颗粒过滤器
在线状态估计的粒子滤波对象
描述
粒子滤波器是一种递归的贝叶斯状态估计器,它使用离散粒子来近似估计状态的后验分布。当测量和将模型状态与测量关联起来的系统模型可用时,它对在线状态估计很有用。粒子滤波算法递归地计算状态估计,包括初始化、预测和校正步骤。
颗粒过滤器使用离散时间粒子滤波算法为离散时间非线性系统的在线状态估计创建对象。
考虑一个州的植物x、输入U、输出M、过程噪声W,以及测量Y.假设您可以将设备表示为非线性系统。
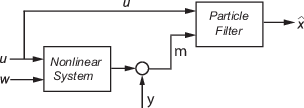
算法计算状态估计 使用你指定的状态转移和测量似然函数的非线性系统。
该软件支持任意非线性状态转金宝app换和测量模型,具有任意过程和测量噪声分布。
为了进行在线状态估计,需要建立非线性状态转移函数和测量似然函数。然后构造颗粒过滤器使用这些非线性函数创建对象。创建对象后:
属性初始化粒子
初始化命令。在下一个步骤中使用
预测命令。修正状态估计使用
对的命令。
预测步骤使用最新状态根据您提供的状态转换模型预测下一个状态。校正步骤使用当前传感器测量值来校正状态估计。该算法可以选择在状态空间中重新分布或重新采样粒子,以匹配估计状态的后验分布。每个粒子代表这些状态变量的离散状态假设。所有粒子的集合用于帮助确定状态估计。
创建
对象描述
输入参数
属性
NumStateVariables—状态变量数
[](默认)|标量
状态变量的数量,指定为标量。此属性是只读的,使用初始化.状态数是隐式的,基于粒子初始均值或状态边界的指定矩阵。
NumParticles—过滤器中使用的粒子数
[](默认)|标量
过滤器中使用的粒子数,指定为标量。每个粒子代表一个状态假设。只能通过使用初始化.
StateTransitionFcn—状态转换功能
函数句柄
状态转移函数,指定为一个函数句柄,决定了粒子在时间步之间的转移(状态假设)。这个函数计算粒子在下一个时间步,包括过程噪声,给定的粒子在一个时间步。
相反的,状态转移函数extendedKalmanFilter和非中心过滤器在给定的时间步长生成单个状态估计。
为非线性系统编写并保存状态转移函数,并在构造时将其指定为函数句柄颗粒过滤器对象。例如,如果vdpParticleFilterStateFcn.m是状态转换函数,请指定StateTransitionFcn像@vdpParticleFilterStateFcn.你也可以指定StateTransitionFcn作为匿名函数的函数句柄。
函数签名如下:
函数predictedParticles=myStateTransitionFcn(previousParticles,varargin)
这个StateTransitionFcn函数接受至少一个输入参数。第一个参数是粒子的集合previousParticles这代表了前一步的状态假设。可选的使用变长度输入宗量在函数中,您可以输入任何与预测下一个状态相关的额外参数预测,如下所示:
预测(PF,ARG1,ARG2)
如果国家定位“列”呢previousParticles是一个NumStateVariables-经过-NumParticles数组中。如果国家定位那么是“行”吗previousParticles是一个NumParticles-经过-NumStateVariables数组中。
StateTransitionFcn必须只返回一个输出,predictedParticles,它是当前时间步长的预测粒子位置集(阵列的尺寸与previousParticles).
StateTransitionFcn必须包括随机过程噪声(来自任何适合您的应用程序的分布)在predictedParticles.
要查看状态转换函数的示例,请使用国家定位属性设置为“列”,键入编辑vdpParticleFilterStateFcn在命令行。
测量可能性FCN—测量似然函数
函数句柄
测量似然函数,指定为函数句柄,用于使用传感器测量来计算粒子(状态假设)的可能性。对于每个状态假设(粒子),函数首先计算一个n元测量假设向量。然后根据传感器测量结果和测量噪声的概率分布,计算各测量假设的可能性。
相比之下,测量函数为extendedKalmanFilter和非中心过滤器接受单个状态假设并返回单个度量估计值。
您根据测量模型写入并保存测量似然函数,并使用它来构造对象。例如,如果vdpmeasurementlikelihoodfcn.m.是测量似然函数,请指定测量可能性FCN像@VDP测量可能性FCN.你也可以指定测量可能性FCN作为匿名函数的函数句柄。
函数签名如下:
function likelihood = mymeasurementlikelihood dfcn (predictedParticles,measurement,varargin)
这个测量可能性FCN函数接受至少两个输入参数。第一个参数是粒子的集合predictedParticles这代表了预测的状态假设。如果国家定位“列”呢predictedParticles是一个NumStateVariables-经过-NumParticles数组中。如果国家定位那么是“行”吗predictedParticles是一个NumParticles-经过-NumStateVariables数组中。第二个论点,测量,为n元传感器在当前时间步长的测量值。您可以使用变长度输入宗量.
这个测量可能性FCN必须只返回一个输出,可能性,是一个向量NumParticles长度,这是给定的可能性测量对于每个粒子(状态假设)。
要查看度量似然函数的示例,请键入编辑vdpMeasurementLikelihoodFcn在命令行。
IsStateVariableCircular—状态变量是否有一个循环分布
[](默认)|逻辑阵列
状态变量是否具有循环分布,指定为逻辑数组。
这是一个只读属性,使用初始化.
圆形(或角度)分布使用概率密度函数,其范围为[-pi,pi].IsStateVariableCircular行向量是NumStateVariables元素。每个向量元素指示关联的状态变量是否为循环。
重新采样策划—决定何时触发重采样的策略设置
分词抽样策略对象
确定何时触发重采样的策略设置,指定为分词抽样策略对象。
颗粒的重采样是使用颗粒过滤器估计状态的重要步骤。它使您可以根据当前状态选择粒子,而不是使用初始化时给出的粒子分布。通过持续重新采样当前估计周围的粒子,您可以更准确地跟踪和提高长期性能。
您可以根据有效粒子的数量来触发固定间隔或动态地触发重新采样。最小有效粒度是衡量电流颗粒近似值的衡量标准。通过以下方式计算有效粒子的数量:

在这个等式中,N是粒子数,并且W为每个粒子的标准化重量。得到了有效颗粒比Neff./NumParticles. 因此,有效颗粒比是所有颗粒重量的函数。粒子权重达到足够低的值后,它们对状态估计没有贡献。此低值会触发重采样,因此粒子更接近当前状态估计并具有更高的权重。
该函数的以下属性分词抽样策略对象可以修改以控制何时触发重采样:
| 财产 | 价值 | 类型 | 描述 |
|---|---|---|---|
TriggerMethod |
|
特征向量 |
它是一种根据所选值确定何时进行重采样的方法 |
SamplingInterval |
1(默认) |
标量 |
重采样之间的固定间隔,指定为标量。这个间隔决定了在哪个校正步骤期间执行重采样。例如,值为2表示每隔一秒进行一次重采样。的值 此属性仅适用于 |
MinEffectiveParticleRatio |
0.5(默认) |
标量 |
它是有效粒子数与总粒子数的最小期望比率 即有效粒子数与总粒子数之比 |
重采样法—用于粒子重采样的方法
多项式的(默认)|“残留”|“分层”|“系统”
用于粒子重采样的方法,指定为以下方法之一:
多项式的“残留”“分层”“系统”
StateEstimationMethod—用于从粒子中提取状态估计的方法
“的意思是”(默认)|“最大重量”
用于从粒子中提取状态估计的方法,指定为以下其中之一:
“的意思是”-对象根据属性输出粒子的加权平均值砝码和粒子,就像州政府估计的那样。“最大重量”-对象输出具有最高权重的粒子作为状态估计。
粒子—粒子值数组
[](默认)|大批
粒子值数组,指定为基于国家定位属性:
如果
国家定位是“行”然后粒子是一个NumParticles-经过-NumStateVariables数组中。如果
国家定位是“列”然后粒子是一个NumStateVariables-经过-NumParticles数组中。
每行或列对应于状态假设(单粒子)。
砝码—颗粒重量
[](默认)|向量
粒子权重,定义为基于的值的向量国家定位属性:
如果
国家定位是“行”然后砝码是一个NumParticles-by-1向量,其中每个权重与在同一行中的粒子相关联粒子财产。如果
国家定位是“列”然后砝码这是一张一乘的票-NumParticles向量,每种重量与同一列中的粒子相关联粒子财产。
状态—当前状态估计
[](默认)|向量
当前状态估计,定义为基于值的矢量国家定位属性:
如果
国家定位是“行”然后状态这是一张一乘的票-NumStateVariables向量如果
国家定位是“列”然后状态是一个NumStateVariables-by-1向量
状态是只读属性,并且是从粒子基于这一点StateEstimationMethod财产。指StateEstimationMethod详情请参阅状态决心,决意,决定。
状态随着StateCovariance也可以确定使用getStateEstimate.
StateCovariance—状态估计误差协方差的当前估计
NumStateVariables-经过-NumStateVariables大批(默认)|[]|大批
当前估计状态估计误差协方差,定义为NumStateVariables-经过-NumStateVariables数组中。StateCovariance是只读属性,并基于StateEstimationMethod. 如果指定不支持协方差的状态估计方法,则函数返回金宝appStateCovariance[]。
StateCovariance和状态可以确定一起使用吗getStateEstimate.
目标函数
初始化 |
初始化粒子滤波器的状态 |
预测 |
使用扩展或无迹卡尔曼滤波器或粒子滤波器在下一时间步预测状态和状态估计误差协方差 |
对的 |
正确的状态和状态估计误差协方差使用扩展或无气味卡尔曼滤波器,或粒子滤波器和测量 |
getStateEstimate |
从粒子中提取最佳状态估计和协方差 |
克隆 |
复制在线状态估计对象 |
例子
创建用于在线状态估计的粒子过滤器对象
要创建一个粒子滤波对象来估计系统的状态,请为系统创建适当的状态转移函数和测量可能性函数。
在此示例中,功能vdpparticlefilterstatefcn.描述了非线性参数为1的范德堡尔振荡器的离散时间近似。此外,它还模拟了高斯过程噪声。vdpMeasurementLikelihood函数根据第一状态的噪声测量计算粒子的可能性,假设测量噪声分布为高斯分布。
创建粒子过滤器对象。使用函数句柄为对象提供状态转换和度量可能性函数。
myPF=微粒过滤器(@vdpParticleFilterStateFcn,@vdpMeasurementLikelihoodFcn);
要初始化和估计来自构造对象的状态和状态估计误差协方差,请使用初始化,预测,对的命令。
版权所有2012 The MathWorks,Inc。。
使用粒子过滤器在线估计状态
加载van der Pol ODE数据,并指定示例时间。
vdpODEdata.mat包含使用ode45和初始条件对非线性参数mu=1的范德波尔ODE的模拟[2;0].用采样时间提取真实状态dt = 0.05.
目录(fullfile (matlabroot,'例子',“控制”,“主要”))%添加示例数据负载(“vdpODEdata.mat”,“xTrue”,“dt”)tSpan=0:dt:5;
获得测量。对于该示例,传感器测量具有标准偏差的高斯噪声的第一状态0.04.
sqrtR = 0.04;yMeas = xTrue(:,1) + sqrtR*randn(numel(tSpan),1); / /输出
创建一个粒子过滤器,并设置状态转移和测量似然函数。
myPF=微粒过滤器(@vdpParticleFilterStateFcn,@vdpMeasurementLikelihoodFcn);
初始化粒子过滤器的状态[2;0]使用单位协方差,并使用1000粒子。
初始化(myPF, 1000,(2, 0),眼(2));
选择意思状态估计和系统的重采样方法。
myPF。StateEstimationMethod =“的意思是”;mypf.resamplingmethod =“系统”;
估计状态使用对的和预测命令,并存储估计的状态。
x = 0(大小(xTrue));对于k=1:size(xTrue,1)xEst(k,:)=correct(myPF,yMeas(k));预测(myPF);终止
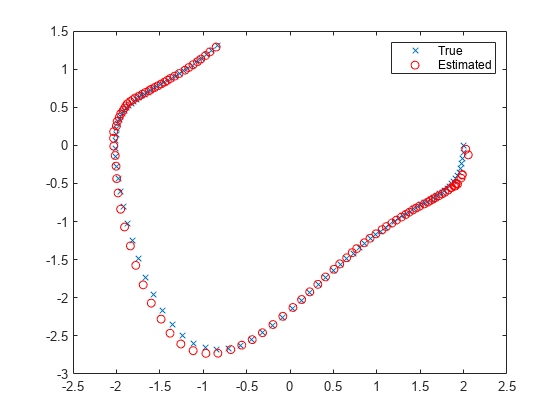
绘制结果,并比较估计的和真实的状态。
图(1)绘图(X图(:,1),X图(:,2),“x”x (: 1) x (:, 2),“罗”)传说(“真正的”,'估计的')
rmpath(fullfile(matlabroot,'例子',“控制”,“主要”))%删除示例数据
扩展功能
另见
功能
你也可以从以下列表中选择一个网站: