batchnorm
对每个信道的所有观测结果分别进行归一化
语法
描述
批处理归一化操作将每个通道的所有观测数据独立地归一化。为了加快卷积神经网络的训练速度,降低对网络初始化的敏感性,在卷积和非线性运算之间采用批归一化雷.
在归一化之后,操作通过可学习的偏移移动输入β并通过学习的比例因子来缩放它γ..
的batchnorm函数将批标准化操作应用于dlarray数据。使用dlarray通过允许您标记尺寸,对象使高维数据更容易。例如,您可以使用使用的标记对应于空间,时间,频道和批处理尺寸的维度标记“年代”,“T”,'C', 和'B'标签,分别。对于未指定的和其他维度,请使用“U”标签。为了dlarray通过特定尺寸运行的对象功能,可以通过格式化维度标签来指定维度标签dlarray对象,或使用'datomformat'选项。
请注意
在a内应用批量归一化分层图对象或层数组,使用BatchnormalizationLayer..
海底= Batchnorm(dlX,抵消,scaleFactor)dlX以及使用指定的偏移量和比例因子进行变换。
函数对“年代”(空间),“T”(时间),'B'(批量),和“U”(未指定的)尺寸dlX中的每个通道'C'(频道)尺寸独立。
对于未格式化的输入数据,请使用'datomformat'选项。
[还返回输入数据的群体平均值和方差海底,popmu.,popsigmasq.] = Batchnorm(dlX,抵消,scaleFactor)dlX.
[使用均值和方差应用批归一化操作海底,updatedMu,updatedsigmasq.] = Batchnorm(dlX,抵消,scaleFactor,亩,sigmasq.)亩和sigmasq.分别以及还返回更新的移动均值和方差统计。
使用此语法在培训期间维护均值和方差统计数据的运行值。使用最终更新值的平均值和方差以进行预测和分类。
例子
申请批正常化
创建格式化dlarray包含具有3个通道的批次128个28-×28图像的对象。指定格式'SSCB'(空间,空间,频道,批量)。
minibatchsize = 128;输入= [28 28];numchannels = 3;x = rand(输入(1),输入(2),NumChannels,Minibatchsize);dlx = dlarray(x,'SSCB');
查看输入数据的大小和格式。
大小(dlX)
ans =1×428 28 3 128
昏暗(DLX)
ans = ' SSCB '
初始化批量归一化的刻度和偏移量。对于缩放,指定一个矢量。对于偏置,请指定零的向量。
Scalefactor = =那些(NumChannels,1);offset =零(NumChannels,1);
应用批量归一化操作batchnorm函数并返回迷你批处理统计信息。
[DLY,MU,SIGMASQ] = Batchnorm(DLX,偏移,Scalefactor);
查看输出的大小和格式海底.
大小(海底)
ans =1×428 28 3 128
dim(海底)
ans = ' SSCB '
查看mini-batch均值亩.
亩
穆=3×10.4998 0.4993 0.5011
查看迷你批处理方差sigmasq..
sigmasq.
sigmaSq =3×10.0831 0.0832 0.0835
更新多批数据的平均值和方差
使用batchnorm功能,以规范化数批数据和更新后的整个数据集的统计每次规范化。
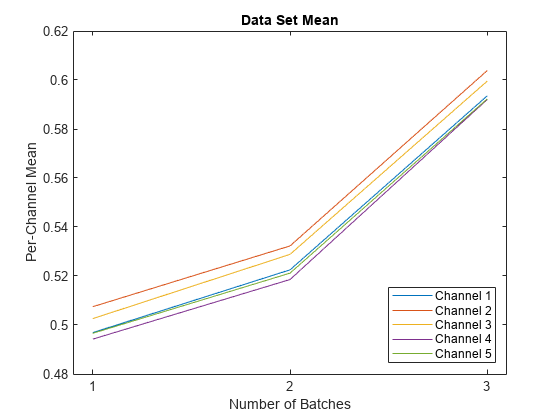
创建三个数据。数据包括10×10随机阵列,其中五个通道。每批批次包含20个观察结果。第二批次由乘法系数缩放1.5和2.5,所以数据集的平均值随着每批数据的增加而增加。
高度= 10;宽度= 10;频道= 5;观察= 20;x1 = rand(高度,宽度,频道,观察);dlx1 = dlarray(x1,'SSCB');x2 = 1.5 * rand(高度,宽度,频道,观察);dlx2 = dlarray(x2,'SSCB');X3 = 2.5 *兰德(高度、宽度、通道观测);dlX3 = dlarray (X3,'SSCB');
创建学习参数。
offset =零(频道,1);SCALE = =那些(频道,1);
归一化第一批次数据,DLX1,使用batchnorm.获得此批的均值和方差值作为输出。
[dly1,mu,sigmasq] = Batchnorm(DLX1,偏移,刻度);
标准化第二批数据,dlX2.使用亩和sigmasq.作为输入,以获得批次中数据的组合均值和方差的值dlX1和dlX2.
[dlY2, datasetMu datasetSigmaSq] = batchnorm (dlX2、抵消、规模、μsigmaSq);
正常化最终数据,dlX3.更新数据集统计信息datasetmu.和datasetSigmaSq以批量获得所有数据的组合均值和方差的值dlX1,dlX2, 和dlX3.
[dly3,dataSetmufull,datasetsigmasqfull] = batchnorm(dlx3,偏移量,刻度,datasetmu,datasetsigmasq);
每批处理归一化,请遵守每个通道的平均值的变化。
绘图([mu'; datasetmu'; datasetmufull'])图例({'频道1','频道2',通道3的,“第四频道”,“第5频道”},'地点','东南') xticks([1 2 3])'批次数量')XLIM([0.9 3.1])Ylabel(“每通道的意思”) 标题('数据集是含义')
输入参数
输出参数
算法
批处理规范化操作将元素规范化x我首先计算平均值的输入μ.B和方差σ.B2在空间、时间和观测维度上分别为每个信道。然后,它将标准化激活计算为
在哪里ε.是一个常数,在方差很小时提高数值稳定性。
为了允许具有零均值和单位方差的输入的可能性对于跟随批量归一化的操作而不是最佳,批量归一化操作进一步换档并使用转换缩放激活
哪里偏移β和规模因素γ.是在网络训练过程中更新的可学习参数。
为了在训练后与网络进行预测,批量归一化需要固定的均值和方差以标准化数据。该固定均值和方差可以在训练后计算,或者在使用运行统计计算期间近似地估计。
扩展能力
您还可以从以下列表中选择一个网站:
