“折叠/”,“conv1-7x7_s2”);
添加LSTM层
下一步是通过去除LSTM网络的序列输入层,将LSTM层添加到层图中。为了恢复被序列折叠层删除的序列结构,我们可以在卷积层之后再加入一个序列展开层。LSTM层期望向量序列。为了将序列展开层的输出重塑为矢量序列,我们在序列展开层之后添加了一个flatten层。
我们从LSTM网络中取出各层,去掉序列输入层。
lstmlayers = netlstm.layers;lstmlayers(1)= [];
添加序列折叠层,扁平层和LSTM层到层图。连接最后一个卷积层(“pool5-7x7_s1“)到序列展开层的输入(”展开/ in.“)。
图层= [sequenceUnfoldingLayer('Name','展开')flatten ('Name','flatten') lstmLayers];lgraph = addLayers (lgraph层);lgraph = connectLayers (lgraph、“pool5-7x7_s1”、“展开/”);
要使展开层恢复序列结构,请连接“小匹匹匹匹配“序列折叠层的输出到序列展开层的相应输入。
lgraph = connectLayers (lgraph、“折叠/ miniBatchSize”、“展开/ miniBatchSize”);
组装网络
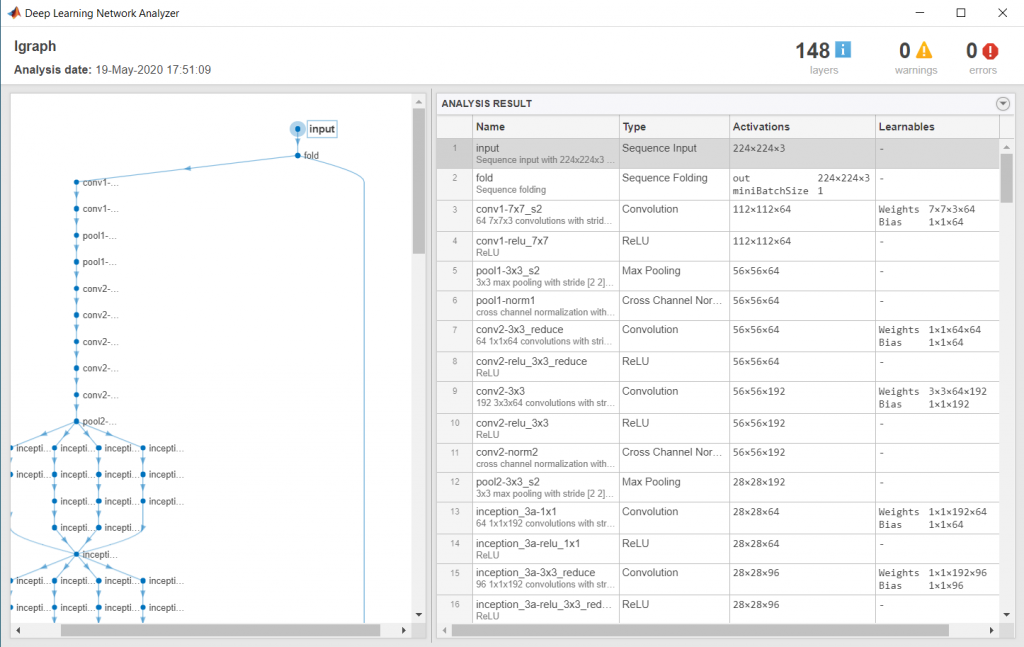
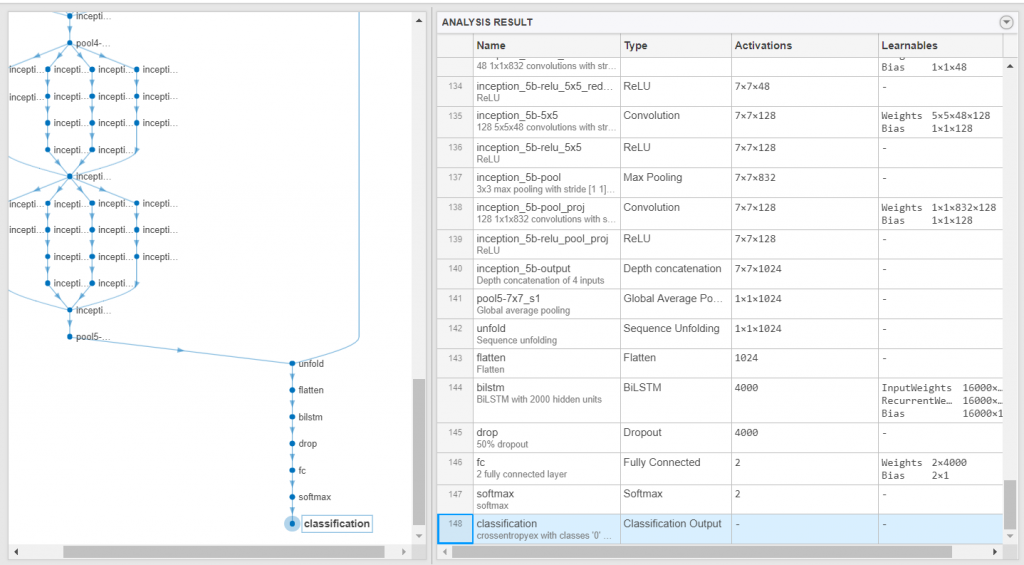
然后使用。检查网络是否有效analyzeNetwork函数。
analyzeNetwork (lgraph)
并且,组装网络使其已准备好使用的预测assembleNetwork函数。
net = assemblenetwork(lgraph)
准备测试数据
就像我们对训练数据所做的那样,我们现在将在filedatastore中读取测试文件并使用readvideo.函数。然后使用transform函数根据inputSize调整裁剪文件数据存储的大小。
当我们使用一个文件夹中的所有文件时,我们可以直接给出s3文件夹URL.在创建数据存储时输入 。这个速度启动数据存储的创建。
testfds = filedataStore('s3:// drivendata-rest-cloug-loss / test /','readfcn',@readvideo);testfdsresz = transform(testfds,@(x){imresize(x,输入)});
使用测试数据进行分类
一旦我们有了经过训练的网络,我们就可以对测试集进行预测。为此,我们使用集合网络对测试集视频进行分类。这分类函数需要一个包含输入视频的单元格数组,因此必须输入一个包含视频的1 × 1单元格数组。
测试文件= testfds.Files;numTestFiles =元素个数(测试文件);YPred =细胞(numTestFiles, 1);for i = 1:numTestFiles fprintf("读取文件%d的%d…"\ n”,我,numTestFiles);YPred{我1}=分类(净、读取(testfdsReSz)、“ExecutionEnvironment”,“汽车”);结尾
保存提交文件
我们根据文件名和预测分数创建结果表。提交的所需文件格式是具有COULMN名称的CSV文件:文件名和停滞不前.
我们将把所有测试结果放在MATLAB表中,这使得可视化和写入所需的文件格式变得容易。
测试= readtable(“test_metadata.csv”);检测结果=表(test.filename YPred (: 1), VariableNames,{“文件名”,“停滞”});
然后我们将结果写入一个CSV文件。这是你要提交的挑战文件。
writetable(检测结果,“testResults.csv”);
辅助函数
这阅读视频功能读取文件名中的视频并返回裁剪好的4-D帧。
整个视频中感兴趣的区域是视频中每一帧中橘黄色的区域我们想要提取出来用于接下来的训练。因此,每一帧都是按照分段的边界框裁剪的,使用detectroi.函数。
function video = readVideo(filename) vr = videreader (filename);我= 0;% video = 0;while hasFrame(vr) i = i+1;帧= readFrame (vr);if i < 2 Bbox = detectROI(frame); / /检测帧结束帧= imcrop(frame, Bbox);视频(::,:,i) =框架;结束结束
这纠结根据定义的阈值检测概述段和阈值图像。使用matlab生成此功能颜色阈值的应用.用于检测由橙色标记指定的区域,我们使用BLOB分析.我们选择将感兴趣的区域保留为长轴最大的blob。查看以下视频了解更多信息。
function [Bbox] = detectROI(frameIn) %%设置检测器并初始化变量persistent检测器如果为空(检测器)检测器= vision.BlobAnalysis('BoundingBoxOutputPort',true,'MajorAxisLengthOutputPort',true);End threshold = [104 255;13 143;9 98];掩码= (frameIn(:: 1) > =阈值(1,1))& (frameIn(:,: 1) < =阈值(1、2)&……(frameIn(:,: 2) > =阈值(2,1))& (frameIn(:,: 2) < =阈值(2,2))&……(frameIn(:,:, 3) > =阈值(3,1))& (frameIn(:,:, 3) < =阈值(3 2));[~, ~, Bbox1, majorAxis] =检测器(掩码);if ~isempty(majorAxis) % Identify最大Blob [~,mIdx] = max(majorAxis); / /指定最大BlobBbox = Bbox1 (mIdx:); end end
感谢您的博客。我们很高兴找到如何修改此启动器代码并使其成为您的。我们强烈建议看我们的深度学习技巧页面有关如何改进基准模型的更多想法。你也可以看看这个博客:你准备好参加视频分类挑战了吗,了解5种不同的视频分类方法。
请随时联系我们DrivenData论坛如果你还有其他问题。
- 类别:
- 数据科学


评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。