语音情感识别
本示例演示了一个使用BiLSTM网络的简单语音情感识别系统。首先下载数据集,然后在单个文件上测试经过训练的网络。该网络根据一个小型德语数据库进行培训[1].
该示例通过培训网络,包括下载,增强和培训数据集。最后,您执行休假(LOSO)10倍交叉验证以评估网络架构。
本例中使用的特征是使用顺序特征选择来选择的,类似于用于音频功能的顺序特征选择.
下载数据集
下载柏林情感演讲数据库[1].该数据库包含10名演员所说的535句话,旨在表达以下情绪之一:愤怒、无聊、厌恶、焦虑/恐惧、幸福、悲伤或中性。这些情绪与文本无关。
url =“http://emodb.bilderbar.info/download/download.zip”;downloadfolder = tempdir;datasetfolder = fullfile(DownloadFolder,“Emo数据库”);如果~exist(datasetFolder,“dir”)disp('下载Emo-DB(40.5 MB)......')解压缩(URL,DataSetFolder)终止
创建一个audiodatastore.指向音频文件。
广告= audiodataStore(fullfile(datasetfolder,“wav”));
文件名是表示说话人ID、所说文本、情感和版本的代码。网站包含用于解释代码的键以及有关说话人的其他信息,如性别和年龄。创建一个包含变量的表扬声器和强烈的感情。将文件名解码到表中。
filepaths = Ads.files;Emotioncodes = Cellfun(@(x)x(ex-5),filepaths,“UniformOutput”,假);情感=替换(情感代码{“W”那“我那“E”那“A”那“F”那'T'那'n'},...{'愤怒'那“无聊”那“厌恶”那“焦虑/恐惧”那“幸福”那“悲伤”那“中立”});speakerCodes = Cellfun(@(x)x(ex-10:end-9),filepaths,“UniformOutput”、假);labeltable = cell2table([speakercodes,情绪],“变化无常”,{“议长”那'情感'});labelTable。强烈的感情= categorical(labelTable.Emotion); labelTable.Speaker = categorical(labelTable.Speaker); summary(labelTable)
变量:扬声器:535×1分类值:03 49 08 58 09 43 10 38 11 55 12 35 13 61 14 69 15 56 16 71情绪:535×1分类值:愤怒127焦虑/恐惧69无聊81厌恶46幸福71中性79悲伤62
柔软的与中的文件顺序相同audiodatastore..设定标签财产audiodatastore.到柔软的.
ads.Labels = labelTable;
执行语音情感识别
下载并加载预训练网络音频特征提取器对象用于训练网络,并对特征进行归一化因子。该网络使用数据集中除发言者外的所有发言者进行训练03.
url ='http://ssd.mathwands.com/金宝appsupportfiles/audio/speeheMotionRecognition.zip';downloadNetFolder=tempdir;netFolder=fullfile(downloadNetFolder,'SpeemMotionRecognition');如果~exist(netFolder,“dir”)disp('下载预训练网络(1文件- 1.5 MB)…')解压缩(url,下载NetFolder)终止加载(完整文件)(netFolder,“网络音频服务器垫”));
上设置的采样率音频特征提取器对应于数据集的采样率。
fs=afe采样器;
选择一个说话者和情绪,然后将数据存储子集为只包含所选的说话者和情绪。从数据存储中读取并监听文件。
演讲者=分类的(“03”);情感=
绝对(“厌恶”);(广告、ads.Labels adsSubset =子集。扬声器==speaker & ads.Labels.Emotion == emotion); audio = read(adsSubset); sound(audio,fs)


使用音频特征提取器对象提取功能,然后转换它们,以便沿行呈现时间。标准化功能,然后将它们转换为具有10元重叠的20元序列,其对应于大约600毫秒的窗口,具有300ms重叠。使用支持功能,金宝appHelperFeatureVector2序列,将特征向量数组转换为序列。
features=(extract(afe,audio));featuresNormalized=(features-normalizers.Mean)。/normalizers.StandardDeviation;numOverlap= 10;Featuresequences = HelperFeatureVector2sequence(特色,20,NumOverlap);
10;Featuresequences = HelperFeatureVector2sequence(特色,20,NumOverlap);

将特征序列输入网络进行预测。计算平均预测,并将所选情绪的概率分布绘制成饼状图。你可以尝试不同的扬声器、情绪、序列重叠和预测平均值来测试网络的性能。要获得网络性能的近似真实值,请使用扬声器03,该网络未接受培训。
YPred=双倍(预测(净,特征序列));平均值=“模式”;转换平均数情况下“中庸”probs=平均值(YPred,1);情况下“中位数”probs=中值(YPred,1);情况下“模式”probs=模式(YPred,1);终止饼(probs./sum(probs),string(net.layers(端).classes))

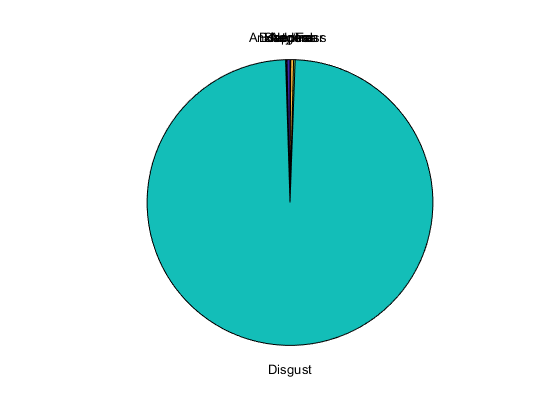
示例的其余部分说明了如何培训和验证网络。
火车网络
由于训练数据不足,首次尝试训练的10倍交叉验证准确率约为60%。在数据不足的情况下训练的模型过度拟合某些折叠,而不足拟合其他折叠。为了提高整体拟合,请使用音频数据增强器根据经验,选择每个文件0.50个增强是为了在处理时间和精度提高之间进行折衷。您可以减少增强的数量以加快示例的速度。
创建一个音频数据增强器对象。设置将俯仰移动应用于的概率0.5并使用默认范围。设置施加时间转移的概率1并使用一系列的[-0.3,0.3]秒。设置添加噪波的概率1并指定SNR范围(-20年,40)dB。
numAugmentations =50;upulmer = audiodataAugmenter(“NumAugmentations”,裸体,...'timestretchprobability'0,...“VolumeControlProbability”0,......“变桨可能性”,0.5,......“时移概率”,1,...“时间换档范围”,[ - 0.3,0.3],......“AddNoiseProbability”,1,...“SNRRange”, -20年,40);

在当前文件夹中创建一个新文件夹以保存扩展数据集。
currentDir=pwd;writeDirectory=fullfile(currentDir,“augmentedData”);mkdir(writeDirectory)
对于音频数据存储中的每个文件:
创建50个扩增。
将音频规格化为最大绝对值1。
将增强的音频数据写为WAV文件。附加
_奥克到每个文件名,其中K.是扩充数。若要加快处理速度,请使用议案并对数据存储进行分区。
这种增强数据库的方法是耗时(大约1小时)和空间消耗(大约26 GB)。然而,当迭代在选择网络架构或特征提取管道时,这种前期成本通常是有利的。
N =元素个数(ads.Files) * numAugmentations;myWaitBar = HelperPoolWaitbar (N,“增强数据集......”);重置(广告)Numpartitions = 18;Tic.议案ii=1:numPartitions adsPart=partition(ads,numPartitions,ii);虽然hasdata(adsPart) [x,adsInfo] = read(adsPart);data =增加(增压器,x, fs);[~, fn] = fileparts (adsInfo.FileName);为了i=1:size(data,1)augmentedAudio=data.Audio{i};augmentedAudio=augmentedAudio/max(abs(augmentedAudio),[],“全部”)augNum=num2str(i);如果numel(augNum)==1 iString=['0'augNum);其他的iString = augNum;终止audiowrite(fullfile(writedirectory,sprintf(“%s_八月%s.wav”,fn,iString)),增强音频,fs);增量(myWaitBar)终止终止终止
正在使用连接到并行池的“本地”配置文件启动并行池(parpool)(工作进程数:6)。
删除(myWaitBar)fprintf('扩充完成(%0.2f分钟)。\n',TOC / 60)
扩充完成(6.28分钟)。
创建一个指向扩充数据集的音频数据存储。复制原始数据存储的标签表的行简化确定扩充数据存储的标签的时间。
adsaug = audiodatastore(writedirectory);Adsaug.Labels = Repelem(Ads.Labels,Augmenter.numauginations,1);
创建一个音频特征提取器目的。放窗定期30毫米汉明窗口,OverlapLength到0.和取样频率到数据库的采样率。放gtcc那gtccDelta那mfccDelta和光谱休息到符合事实的提取它们。设置SpectralDescriptorInput到熔化光谱所以光谱休息为mel光谱计算。
win=hamming(一轮(0.03*fs),“定期”);overtaplength = 0;AFE = audiofeatureextractor(...“窗口”,赢了,...“重叠长度”,overtaplength,...“采样器”,财政司司长,......“gtcc”符合事实的...“gtccDelta”符合事实的...“mfccDelta”符合事实的......“光谱描述输入”那'melspectrum'那...“幽灵休息”,对);
部署训练
在进行部署培训时,请使用数据集中所有可用的扬声器。将训练数据存储设置为扩充数据存储。
adsTrain=adsAug;
将培训音频数据存储转换为高大的数组。如果您有并行计算工具箱™,则提取将自动并行化。如果您没有并行计算工具箱™,则代码继续运行。
tallTrain =高(adsTrain);
提取训练特征并重新确定特征的方向,以便时间沿行与序列输入层(深度学习工具箱).
featureStalltrain = Cellfun(@(x)提取物(afe,x),塔特拉特,“统一输出”、假);featuresTallTrain = cellfun (@ (x) x ', featuresTallTrain,“统一输出”,false);featuresTrain=聚集(featuresTallTrain);
使用Parallel Pool 'local'计算tall表达式:- Pass 1 of 1: Completed in 1 min 7 sec
使用训练集来确定每个特征的均值和标准偏差。
所有特征=cat(2,特征菌株{:});M=平均值(所有特征,2,“奥米南”);S=标准(所有特征,0,2,“奥米南”);featuresTrain = cellfun (@ (x)(即x m)。/ S, featuresTrain,“UniformOutput”、假);
将特征向量缓冲到序列中,使每个序列由20个特征向量组成,重叠10个特征向量。
featureVectorsPerSequence=20;featureVectorOverlap=10;[sequencesTrain,sequencePerFileTrain]=HelperFeatureVector2序列(featuresTrain,featureVectorsPerSequence,featureVectorOverlap);
复制训练集和验证集的标签,使其与序列一一对应。并非所有演讲者都能表达所有情绪。创建一个空的分类包含所有情感类别的数组,并将其附加到验证标签,以便类别数组包含所有情感。
labelsTrain=repelem(adsTrain.Labels.Emotion,[sequencePerFileTrain{:}]);emptyEmotions=ads.Labels.Emotion;emptyEmotions(:)=[];
使用定义BiLSTM网络双层膜(深度学习工具箱).放置一个落花人(深度学习工具箱)会议前后双层膜有助于防止过度安装。
dropoutProb1=0.3;货币=200;dropoutProb2=0.6;层=[...sequenceInputLayer(scale(sequencestain {1},1))oppoutlayer(dropoutprob1)bilstmlayer(numUnits,“输出模式”那“最后”)dropoutLayer(dropoutProb2)fullyConnectedLayer(numel(categories(EmptyMotions)))softmaxLayer classificationLayer];
使用培训选项使用培训选项(深度学习工具箱).
miniBatchSize = 512;initialLearnRate = 0.005;learnRateDropPeriod = 2;maxEpochs = 3;选择= trainingOptions (“亚当”那...“最小批量大小”miniBatchSize,...“InitialLearnRate”,initialLearnRate,...“LearnRateDropPeriod”,learnRateDropPeriod,...“LearnRateSchedule”那“分段”那...“MaxEpochs”,maxEpochs,...“洗牌”那“every-epoch”那...“verbose”错误的...“情节”那“训练进步”);
培训网络使用列车网络(深度学习工具箱).
net=列车网络(序列应变、标签列车、图层、选项);
要保存网络,请配置音频特征提取器,和归一化因子,集合savesersystem.到符合事实的.
储蓄系统=错误的;如果saveSERSystem标准化者。意味着= M;标准化者。StandardDeviation = S;保存(“网络音频服务器垫”那'网'那“afe”那“标准化者”)终止

系统验证培训
提供对您在此示例中创建的模型的准确评估,使用休假(LOSO)进行火车和验证K.-折叠交叉验证。在这种方法中,您使用 扬声器然后在左侧发言人验证。你重复这个程序K.次。最终验证精度为K.折叠。
创建一个包含说话人ID的变量。确定每个说话人的折叠次数:1。数据库包含来自10个唯一说话人的话语。使用总结显示说话人ID(左列)和他们对数据库贡献的话语数(右列)。
演讲者= ads.Labels.Speaker;numFolds =元素个数(扬声器);总结(扬声器)
03 49 08 58 09 43 10 38 11 55 12 35 13 61 14 69 15 56 16 71
辅助函数帮助培训和验证网络工作执行以上所有10个折叠概述的步骤,并返回每个折叠的真实和预测的标签。称呼帮助培训和验证网络工作和audiodatastore.,增广audiodatastore.,音频特征提取器.
[labelsTrue,labelsPred]=帮助培训和验证网络(ads、adsAug、afe);
打印每次折叠的精度,并绘制10倍混淆图。
为了ii=1:numel(labelsTrue)Foldac=平均值(labelsTrue{ii}==labelsPred{ii})*100;fprintf('折叠%1.0f,精度=%0.1f \ n',ii,foldacc);终止
折叠1,精度=73.5折叠2,精度=77.6折叠3,精度=74.4折叠4,精度=68.4折叠5,精度=76.4折叠6,精度=80.0折叠7,精度=73.8折叠8,精度=87.0折叠9,精度=69.6折叠10,精度=70.4
labelsTrueMat =猫(1,labelsTrue {:});labelsPredMat =猫(1,labelsPred {:});figure cm = confusionchart(labelsTrueMat,labelsPredMat);valAccuracy =意味着(labelsTrueMat = = labelsPredMat) * 100;厘米。标题= sprintf (' 10倍交叉验证的混淆矩阵\nAverage Accuracy = %0.1f',ValAccurance);分类(cm,类别(emptyEmotions))cm列摘要='列 - 归一化'; cm.RowSummary=“row-normalized”;

金宝app辅助功能
将特征向量的数组转换为序列
作用[sequences,sequencePerFile]=HelperFeatureVector2Sequence(特征,特征向量序列,特征向量重叠)%版权所有2019 MathWorks公司。如果featureVectorsPerSequence <= featureVectorOverlap error(“重叠特征向量的数量必须小于每个序列的特征向量的数量。”)终止如果〜Iscell(特征)功能= {特征};终止hopLength=featureVectorsPerSequence-featureVectorOverlap;idx1=1;sequences={};sequencePerFile=cell(numel(features),1);为了ii=1:numel(features)sequencePerFile{ii}=floor((size(features{ii},2)-featureVectorsPerSequence)/hopLength)+1;idx2=1;为了j = 1:sequencePerFile{ii} sequences{idx1,1} = features{ii}(:,idx2:idx2 + featureVectorsPerSequence - 1);%#好的Idx1 = Idx1 + 1;idx2 = idx2 + hopLength;终止终止终止
培训和验证网络
作用[truelabelscrossfold,predightlabelscrossfold] = HelpertrainAndValidateNetwork(varargin)%版权归MathWorks公司所有。如果nargin==3ads=varargin{1};augads=varargin{2};提取器=varargin{3};埃尔塞夫nargin==2ads=varargin{1};augads=varargin{1};提取器=varargin{2};终止扬声器=类别(Ads.Labels.Speaker);numFolds =元素个数(扬声器);ExpteMotions =(ADS.Labels.emotion);ExpteMotions(:) = [];每个折叠的%循环。trueLabelsCrossFold={};predictedLabelsCrossFold={};为了i=1:numfold%1.将音频数据存储划分为训练集和验证集。%将数据转换为高数组。idxTrain=augads.Labels.Speaker~=Speaker(i);augadsTrain=subset(augads,idxTrain);augadsTrain.Labels=augadsTrain.Emotion;tallTrain=tall(augadsTrain);idxValidation=ads(i);adsvidation=subset(ads,idxValidation);adsvidation.Labels=adsvidation.Labels.emots;tallvidation=tall(adsvidation);% 2。从训练集中提取特征。重新定位的功能%因此,时间是沿着要与之兼容的行进行的%sequenceInputLayer。tallTrain=cellfun(@(x)x/max(abs(x))[],“全部”),塔特特拉特,“统一输出”、假);tallFeaturesTrain = cellfun (@ (x)提取(萃取器,x), tallTrain,“统一输出”,假);TallFeatureRain=cellfun(@(x)x',TallFeatureRain,“统一输出”、假);%#好的[~,特征菌株]=evalc(“收集(tallFeaturesTrain)”);%使用evalc抑制命令行输出。tallValidation=cellfun(@(x)x/max(abs(x),[],“全部”),tallValidation,“统一输出”,false);tallFeaturesValidation=cellfun(@(x)提取物(提取器,x),tallValidation,“统一输出”、假);tallFeaturesValidation = cellfun (@ (x) x ', tallFeaturesValidation,“统一输出”、假);%#好的 [~,特征验证]=evalc(“聚集(tallFeaturesValidation)”);%使用evalc抑制命令行输出。%3.使用训练集确定平均值和标准%每个特征的偏差。规范培训和验证% 套。所有特征=cat(2,特征菌株{:});M=平均值(所有特征,2,“奥米南”);S=标准(所有特征,0,2,“奥米南”);featuresTrain = cellfun (@ (x)(即x m)。/ S, featuresTrain,“UniformOutput”、假);为了ii=1:numel(featuresTrain)idx=find(isnan(featuresTrain{ii}));如果~isempty(idx) featuresTrain{ii}(idx) = 0;终止终止featuresValidation=cellfun(@(x)(x-M)。/S,featuresValidation,“UniformOutput”、假);为了ii=1:numel(featuresValidation)idx=find(isnan(featuresValidation{ii}));如果~isempty(idx)特征验证{ii}(idx)=0;终止终止%4.缓冲序列,使每个序列由二十个组成%具有10个特征向量重叠的特征向量。featureVectorsPerSequence=20;featureVectorOverlap=10;[sequencesTrain,sequencePerFileTrain]=HelperFeatureVector2Sequence(featuresTrain,FeatureVectorSequence,featureVectorOverlap);[sequencesValidation,sequencePerFileValidation]=HelperFeatureVector2Sequence(featuresValidation,FeatureVectorSequence,featureVectorOverlap);%5.复制列车和验证集的标签,以便%它们与序列一一对应。labelsTrain=[emptyEmotions;augadsTrain.Labels];labelsTrain=labelsTrain(:);labelsTrain=repelem(labelsTrain[sequencePerFileTrain{:}]);% 6. 定义BiLSTM网络。dropoutProb1=0.3;货币=200;dropoutProb2=0.6;层=[...sequenceInputLayer(scale(sequencestain {1},1))oppoutlayer(dropoutprob1)bilstmlayer(numUnits,“输出模式”那“最后”)dropoutLayer(dropoutProb2)fullyConnectedLayer(numel(categories(EmptyMotions)))softmaxLayer classificationLayer];%7.定义培训选项。miniBatchSize = 512;initialLearnRate = 0.005;learnRateDropPeriod = 2;maxEpochs = 3;选择= trainingOptions (“亚当”那...“最小批量大小”miniBatchSize,...“InitialLearnRate”,initialLearnRate,...“LearnRateDropPeriod”,learnRateDropPeriod,...“LearnRateSchedule”那“分段”那...“MaxEpochs”,maxEpochs,...“洗牌”那“every-epoch”那...“verbose”、假);%8.培训网络。net=列车网络(序列应变、标签列车、图层、选项);% 9。评估网络。调用分类以得到预测的标签%为每个序列。获取每个预测标签的模式%序列获取每个文件的预测标签。predictedLabelsPerSequence=分类(净,序列验证);trueLabels=分类(adsValidation.Labels);predictedLabels=trueLabels;idx1=1;为了II = 1:numel(truelabels)predgeLabels(ii,:) = mode(predigedlabelspersequence(Idx1:idx1 + sequencerfilevalidation {ii} - 1,1);idx1 = idx1 + sequencerfilev alidation {ii};终止truelabelscrossfold {i} = truilabels;%#好的 predictedLabelsCrossFold{i}=predictedLabels;%#好的 终止终止
工具书类
[1] Burkhardt,F.,A.Paeschke,M. Rolfes,W.f.Sendlmeier,和B. Weiss,“德国情绪言论的数据库。”在诉讼程序诊断2005..里斯本,葡萄牙:国际言论协会,2005年。
您还可以从以下列表中选择网站: