监督学习是最常见的类型机器学习算法。它使用已知的DataSet(称为训练数据集)来训练具有已知一组输入数据(称为特征)和已知响应的算法,以便进行预测。训练数据集包括标记的输入数据,该输入数据与所需的输出或响应值配对。从它来看,监督学习算法试图通过发现特征和输出数据之间的关系来创建模型,然后使新数据集的响应值预测。
在申请监督学习之前,无人监督的学习经常用于发现建议候选功能的输入数据中的模式,并且特征工程将它们转换为更适合受监管的学习。除了识别特征外,还需要针对培训集中的所有观察确定的正确类别或响应,这是一个非常劳动密集型的步骤。半监督学习允许您使用非常有限的标记数据训练模型,从而减少标签努力。
一旦算法被训练,通常使用一个没有用于训练的测试数据集来预测算法的性能并验证它。为了获得准确的性能结果,训练集和测试集都是“现实”的良好表示(即,来自生产环境和模型的数据都被正确验证)是至关重要的。
您可以培训,验证和调整预测性监督学习模型马铃薯®和深度学习工具箱™,统计和机器学习工具箱™。
监督学习算法类别
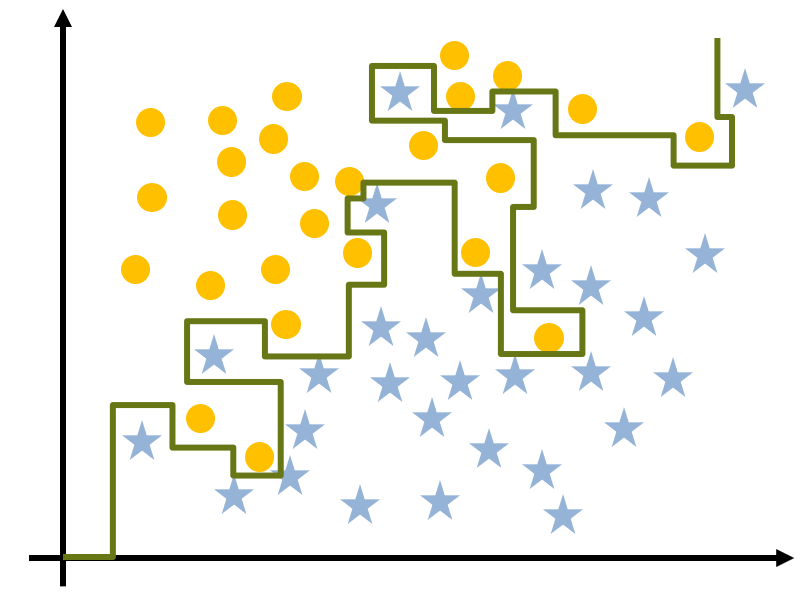
分类:用于分类响应值,其中数据可以分成特定类。二进制分类模型具有两个类,多字符分类模型更多。您可以使用MATLAB与分类学习者应用培训分类模型。
常见的分类算法包括:
- 物流回归
- 金宝app支持矢量机器(SVM)
- 神经网络
- 天真贝叶斯分类器
- 决策树
- 判别分析
- 最近的邻居(knn)
- 系综分类
回归:用于数值连续响应值。您可以使用Matlab与回归学习者应用程序培训回归模型。
例子
让我们假设您希望预测房价,并在与房屋统一,地点和作为特征销售的情况下拥有历史数据,以及作为已知反应的实际销售价格。这是监督回归的优秀用例,你可以在本例中自己尝试一下.下面所示的线性模型的权重是有意义的:房屋的类型和大小,建造年份,以及社区确实决定了房屋价值。剩余图表明线性模型相当好地捕捉了变量和价格之间的关系

