基于无迹卡尔曼滤波和粒子滤波的非线性状态估计
此示例显示了如何使用Unspented Kalman滤波器和粒子滤波器算法,用于van der POL振荡器的非线性状态估计。
本示例还使用了信号处理工具箱™。
介绍
控制系统工具箱™为非线性状态估计提供三个命令:
extendedKalmanFilter:一阶,离散时间扩展卡尔曼滤波器undentedkalmanfilter:离散时间无需卡尔曼滤波器粒子滤片:离散时间粒子过滤器
使用这些命令的典型流程如下:
模拟您的植物和传感器行为。
构造并配置
extendedKalmanFilter那undentedkalmanfilter或粒子滤片对象。的方法执行状态估计
预测和正确的使用对象的命令。分析结果以获得对过滤器性能的信心
在硬件上部署过滤器。您可以使用MATLAB Coder™为这些过滤器生成代码。
本例首先使用undentedkalmanfilter命令演示此工作流程。然后它表明使用粒子滤光器。
工厂建模和离散化
无迹卡尔曼滤波(UKF)算法需要一个函数来描述从一个时间步骤到下一个时间步骤的状态演化。这通常被称为状态转移函数。unscentedKalmanFilter支金宝app持以下两种函数形式:
添加剂过程噪声:
非添加过程噪声:
这里F(..)为状态转移函数,X为状态,w为过程噪声。U是可选的,表示附加的输入F,例如系统输入或参数。你可以指定为零或多个函数参数。附加噪声意味着状态和过程噪声是线性相关的。如果关系是非线性的,请使用第二种形式。当你创造的时候undentedkalmanfilter对象,您指定F(..)以及过程噪声是否是附加的或非添加剂。
该示例中的系统是带MU = 1的范德波振荡器。使用以下非线性常微分方程(ODE)描述了这两个状态系统:
表示这方程式 ,在那里 .进程噪声w没有出现在系统模型中。为了简单起见,您可以假设它是加法的。
unscentedKalmanFilter需要一个离散时间的状态转移函数,但被试模型是连续时间的。你可以对连续时间模型使用离散时间近似。欧拉离散法是一种常用的逼近方法。假设你的样本时间是 ,并表示您拥有的连续时间动态 .欧拉离散化近似导数算子为 .由此产生的离散时间 - 转换功能是:
这种近似的准确性取决于采样时间 .小 值提供更好的近似。或者,您可以使用不同的离散化方法。例如,在给定固定的样本时间下,高阶龙格-库塔方法提供了更高的精度,但代价是更多的计算成本 .
创建此状态转换功能并将其保存在名为VDPSTATEFCN.M的文件中。使用采样时间
.你提供了这个功能undentedkalmanfilter在物体建设期间。
AddPath(FullFile(Matlabroot,“例子”那“控制”那'主要的')))%添加示例数据类型vdpstatefcn.
功能x = vdpstatefcn(x)%vdpstatefcn用于Mu = 1.%采样时间的Van der POL杂物的离散时间近似为0.05s。用于离散时间非线性状态%估算器的%%示例状态转换函数。%% xk1 = vdpstatefcn(xk)%输入:%xk - 状态x [k]%%输出:%xk1 - 传播状态x [k + 1] %%另见ExtendedKalmanFilter,UnstentedkalmanFilter%2016 MathWorks,Inc。%#codegen%标签%#codegen如果要使用%MATLAB编码器生成代码,则必须包括。连续时间动态x'= f(x)的%euler积分具有采样时间dt dt = 0.05;%[s]采样时间x = x + vdpstatefcncontinuous(x)* dt;结束功能DXDT = VDPSTATEFCNContinuous(X)%VDPSTATEFCNContion评估MU = 1 dxdt = [x(2)的范德波孔。(1-x(1)^ 2)* x(2)-x(1)];结尾
传感器建模
undentedkalmanfilter还需要一个函数,描述模型状态如何与传感器测量有关。undentedkalmanfilter金宝app支持以下两个功能表格:
添加剂测量噪声:
非添加性测量噪声:
H(..)为测量函数,V.是测量噪声。你是可选的,代表额外的输入H,例如系统输入或参数。U可以指定为零个或多个函数参数。您可以添加附加的系统输入你术语。这些输入可以不同于状态转移函数中的输入。
对于这个例子,假设你有第一状态的测量值 在一定百分比误差范围内:
这落入了非加性测量噪声的类别,因为测量噪声不会简单地添加到状态的函数中。你想估计两者 和 从嘈杂的测量。
创建此状态转换功能并将其保存在名为的文件中vdpMeasurementNonAdditiveNoiseFcn.m.你提供了这个功能undentedkalmanfilter在物体建设期间。
类型vdpmeasurementnonadditivenoisefcn.
示例测量函数用于含非加性测量噪声的离散%时间非线性状态估计器。% % yk = vdpNonAdditiveMeasurementFcn(xk,vk) % %输入:% xk - x[k],时刻k % vk - v[k],时刻k测量噪声% %输出:% yk - y [k],测量时k % %带乘性噪声测量是第一个国家% %也看到extendedKalmanFilter unscentedKalmanFilter % 2016年版权MathWorks公司% # % # codegen %标签codegen必须包括如果你想用% MATLAB编码器生成代码。yk = xk (1) * (1 + vk);结尾
无创的卡尔曼滤波器建设
通过提供状态转换和度量函数的函数句柄来构造过滤器,然后是您的初始状态猜测。状态转移模型具有可加性噪声。这是过滤器中的默认设置,因此您不需要指定它。度量模型具有非加性噪声,您必须通过设置hasadditivemeasurementnoise.物体的财产错误的.这必须在对象结构期间完成。如果您的应用程序在状态转换函数中具有非添加性过程噪声,请指定HasAdditiveProcessNoise财产错误的.
%您的初始状态猜测在时间k,利用测量值k-1:xhat [k | k-1]initialSteguess = [2; 0];%xhat [k | k-1]%构造过滤器Ukf = UnscentedkalmanFilter(...@vdpStateFcn,...%状态转换功能@vdpMeasurementNonAdditiveNoiseFcn,...%测量功能initnstateguess,...'hasadditivemeasurementnoise'、假);
提供您对测量噪声协方差的了解
R = 0.2;测量噪声方差% v[k]ukf.measurementnoise = r;
这processnoise.属性存储过程噪声协方差。它被设置为考虑模型的不准确性和未知干扰对电厂的影响。在这个例子中我们有真实的模型,但是离散化会带来错误。为了简单起见,本例中没有包含任何干扰。将其设置为一个对角线矩阵,在第一个状态上噪声更少,在第二个状态上噪声更多,以反映第二状态受建模错误影响更大的知识。
Ukf.processnoise = diag([0.02 0.1]);
使用预测和正确的命令估计
在您的应用程序中,来自硬件的实时测量数据在到达时由过滤器进行处理。这个操作在本例中演示了,首先生成一组测量数据,然后一步一步地将数据输入过滤器。
模拟范德堡尔振荡器5秒,滤波器采样时间为0.05 [s],以生成系统的真实状态。
t = 0.05;%[S]过滤器采样时间timeVector = 0:师:5;[~, xTrue] =数值(@vdp1、timeVector [2; 0]);
假设传感器测量第一状态,生成测量值,每次测量中的标准差为45%误差。
rng (1);%修复随机数生成器的可重复结果yTrue = xTrue (: 1);yMeas = yTrue .* (1+sqrt(R)*randn(size(yTrue))));%根号(R):噪声标准差
为稍后要分析的数据预分配空间
nsteps = numel(ymeas);%时间步长Xcorritedukf =零(nsteps,2);%校正状态估计PCorrected = 0 (Nsteps 2 2);修正状态估计误差协方差e =零(nsteps,1);%残差(或创新)
执行在线估计国家X使用正确的和预测命令。一次向滤波器提供生成的数据一次。
为了k = 1:nsteps用k表示当前时间。%残差(或创新):测量产出-预测产出e(k)= ymeas(k) - vdpmeasurementfcn(Ukf.state);此时,%UKF.State是x [k | k-1]%将时间k加入状态估计值%使用“正确”命令。此更新状态和StateCovariance过滤器的%性质含有X [k | k]和P [k | k]。这些价值观%也会作为“correct”命令的输出产生。[xCorrectedUKF (k,:), PCorrected (k,:,:)] =正确(ukf, yMeas (k));%在下一次步骤中预测状态K + 1。此更新状态和滤波器的%stemovariance属性包含x [k + 1 | k]和% P (k + 1 | k)。这些将被过滤器在下一个时间步骤中利用。预测(UKF);结尾
Unscented Kalman筛选结果和验证
随着时间的推移,绘制真实和估计的状态。也画出第一个状态的测量值。
图();次要情节(2,1,1);情节(timeVector xTrue (: 1), timeVector, xCorrectedUKF (: 1), timeVector, yMeas (:));传奇('真的'那“UKF估计”那'衡量')ylim([ - 2.6 2.6]);ylabel(“x_1”);次要情节(2,1,2);绘图(TimeVector,Xtrue(:,2),TimeVector,XcorratedukF(:,2));ylim([ - 3 1.5]);Xlabel('时间[S]');ylabel(“x_2”);
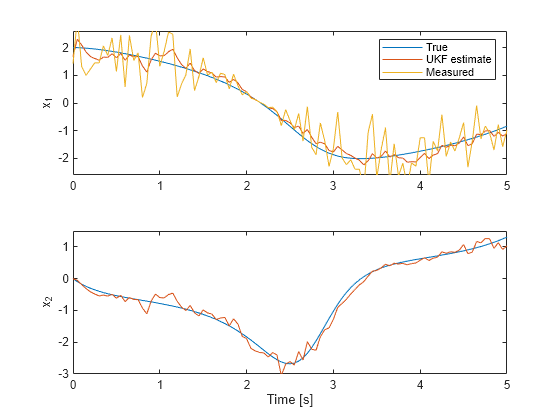
顶部绘图显示了第一个状态的真实,估计和测量值。过滤器利用系统模型和噪声协方差信息,以在测量结果上产生改进的估计。底部图显示了第二个状态。过滤器是成功的,生产良好的估计。
通常使用广泛的Monte Carlo模拟进行无需和扩展卡尔曼滤波器性能的验证。这些模拟应测试过程和测量噪声的变化,在各种条件下运行的工厂,初始状态和州协方差猜测。用于验证状态估计的关键兴趣信号是残差(或创新)。在此示例中,您对单个模拟执行残余分析。绘制残差。
图();情节(timeVector e);Xlabel('时间[S]');ylabel('剩余(或创新)');
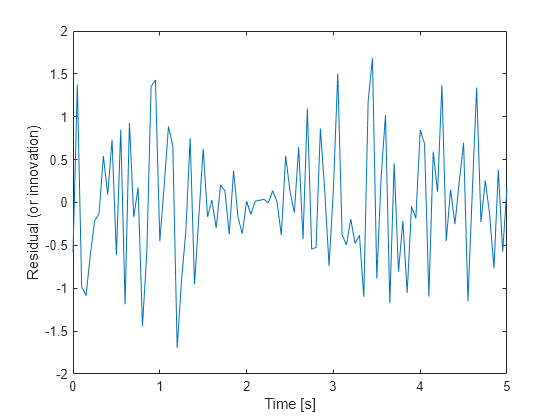
剩余部分应包括:
小的大小
零均值
没有自相关,除零滞后
残差的平均值是:
意思是(e)
ans = -0.0012
这相对于残差的大小很小。可以使用信号处理工具箱中的XCorr功能计算残差的自相关。
[xe,xelags] = xcorr(e,'coeff');%'coeff':通过零滞后的值正常化%只绘制非负滞后idx = xelags> = 0;图();绘图(XELAGS(IDX),XE(IDX));Xlabel(“滞后”);ylabel(归一化相关的);标题('残留的自相关(创新)');

除了0。平均相关系数接近于零,且相关系数没有明显的非随机变化。这些特性增加了对过滤器性能的信心。
在现实中,真正的状态是永远不可用的。然而,在执行模拟时,您可以访问真实状态,并可以查看估计状态和真实状态之间的误差。这些误差必须满足与残差相似的标准:
小的大小
过滤器错误协方差估计内的方差
零均值
不相关。
首先,看看错误和 从滤波器误差协方差估计的不确定性界限。
estates = xtrue-xcorritedukf;图();次要情节(2,1,1);绘图(TimeVector,Estates(:1),...第一个状态的错误TimeVector,SQRT(PCorrited(:,1,1)),'r'那...% 1-sigma上限TimeVector,-sqrt(pcorrited(:,1,1)),'r');%1-sigma下限Xlabel('时间[S]');ylabel('状态1'错误);标题('国家估计错误');次要情节(2,1,2);情节(timeVector地产(:,2),...第二个状态的错误timeVector,√PCorrected: 2 2)),'r'那...% 1-sigma上限timeVector -√(PCorrected (: 2 2)),'r');%1-sigma下限Xlabel('时间[S]');ylabel('状态2'错误);传奇(状态估计的那'1-sigma不确定性绑定'那...“位置”那'最好的事物');
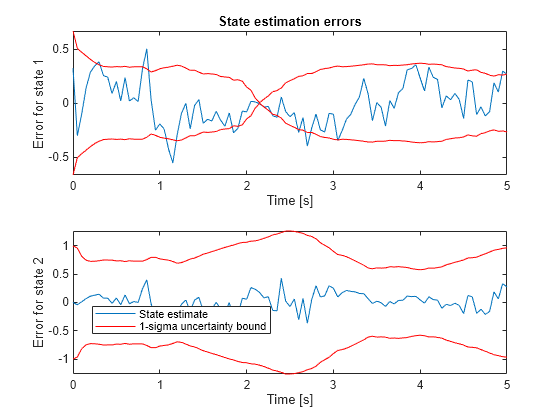
由于传感器模型,在T = 2.15秒内接近状态1的误差(MeasurementFCN.).它有这样的形式
.在T = 2.15秒时,真实和估计的状态接近零,这意味着绝对术语中的测量误差也在零附近。这反映在过滤器的状态估计误差协方差中。
计算点数的百分比超出了1-sigma不确定性绑定。
distanceFromBound1 = abs(地产(:1))-√(PCorrected (:, 1, 1));percentageExceeded1 = nnz(distanceFromBound1>0) / numel(eStates(:,1));distanceFromBound2 = abs(地产(:,2))-√(PCorrected (:, 2, 2));percentageExceeded2 = nnz(distanceFromBound2>0) / numel(eStates(:,2));[percentageExceeded1 percentageExceeded2]
ans =.1×20.1386 0
第一个状态估计误差超过了 不确定性约束约14%的时间步骤。不到30%的错误超过1-sigma不确定性绑定意味着良好的估计。这两个州都满足该标准。第二州的0%百分比意味着过滤器是保守的:最有可能组合过程和测量噪声太高。可能通过调整这些参数来获得更好的性能。
计算状态估计误差的平均自相关。同时绘制自相关图。
意思(庄园)
ans =.1×2-0.0103 - 0.0201
[xeStates1, xeStatesLags1] = xcorr(地产(:1),'coeff');%'coeff':通过零滞后的值正常化[xestates2,xestateslags2] = Xcorr(估值(:,2),'coeff');%'coeff'%只绘制非负滞后idx = xestateslags1> = 0;图();次要情节(2,1,1);绘图(Xestateslags1(IDX),Xestates1(IDX));Xlabel(“滞后”);ylabel('对于州1');标题('状态估计误差的标准化自相关');次要情节(2,1,2);绘图(Xestateslags2(idx),xestates2(idx));Xlabel(“滞后”);ylabel('对于州2');
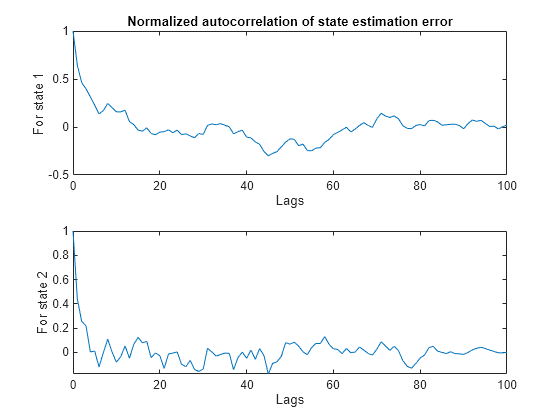
误差的平均值相对于州的值很小。状态估计误差的自相关显示小滞后值的非随机变化很小,但是这些比率小于归一化峰值1.结合估计状态准确的事实,残留物的这种行为可以被视为令人满意结果。
粒子滤波结构
无限和扩展的卡尔曼滤波器旨在跟踪状态估计的后部分布的平均值和协方差不同的近似方法。如果系统中的非线性严重,则这些方法可能是不够的。此外,对于一些应用,只需跟踪状态估计的后部分布的平均值和协方差可能是不够的。粒子过滤器可以通过追逐许多状态假设(粒子)的演变,以牺牲更高的计算成本来解决这些问题。计算成本和估计精度随粒子的数量增加。
这粒子滤片控制系统工具箱中的命令实现了一个离散时间粒子滤波器算法。这节走进通过构造一个粒子滤片,并强调了它与无迹卡尔曼滤波器的异同。
你提供的状态转移函数粒子滤片必须执行两个任务。第一,从适合您的系统的任何分布中采样过程噪声。第二,计算所有粒子到下一步的时间传播(状态假设),包括第一步中计算的过程噪声的影响。
类型vdpParticleFilterStateFcn
功能粒子= Vdpparticlefilterstatefcn(粒子)%Vdpparticlefilterstatefcn实施例的粒子%过滤功能对于MU = 1.%采样时间的普拉%滤波器%离散时间近似的尺寸为0.05秒。%%预测颗粒= VdpparticlefilterstateFCN(粒子)%%输入:%粒子 - 当前时间颗粒。具有尺寸的矩阵%[numbumofstates numberofparticles]矩阵%%输出:%预测颗粒 - 下次预测粒子的步骤%%另见粒子福特%2017 The MathWorks,Inc.%#Codegen%Tage%#Codegen如果您必须包括标签%#codegen希望使用%MATLAB编码器生成代码。[numberofstates,numberofparticle] =尺寸(粒子);%时间 - 传播连续时间动态x'= f(x)的每个粒子%% euler积分,采样时间dt dt = 0.05;kk = 1:numberofparticle颗粒(:,kk)=粒子(:,kk)+ vdpstatefcn连续(粒子(:,kk))* dt;终端%在每个状态变量流程= 0.025 *眼睛上加入高斯噪声粒子=粒子+ ProcessNoise * Randn(尺寸(粒子));结束功能DXDT = VDPSTATEFCNContinuous(X)%VDPSTATEFCNContion评估MU = 1 dxdt = [x(2)的范德波孔。 (1-x(1)^2)*x(2)-x(1)]; end
你提供的状态转移函数之间是有区别的undentedkalmanfilter和粒子滤片.您用于Unspented Kalman滤波器的状态转换功能刚刚将一个状态假设的传播描述为下次步骤,而不是一组假设。此外,在过程中定义了过程噪声分布processnoise.财产的undentedkalmanfilter,只是通过其协方差。粒子滤片可以考虑需要定义更多统计属性的任意分布。这个任意分布及其参数完全定义在您提供的状态转移函数中粒子滤片.
你提供的度量可能性函数粒子滤片还必须执行两个任务。一个,从粒子计算测量假设。二,计算从所述传感器测量的每个粒子的似然,并在步骤一计算出的假设。
类型vdpExamplePFMeasurementLikelihoodFcn
function likelihood = vdpexampleepfmeasurementlikelihood dfcn (particles,measurement) % vdpexampleepfmeasurementlikelihood function % %测量是第一状态。% % likelihood = vdpparticlefiltermeasurementlikelihood dfcn (particles, measurement) % % Inputs: % particles - numberofstates -by numberofparticles矩阵,包含%粒子%输出:%可能性-一个向量与NumberOfParticles元素n %的元素是第n个粒子% %的可能性也看到extendedKalmanFilter unscentedKalmanFilter % 2017年版权MathWorks公司% # % # codegen %标签codegen必须包括如果你想用% MATLAB编码器生成代码。%确认传感器测量值为1;%测量的预期数量验证属性(测量,{'double'}, {'vector', 'numel', numberOfMeasurements},…“vdpExamplePFMeasurementLikelihoodFcn”、“测量”);%测量是第一状态。从predictedMeasurement = particles(1,:)中得到所有的测量假设;假设预测误差与实际测量误差之比服从均值为零的高斯分布,方差0.2 mu = 0;% mean sigma = 0.2 * eye(numberOfMeasurements); % variance % Use multivariate Gaussian probability density function, calculate % likelihood of each particle numParticles = size(particles,2); likelihood = zeros(numParticles,1); C = det(2*pi*sigma) ^ (-0.5); for kk=1:numParticles errorRatio = (predictedMeasurement(kk)-measurement)/predictedMeasurement(kk); v = errorRatio-mu; likelihood(kk) = C * exp(-0.5 * (v' / sigma * v) ); end end
现在构建过滤器,并用围绕平均值的1000个粒子初始化它[2;0] 0.01协方差。协方差小,因为你对猜测有很大的信心[2;0]。
pf = particleFilter (@vdpParticleFilterStateFcn @vdpExamplePFMeasurementLikelihoodFcn);初始化(pf, 1000, [2;0], 0.01*eye(2));
可选地,选择状态估计方法。这是由StateEstimationMethod财产粒子滤片,这可以占据价值'意思'(默认)或'maxweight'.什么时候StateEstimationMethod是'意思',该对象从中提取粒子的加权平均值粒子和重量属性作为国家估计。'maxweight'对应于在中选择权重值最大的粒子(状态假设)重量作为国家的估计。或者,您可以访问粒子和重量属性,并通过您选择的任意方法提取您的状态估计。
pf.stateestimationMethod.
ans = '的意思是'
粒子滤片让您指定各种重采样选项通过它ResamplingPolicy和重新制动方法特性。此示例使用过滤器中的默认设置。看看粒子滤片关于重新采样的进一步详细信息的文档。
pf.ResamplingMethod
ans = '多项'
pf.ResamplingPolicy
ANS = ParticleresamplingPolicy具有属性:Triggermethod:'比率'SamplingInterval:1 MineFfectiveParticleratio:0.5000
启动估计循环。这表示逐步到达的测量值。
% 估计xCorrectedPF = 0(大小(xTrue));为了k = 1:尺寸(xtrue,1)%使用测量y[k]来修正时间k的粒子xCorrectedPF (k) =正确(pf, yMeas (k));%过滤器更新并存储粒子[k | k],权重[k | k]%结果是X [k | k]:利用时,估计状态k,利用这个估计值是所有粒子的平均值%,因为statestimationmethod是mean。%现在,预测粒子在下一个时间步骤。这些在% next正确命令预测(PF);%过滤器更新和存储粒子[k + 1 | k]结尾
绘制粒子滤波器的状态估计:
图();次要情节(2,1,1);情节(timeVector xTrue (: 1), timeVector, xCorrectedPF (: 1), timeVector, yMeas (:));传奇('真的'那“Particlte滤波器估计”那'衡量')ylim([ - 2.6 2.6]);ylabel(“x_1”);次要情节(2,1,2);绘图(TimeVector,Xtrue(:,2),TimeVector,XcorrectPF(:,2));ylim([ - 3 1.5]);Xlabel('时间[S]');ylabel(“x_2”);
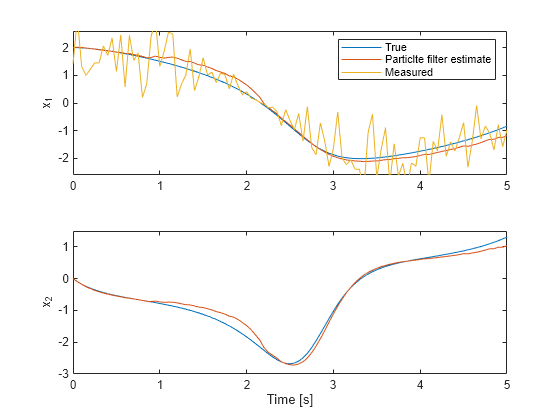
顶部图显示了真实值,粒子滤波器估计和第一状态的测量值。过滤器利用系统模型和噪声信息来在测量结果上产生改进的估计。底部图显示了第二个状态。过滤器成功地产生了良好的估计。
粒子滤波器性能的验证涉及对残差进行统计测试,类似于在该示例中以前在此示例中执行的那些,以便未选择的卡尔曼滤波结果。
总结
该示例已经示出了构造和使用Unscented Kalman滤波器的步骤和用于非线性系统的状态估计的粒子滤波器。您从嘈杂测量估计van der POL振荡器的状态,并验证了估计性能。
rmpath (fullfile (matlabroot,“例子”那“控制”那'主要的')))%删除示例数据
也可以看看
extendedKalmanFilter|粒子滤片|undentedkalmanfilter
相关的话题
您还可以从以下列表中选择一个网站: