创建和探索图像分类数据存储
这个示例展示了如何创建、读取和扩充用于训练深度学习网络的图像数据存储。特别地,这个例子展示了如何创建一个ImageDatastore对象,读取和提取数据存储的属性,并创建augmentedImageDatastore在训练时使用。
创建图像数据存储
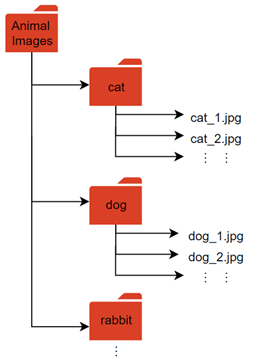
使用一个imageDatastore对象来管理无法完全装入内存的大型映像集合。在深度学习应用程序中,大量的图像集合是很常见的,这通常涉及对数千张已标记的图像进行训练。这些图像通常存储在一个文件夹中,每个类的子文件夹中都包含图像。
下载数据集
本例使用示例Food Images数据集,其中包含9个类中的978张食物照片,大小约为77mb。下载ExampleFoodImageDataset.zip文件,然后解压缩该文件。
zipFile = matlab.internal.examples.download金宝appSupportFile (“nnet”,“数据/ ExampleFoodImageDataset.zip”);filepath = fileparts (zipFile);dataFolder = fullfile (filepath,“ExampleFoodImageDataset”);解压缩(zipFile dataFolder);
这个数据集中的图像被分割到每个类的子文件夹中。

从路径中的图像及其子文件夹创建图像数据存储。使用文件夹名称作为标签名称。
foodImds = imageDatastore (dataFolder,...“IncludeSubfolders”,真的,...“LabelSource”,“foldernames”);
数据存储的属性
提取数据存储的属性。
找出观察的总数。这个数据集有978个观察结果,分为9类。
numObs =长度(foodImds.Labels)
numObs = 978
找出每节课的观察次数。你可以看到,这个数据集不包含相同数量的观察在每个类。
numObsPerClass = countEachLabel (foodImds)
numObsPerClass =9×2表标签数_____________ _____凯撒沙拉26卡普莱沙拉15法国薯条181希腊沙拉24汉堡238热狗31披萨299生鱼片40寿司124
您还可以使用直方图来可视化类标签的分布。
直方图(foodImds.Labels)组(gca,“TickLabelInterpreter”,“没有”)

探索数据存储
通过查看数据存储中随机选择的图像,检查数据是否符合预期。
numObsToShow = 8;idx = randperm (numObs numObsToShow);imshow (imtile (foodImds.Files (idx),“GridSize”(2 - 4),“ThumbnailSize”100年[100]))

您还可以查看属于特定类的图像。
类=“披萨”;idxClass =找到(foodImds。标签= =类);idx = randsample (idxClass numObsToShow);imshow (imtile (foodImds.Files (idx),“GridSize”(2 - 4),“ThumbnailSize”100年[100]));


要更仔细地查看数据存储或文件夹中的单个图像,请使用图片浏览器(图像处理工具箱)应用程序。
图像增强
增强使您能够训练网络对图像数据的畸变保持不变。例如,可以向输入图像添加随机旋转,使网络对旋转的存在保持不变。一个augmentedImageDatastore对象提供了一种方便的方法,将有限的增强集应用于二维图像的分类问题。
定义一个扩充方案。该方案采用[- 90,90]度之间的随机旋转和[1,2]之间的随机缩放。扩展后的数据存储会自动调整图像的大小inputSize在训练价值。
imageAugmenter = imageDataAugmenter (...“RandRotation”(-90 90),...“RandScale”[1, 2]);inputSize = [100 100];
利用扩充方案,定义扩充后的图像数据存储。
augFoodImds = augmentedImageDatastore (inputSize foodImds,...“DataAugmentation”, imageAugmenter);
扩充的数据存储包含与原始图像数据存储相同数量的图像。
augFoodImds。NumObservations
ans = 978
当您使用增广图像数据存储作为训练图像的来源时,数据存储会随机扰动每个epoch的训练数据,其中epoch是训练算法对整个训练数据集的完整遍历。因此,每个epoch使用的数据集略有不同,但每个epoch中训练图像的实际数量没有变化。
可视化增强数据
可视化您希望用于训练网络的增强图像数据。
洗牌的数据存储。
augFoodImds = shuffle (augFoodImds);
的augmentedImageDatastore对象在读取数据存储时应用转换,并且不将转换后的图像存储在内存中。因此,每次您读取相同的图像时,您会看到定义的增强的随机组合。
使用读函数读取扩充数据存储的子集。
subset1 =阅读(augFoodImds);
在调用read之前将数据存储重置为其状态,并再次读取数据存储的一个子集。
重置(augFoodImds) subset2 = read(augFoodImds);
显示增强图像的两个子集。
imshow (imtile (subset1.input,“GridSize”, (2 - 4)))

imshow (imtile (subset2.input,“GridSize”, (2 - 4)))

您可以看到,这两个实例都显示了具有不同转换的相同图像。在深度学习应用程序中,将变换应用于图像是很有用的,因为您可以在图像的随机改变版本上训练网络。这样做会使网络接触到该类图像的不同变体,并使它能够学习对图像进行分类,即使它们具有不同的视觉属性。
创建数据存储对象后,使用深层网络设计师应用程序或trainNetwork函数来训练图像分类网络。例如,请参见使用预训练网络进行迁移学习。
有关深度学习应用程序预处理图像的更多信息,请参见深度学习的图像预处理。您还可以应用更高级的增强,如亮度或饱和度的变化级别,通过使用变换和结合功能。有关更多信息,请参见用于深度学习的数据存储。
另请参阅
trainNetwork|深层网络设计师|augmentedImageDatastore|imageDatastore
相关的话题
你也可以从以下列表中选择一个网站:
