深度学习的数据集
使用这些数据集以开始使用深度学习应用程序。
图像数据集
| 数据集 | 描述 | 任务 |
|---|---|---|
数字
|
数字数据集由10,000张合成的手写数字灰度图像组成。每个图像是28 × 28像素,并有一个相关的标签表示图像所代表的数字(0-9)。每个图像都被旋转了一定的角度。当以数组形式加载图像时,还可以加载图像的旋转角度。 属性将数字数据加载为内存中的数字数组 [xtrain,ytrain,anglestrain] = Digittrain4darraydata;[xtest,ytest,anglestest] = digittest4darraydata; 有关显示如何处理深度学习的这些数据的示例,请参阅监控深度学习训练进展和火车回归卷积神经网络. |
图像分类和图像回归 |
控件将数字数据加载为图像数据存储 dataFolder = fullfile (toolboxdir (“nnet”),'nndemos',“nndatasets”,“DigitDataset”);imds = imagedataStore(DataFolder,......“IncludeSubfolders”,真的,.......“LabelSource”,'foldernames'); 有关如何处理这些数据进行深度学习的示例,请参见创建简单的深度学习网络分类. |
图像分类 | |
MNIST
(代表) |
MNIST数据集由70,000个手写数字组成,分别分为60,000张和10,000张图像的训练和测试分区。每个图像是28 × 28像素,并有一个相关的标签表示图像所代表的数字(0-9)。 下载MNIST文件http://yann.lecun.com/exdb/mnist/并将数据加载到工作区中。要将数据从文件加载为MATLAB阵列,请将文件放在工作目录中,然后使用辅助功能 在媒介=目录(fullfile (matlabroot“例子”,“nnet”,“主要”));filenameImagesTrain =“train-images-idx3-ubyte.gz”;filenameLabelsTrain =“train-labels-idx1-ubyte.gz”;filenameImagesTest =“t10k-images-idx3-ubyte.gz”;filenameLabelsTest =“t10k-labels-idx1-ubyte.gz”;xtrain = processimagesmnist(filenameimagestain);Ytrain = processlabelsmnist(filenamelabelstrain);xtest = processimagesmnist(filenameimagistest);ytest = processlabelsmnist(filenamelabelstest); 有关如何处理这些数据进行深度学习的示例,请参见训练变分自动编码器(VAE)生成图像. 若要恢复路径,请使用 路径(媒介); |
图像分类 |
Omniglot
|
Omniglot数据集包含50个字母的字符集,分为30套进行训练和20套进行测试。每个字母都包含许多字符,从14个用于Ojibwe(加拿大原始音节)到55 for tifinagh。最后,每个角色都有20个手写观察。 下载并提取Omniglot数据集[1]从https://github.com/brendenlake/omniglot.集 downloadfolder = tempdir;URL =.“https://github.com/brendenlake/omniglot/raw/master/python”;urlTrain = url +“/images_background.zip”;urlTest = url +“/ images_evaluation.zip”;filenameTrain = fullfile (downloadFolder,“images_background.zip”);filenameTest = fullfile (downloadFolder,“images_evaluation.zip”);datafoldertrain = fullfile(downloadlefolder,“images_background”);datafoldertest = fullfile(DownloadFolder,“images_evaluation”);如果~存在(dataFolderTrain“dir”)流(下载Omniglot训练数据集(4.5 MB)) websave (filenameTrain urlTrain);解压缩(filenameTrain downloadFolder);流(“完成。\ n”)结束如果~存在(dataFolderTest“dir”)流(“下载Omniglot测试数据(3.2 MB)…”) websave (filenameTest urlTest);解压缩(filenameTest downloadFolder);流(“完成。\ n”)结束 要将训练和测试数据加载为图像数据存储,请使用 imdsTrain = imageDatastore (dataFolderTrain,......“IncludeSubfolders”,真的,......“LabelSource”,“没有”);files = imdstrain.files;部分=分裂(文件、filesep);标签=加入(零件(:,(结束-2):(结束-1)),“_”);imdsTrain。标签= categorical(labels); imdsTest = imageDatastore(dataFolderTest,......“IncludeSubfolders”,真的,......“LabelSource”,“没有”);文件= imdsTest.Files;部分=分裂(文件、filesep);标签=加入(零件(:,(结束-2):(结束-1)),“_”);imdsTest。标签= categorical(labels); 有关如何处理这些数据进行深度学习的示例,请参见训练一个暹罗网络来比较图像. |
图像相似度 |
花卉
|
鲜花数据集包含属于五类的3670张花(黛西,蒲公英,玫瑰,向日葵,郁金香). 下载并提取Flowers数据集[2]从http://download.tensorflow.org/example_images/Flower_Photos.Tgz..数据集大约是218 MB。根据你的互联网连接,下载过程可能需要一些时间。集 URL =.“http://download.tensorflow.org/example_images/flower_photos.tgz”;downloadfolder = tempdir;文件名= fullfile (downloadFolder,“flower_dataset.tgz”);dataFolder = fullfile (downloadFolder,“flower_photos”);如果~存在(dataFolder“dir”)流("下载花卉数据集(218mb)…") websave(文件名,url);解压(文件名,downloadFolder)流(“完成。\ n”)结束 控件将数据加载为图像数据存储 imds = imagedataStore(DataFolder,......“IncludeSubfolders”,真的,......“LabelSource”,'foldernames'); 有关如何处理这些数据进行深度学习的示例,请参见训练生成对抗网络(GAN). |
图像分类 |
例如食物图片
|
食物图片样本数据集包含9个类别的978张食物图片(caeser_salad.,卡普雷塞沙拉,french_fries,greek_salad,汉堡,hot_dog,披萨,生鱼片,寿司). 属性下载Example Food Images数据集 流(“下载示例食品图像数据集(77 MB)......”) filename = matlab.internal.examples.download金宝appSupportFile(“nnet”,......“数据/ ExampleFoodImageDataset.zip”);流(“完成。\ n”)filepath = fileparts(文件名);datafolder = fullfile(filepath,“ExampleFoodImageDataset”);解压缩(文件名,dataFolder); 有关如何处理这些数据进行深度学习的示例,请参见使用tsne查看网络行为. |
图像分类 |
CIFAR-10
(代表) |
CIFAR-10数据集包含60,000张32 × 32像素大小的彩色图像,属于10类(飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船,卡车). 每个类有6000个图像,数据集被分成一个培训集,其中50,000个图像和一个有10,000个图像的测试集。该数据集是用于测试新图像分类模型的最广泛使用的数据集之一。 下载并提取CIFAR-10数据集[7]从https://www.cs.toronto.edu/%7Ekriz/cifar-10-matlab.tar.gz.数据集约为175 MB。根据你的网络连接,下载过程可能需要一些时间。集 URL =.“https://www.cs.toronto.edu/ ~ kriz / cifar-10-matlab.tar.gz”;downloadfolder = tempdir;文件名= fullfile (downloadFolder,“cifar-10-matlab.tar.gz”);dataFolder = fullfile (downloadFolder,“cifar-10-batches-mat”);如果~存在(dataFolder“dir”)流(“下载CiFar-10数据集(175 MB)......”);websave(文件名、url);解压(文件名,downloadFolder);流(“完成。\ n”)结束 loadCIFARData,在本例中使用用于图像分类的列车剩余网络.在媒介=目录(fullfile (matlabroot“例子”,“nnet”,“主要”));[XTrain, YTrain XValidation YValidation] = loadCIFARData (downloadFolder); 有关如何处理这些数据进行深度学习的示例,请参见用于图像分类的列车剩余网络. 若要恢复路径,请使用 路径(媒介); |
图像分类 |
Mathworks.®营销上
|
这是一个包含75张MathWorks商品图像的小数据集,属于五个不同的类(帽,多维数据集,打牌,螺丝刀,火炬).您可以使用这个数据集快速尝试迁移学习和图像分类。 图像尺寸为227-×227-by-3。 提取MathWorks Merch数据集。 文件名=“MerchData.zip”;datafolder = fullfile(tempdir,“MerchData”);如果~存在(dataFolder“dir”)解压缩(Filename,Tempdir);结束 控件将数据加载为图像数据存储 imds = imagedataStore(DataFolder,......“IncludeSubfolders”,真的,.......“LabelSource”,'foldernames'); 有关显示如何处理深度学习的这些数据的示例,请参阅开始迁移学习和训练深度学习网络对新图像进行分类. |
图像分类 |
Camvid.
|
CamVid数据集是一个图像集合,其中包含从正在驾驶的汽车获得的街道视图。该数据集对训练网络非常有用,用于执行图像的语义分割,并为32个语义类提供像素级标签,包括车,行人,路. 这些图像的尺寸是720 × 960 × 3。 下载并提取CamVid数据集[8]从http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData.数据集大约是573 MB。根据你的互联网连接,下载过程可能需要一些时间。集 downloadfolder = tempdir;URL =.“http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData”URLIMAGES = URL +“/文件/ 701 _stillsraw_full.zip”;urlLabels = url +“/数据/ LabeledApproved_full.zip”;dataFolder = fullfile (downloadFolder,“CamVid”);dataFolderImages = fullfile (dataFolder,“图片”);dataFolderLabels = fullfile (dataFolder,“标签”);filenameLabels = fullfile(datafolder,“labels.zip”);filenameImages = fullfile (dataFolder,“images.zip”);如果〜存在(FilenameLabels,'文件') | | ~存在(imagesZip'文件'mkdir (dataFolder)流("下载CamVid数据集图像(557mb)…");websave (filenameImages urlImages);解压缩(filenameImages dataFolderImages);流(“完成。\ n”)流(“下载Camvid数据集标签(16 MB)......”);websave (filenameLabels urlLabels);解压缩(filenameLabels dataFolderLabels);流(“完成。\ n”)结束 属性将数据加载为像素标签数据存储 在媒介=目录(fullfile (matlabroot“例子”,“deeplearning_shared”,“主要”));imd = imageDatastore (dataFolderImages,“IncludeSubfolders”,真正的);类= [“天空”“建筑”“极”“路”“路面”“树”......“signsymbol”“篱笆”“汽车”“行人”“自行车”];labelIDs = camvidPixelLabelIDs;pxds = pixelLabelDatastore (dataFolderLabels、类labelIDs); 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的语义分割. 若要恢复路径,请使用 路径(媒介); |
语义分割 |
车辆
|
车辆数据集由295个图像组成,其中包含一个或两个已标记的车辆实例。这个小数据集对于探索YOLO-v2训练过程很有用,但在实践中,需要更多标记的图像来训练一个健壮的检测器。 这些图像的尺寸是720 × 960 × 3。 提取车辆数据集。集 文件名='车辆ledatasetimages.zip';datafolder = fullfile(tempdir,“vehicleImages”);如果~存在(dataFolder“dir”)解压缩(Filename,Tempdir);结束 从提取的MAT文件中加载文件名和边界框表的数据集,并将文件名转换为绝对文件路径。 data = load(“vehicleDatasetGroundTruth.mat”);vehicleDataset = data.vehicleDataset;vehicleDataset。imageFilename = fullfile (tempdir vehicleDataset.imageFilename);
控件创建包含图像的图像数据存储和包含边界框的框标签数据存储 filenamesImages = vehicleDataset.imageFilename;tblBoxes = vehicleDataset (:,'车辆');imd = imageDatastore (filenamesImages);建筑物= boxLabelDatastore (tblBoxes);cd =结合(imd,建筑物);
有关如何处理这些数据进行深度学习的示例,请参见使用YOLO v2进行对象检测. |
对象检测 |
rit-18.
|
rit18数据集包含由一架无人机在纽约州哈姆林海滩州立公园上空捕获的图像数据。数据包含有标签的训练、验证和测试集,包含18个对象类标签,包括路标,树,建筑. 下载rit18数据集[9]从https://www.cis.rit.edu/%7Ermk6217/rit18_data.mat.数据集约为3gb。根据你的网络连接,下载过程可能需要一些时间。集 downloadfolder = tempdir;URL =.'http://www.cis.rit.edu/~rmk6217/rit18_data.mat';文件名= fullfile (downloadFolder,“rit18_data.mat”);如果~存在(文件名,'文件')流(“下载哈姆林海滩数据集(3gb)…”);websave(文件名、url);流(“完成。\ n”)结束 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的多光谱图像语义分割. |
语义分割 |
有钱的孩子
|
BraTS数据集包含脑肿瘤的MRI扫描,即神经胶质瘤,这是最常见的原发性脑恶性肿瘤。 该数据集包含750个4-D卷,每个卷代表一堆3-D图像。每个4-D体块的尺寸为240 × 240 × 155 × 4,其中前三个维度对应于一个3-D体块图像的高度、宽度和深度。第四维对应不同的扫描方式。数据集分为484个带有体素标签的训练卷和266个测试卷。 创建一个目录来存储BraTS数据集[10]. datafolder = fullfile(tempdir,“小鬼”);如果~存在(dataFolder“dir”mkdir (dataFolder);结束 从中下载BRATS数据医学分割十项全能点击“下载数据”链接。下载“task01_braintumor .tar”文件。数据集约为7gb。根据你的网络连接,下载过程可能需要一些时间。 将tar文件提取到由此指定的目录中 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习的3-D脑肿瘤分割. |
语义分割 |
Camelyon16
|
Camelyon16挑战的数据包含来自两个独立来源的400个淋巴结WSIs,分为270张训练图像和130张测试图像。WSIs以带有11级金字塔结构的剥离格式作为TIF文件存储。 训练数据集由159张正常淋巴结WSIs和111张肿瘤淋巴结与健康组织的全片WSIs组成。通常,肿瘤组织只是健康组织的一小部分。病灶边界的地面真坐标伴随肿瘤图像。 创建目录以存储CAMELYON16数据集[11]. dataFolderTrain = fullfile (tempdir,“Camelyon16”,“培训”);dataFolderNormalTrain = fullfile (dataFolderTrain,“正常”);dataFolderTumorTrain = fullfile (dataFolderTrain,“肿瘤”);dataFolderAnnotationsTrain = fullfile (dataFolderTrain,“lesion_annotations”);如果~存在(dataFolderTrain“dir”mkdir (dataFolderTrain);mkdir (dataFolderNormalTrain);mkdir (dataFolderTumorTrain);mkdir (dataFolderAnnotationsTrain);结束 从下面下载Camelyon16数据集Camelyon17点击第一个“CAMELYON16数据集”链接。打开“training”目录,然后按照以下步骤操作:
数据集是约2 GB。根据你的网络连接,下载过程可能需要一些时间。 有关如何处理这些数据进行深度学习的示例,请参见使用BlockEdimage和深度学习分类大型多分辨率图像. |
图像分类(大图像) |
上下文中的通用对象(COCO)
(代表) |
COCO 2014列车图像数据集由82,783幅图像组成。注释数据包含至少五个对应于每个图像的标题。 创建用于存储COCO数据集的目录。 datafolder = fullfile(tempdir,“可可”);如果~存在(dataFolder“dir”mkdir (dataFolder);结束 下载并提取COCO 2014火车图片和说明https://cocodataset.org/#download分别点击“2014列车图片”和“2014列车/Val标注”链接。将数据保存到指定的文件夹中 从文件中提取标题 文件名= fullfile (dataFolder,“annotations_trainval2014”,“注释”,......“captions_train2014.json”);str = fileread(文件名);data = jsondecode (str); 的 有关如何处理这些数据进行深度学习的示例,请参见使用注意力的图像说明. |
图像字幕 |
IAPR TC-12
(代表) |
IAPR TC-12基准[12]由20,000张静止的自然图像组成。数据集包括人、动物、城市等的照片。数据文件大小约为1.8 GB。 下载IAPR TC-12数据集。 dataDir = fullfile (tempdir,“iaprtc12”);URL =.“http://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz”;如果~存在(dataDir“dir”)流('正在下载IAPR TC-12数据集(1.8 GB)…\n');试一试解压(url, dataDir);抓%在某些Windows机器上,.tgz的untar命令错误%文件。重命名.tg并再试一次。文件名= fullfile (tempdir,'iaprtc12.tg');websave(文件名、url);解压(文件名,dataDir);结束流(“做。\ n \ n”);结束 控件将数据加载为图像数据存储 imageageR = fullfile(datadir,“图片”) ext = {'.jpg','.bmp',“使用”};imds = imageageataStore(Imagedir,......“IncludeSubfolders”,真的,......“FileExtensions”ext); 有关如何处理这些数据进行深度学习的示例,请参见单幅图像超分辨率使用深度学习. |
Image-to-image回归 |
苏黎世原始到RGB
|
苏黎世RAW到RGB数据集[13]包含大小为448 × 448的48043对空间注册的RAW和RGB训练图像patch。数据集包含两个独立的测试集。一个测试集包含1,204对空间注册的RAW和RGB图像patch,大小为448 × 448。另一个测试集由未注册的全分辨率RAW和RGB图像组成。数据集大小为22gb。 创建一个目录来存储苏黎世RAW到RGB数据集。 imageDir = fullfile (tempdir,“ZurichRAWToRGB”);如果~存在(imageDir“dir”mkdir (imageDir);结束 imageDir变量。当提取成功,imageDir包含三个名为的目录full_resolution,测试,火车.< p >有关如何处理这些数据进行深度学习的示例,请参见使用深度学习开发原料摄像机处理管道. |
Image-to-image回归 |
在野外生活
|
Wild数据集[14]包括1162张移动设备拍摄的照片,以及7张额外的训练图片。每幅图片由175个人在[1100]的范围内平均打分。数据集提供了每个图像的主观评分的平均值和标准偏差。 创建一个目录来存储LIVE In Wild数据集。 imageDir = fullfile (tempdir,“LIVEInTheWild”);如果~存在(imageDir“dir”mkdir (imageDir);结束 请按照中所列的说明下载数据集LIVE In the Wild Image Quality Challenge数据库.将数据提取到指定的目录 有关如何处理这些数据进行深度学习的示例,请参见使用神经图像评估量化图像质量. |
图像分类 |















时间序列和信号数据集
| 数据 | 描述 | 任务 |
|---|---|---|
日本的元音
|
日语元音数据集[15][16]包含预处理序列,代表来自不同说话人的日语元音的话语。
属性将日文元音数据集加载为包含数字序列的内存单元数组 [XTrain, YTrain] = japaneseVowelsTrainData;[XTest,欧美]= japaneseVowelsTestData; 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的序列分类. |
Sequence-to-label分类 |
水痘
|
水痘数据集包含单个时间序列,时间步长对应月份,数值对应病例数。输出是一个单元格数组,其中每个元素都是一个时间步骤。 控件将水痘数据作为单个数字序列加载 数据= Chickenpox_dataset;data = [data {:}];
有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的时间序列预测. |
时间系列预测 |
人类活动
|
人类活动数据集包含7个时间序列的传感器数据,这些数据来自佩戴在身上的智能手机。每个序列有三个特征,长度不同。这三个特征对应三个不同方向的加速度计读数。 加载Human Activity数据集。 dataTrain =负载('人性行为);dataTest = load('人性期末');xtrain = dataTrain.xtrain;Ytrain = DataTrain.ytrain;xtest = dataTest.xtest;ytest = dataTest.ytest; 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的序列到序列分类. |
Sequence-to-sequence分类 |
涡扇发动机退化仿真
|
每个时间序列的涡扇发动机退化仿真数据集[17]表示不同的引擎。每台发动机启动时的初始磨损程度和制造差异都是未知的。发动机在每个时间序列开始时正常工作,并在序列的某个点上出现故障。在训练集中,故障的大小不断增长,直到系统发生故障。 该数据包含一个zip压缩的文本文件,其中26列数字由空格分隔。每一行都是单个操作周期中数据的快照,每一列都是不同的变量。各列对应如下:
创建一个目录来存储涡扇发动机降级模拟数据集。 datafolder = fullfile(tempdir,“TurboOman”);如果~存在(dataFolder“dir”mkdir (dataFolder);结束 下载并提取涡扇发动机退化仿真数据集https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/. 从文件中解压缩数据 文件名=“CMAPSSData.zip”;解压缩(文件名,dataFolder)
使用helper函数加载训练和测试数据 在媒介=目录(fullfile (matlabroot“例子”,“nnet”,“主要”));filenamePredictors = fullfile (dataFolder,“train_fd001.txt”);[XTrain, YTrain] = processTurboFanDataTrain (filenamePredictors);filenamePredictors = fullfile (dataFolder,“test_FD001.txt”);filenameResponses = fullfile (dataFolder,“RUL_FD001.txt”);[XTest,欧美]= processTurboFanDataTest (filenamePredictors filenameResponses); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习的序列到序列回归. 若要恢复路径,请使用 路径(媒介); |
序列间回归,预测性维护 |
生理网2017年挑战
|
PhysioNet 2017 Challenge数据集[19]由一组专家以300赫兹采样的一组心电图记录组成,并将其分为不同类别。 下载和提取PhysioNet 2017 Challenge数据集使用 数据集约95mb。根据你的互联网连接,下载过程可能需要一些时间。 在媒介=目录(fullfile (matlabroot“例子”,“deeplearning_shared”,“主要”));ReadPhysionetData data = load(“PhysionetData.mat”信号= data.signals;标签= data.labels; 有关如何处理这些数据进行深度学习的示例,请参见利用长、短期记忆网络对心电信号进行分类. 若要恢复路径,请使用 路径(媒介); |
Sequence-to-label分类 |
田纳西州伊士曼过程(TEP)模拟
|
此数据集包括从田纳西州Eastman流程(TEP)模拟数据转换的MAT文件组成。 下载田纳西州伊斯曼流程(TEP)模拟数据集[18]从MathWorks支持文件站点(请参金宝app阅免责声明).数据集有四个组成部分:无故障训练、无故障测试、故障训练和故障测试。单独下载每个文件。 数据集约为1.7 GB。根据你的网络连接,下载过程可能需要一些时间。 流("下载TEP故障训练数据(613 MB)…"filenameFaultyTrain = matlab.internal.examples.downloadSu金宝apppportFile(“predmaint”,......'化学过程 - 故障检测数据/故障训练.MAT');流(“完成。\ n”)流(“下载TEP故障测试数据(1gb)…”)filenamefaultytest = matlab.internal.examples.DownloadS金宝appupportFile(“predmaint”,......“chemical-process-fault-detection-data / faultytesting.mat”);流(“完成。\ n”)流(“下载TEP无故障培训数据(36 MB)......”)filenamefaultfreeTrain = matlab.internal.examples.downloadS金宝appupportFile(“predmaint”,......“chemical-process-fault-detection-data / faultfreetraining.mat”);流(“完成。\ n”)流("下载TEP无故障测试数据(69mb)…") filenameFaultFreeTest = matlab.internal.examples.download金宝appSupportFile(“predmaint”,......'化学过程 - 故障检测数据/故障汇编.mat');流(“完成。\ n”) 将下载的文件加载到MATLAB中®工作区。 负载(filenameFaultyTrain);负载(filenameFaultyTest);负载(filenameFaultFreeTrain);负载(filenameFaultFreeTest); 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的化工过程故障检测. |
Sequence-to-label分类 |
生理网心电图分割
|
PhysioNet心电分割数据集[19][20]包括总共105名患者大约15分钟的心电图记录。为了获得每一个记录,检查人员将两个电极放置在病人胸部的不同位置,产生一个双通道信号。该数据库提供由自动化专家系统生成的信号区域标签。 从中下载Physoionet ECG分段数据集https://github.com/mathworks/physionet_ECG_segmentation下载ZIP文件 downloadfolder = tempdir;URL =.“https://github.com/mathworks/physionet_ECG_segmentation/raw/master/QT_Database-master.zip”;文件名= fullfile (downloadFolder,“QT_Database-master.zip”);dataFolder = fullfile (downloadFolder,“qt_database-master”);如果~存在(dataFolder“dir”)流(“下载Physionet心电分割数据集(72mb)…”) websave(文件名,url);解压缩(文件名,downloadFolder);流(“完成。\ n”)结束 解压缩将创建文件夹
load(fullfile(datafolder,“QTData.mat”)))
有关如何处理这些数据进行深度学习的示例,请参见利用深度学习的波形分割. |
序列到标签分类,波形分割 |
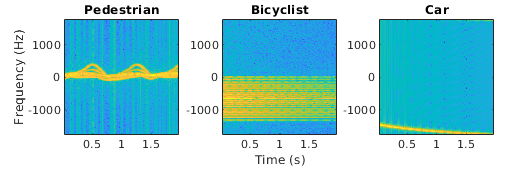
合成行人,汽车和自行车后散射
|
使用辅助函数生成合成的行人、汽车和自行车后向散射数据集 辅助函数 辅助函数 在媒介=目录(fullfile (matlabroot“例子”,“分阶段”,“主要”));numped = 1;%行人实现的数量numBic = 1;%骑自行车的人数实现numCar = 1;百分比的汽车实现数量[xPedRec, xBicRec xCarRec Tsamp] = helperBackScatterSignals (numPed, numBic numCar);(加速、T、F) = helperDopplerSignatures (xPedRec Tsamp);[SBic, ~, ~] = helperDopplerSignatures (xBicRec Tsamp);[伤疤,~,~]= helperDopplerSignatures (xCarRec Tsamp); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习的行人和自行车分类. 若要恢复路径,请使用 路径(媒介); |
Sequence-to-label分类 |
生成的波形
|
使用辅助函数生成矩形,线性调频和相位编码波形 辅助函数 在媒介=目录(fullfile (matlabroot“例子”,“分阶段”,“主要”));[wav, modType] = helperGenerateRadarWaveforms; 有关如何处理这些数据进行深度学习的示例,请参见雷达和通信波形分类使用深度学习. 若要恢复路径,请使用 路径(媒介); |
Sequence-to-label分类 |




视频数据集
| 数据 | 描述 | 任务 |
|---|---|---|
HMDB:一个大型的人体运动数据库
(代表) |
HMBD51数据集包含约2gb的视频数据,来自51类的7000个片段,例如喝,跑,俯卧撑. 从中下载并提取HMBD51数据集HMDB:一个大型的人体运动数据库.数据集是约2 GB。根据你的网络连接,下载过程可能需要一些时间。 提取RAR文件后,使用辅助功能获取文件名和视频的标签 在媒介=目录(fullfile (matlabroot“例子”,“nnet”,“主要”));datafolder = fullfile(tempdir,“hmdb51_org”);[文件,标签] = hmdb51files(datafolder); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习分类视频. 若要恢复路径,请使用 路径(媒介); |
视频分类 |

文本数据集
| 数据 | 描述 | 任务 |
|---|---|---|
工厂的报告
|
Factory Reports数据集是一个包含大约500个报告的表,这些报告具有各种属性,包括变量中的纯文本描述 从文件中读取工厂报告数据 文件名=“factoryReports.csv”;data = readtable(文件名,“TextType”,“字符串”);textData = data.Description;标签= data.Category; 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习对文本数据进行分类. |
文本分类,主题建模 |
莎士比亚的十四行诗
|
该文件 阅读文件中的莎士比亚十四行诗数据 文件名=“sonnets.txt”;textData = fileread(文件名);
十四行诗由两个空格字符缩进,并由两个换行字符分隔。使用删除缩进 textData =取代(textData,”“,"");textdata = split(textdata,[newline newline]);TextData = TextData(5:2:结束); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习生成文本. |
主题建模,文本生成 |
ArXiv的元数据
|
ArXiv API允许您访问提交的科学电子出版物的元数据https://arxiv.org.包括抽象和主题领域。有关更多信息,请参阅https://arxiv.org/help/api. 使用arXiV API从数学论文中导入一组摘要和类别标签。 URL =.“https://export.arxiv.org/oai2?verb=ListRecords”+......“集=数学”+......“&metadataPrefix = arXiv”;选择= weboptions (“超时”, 160);代码= webread (url选项); 有关如何解析返回的XML代码并导入更多记录的示例,请参见基于深度学习的多标签文本分类. |
文本分类,主题建模 |
古登堡计划的书籍
|
您可以从项目古顿贝格下载许多书籍。例如,通过Lewis Carroll从Alice的冒险经历下载来自Alice的冒险经历https://www.gutenberg.org/files/11/11-h/11-h.htm.使用 URL =.“https://www.gutenberg.org/files/11/11-h/11-h.htm”;代码= webread (url);
HTML代码中包含了相关的文本 树= htmlTree(代码);选择器=“p”;子树= FindElement(树,选择器);
属性从HTML子树中提取文本数据 textData = extractHTMLText(子树);textData (textData = ="")= [];
有关如何处理这些数据进行深度学习的示例,请参见使用深度学习逐字生成文本. |
主题建模,文本生成 |
周末更新
|
该文件 从文件中提取文本数据 文件名=“waydendupdates.xlsx”;台= readtable(文件名,“TextType”,“字符串”);textData = tbl.TextData; 有关显示如何处理此数据的示例,请参阅文本情感分析(文本分析工具箱). |
情绪分析 |
罗马数字
|
CSV文件 从CSV文件加载小数-罗马数字对 filename = fullfile(“romanNumerals.csv”);选择= detectImportOptions(文件名,......“TextType”,“字符串”,......'readvariablenames',错误的);options.variablenames = [“源”“目标”];options.variabletypes = [“细绳”“细绳”];data = readtable(文件名,选项); 有关如何处理这些数据进行深度学习的示例,请参见使用注意力的序列到序列翻译. |
Sequence-to-sequence翻译 |
财务报告
|
证券和交易委员会(SEC)允许您通过电子数据收集,分析和检索(EDGAR)API访问财务报告。有关更多信息,请参阅https://www.sec.gov/edgar/searchedgar/accessing-edgar-data.htm. 要下载此数据,请使用功能 年= 2019;QTR = 4;maxlength = 2e6;TextData = FignerePorts(年,QTR,MaxLength); 有关显示如何处理此数据的示例,请参阅生成域特异性情绪词典(文本分析工具箱). |
情绪分析 |







音频数据集
| 数据 | 描述 | 任务 |
|---|---|---|
语音命令
|
语音命令数据集[21]包含约65,000个音频文件,其中包括12个类中的1个是的,没有,在,从,以及对应未知命令和背景噪音的类。 下载并提取语音命令数据集https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.数据集约为1.4 GB。根据你的网络连接,下载过程可能需要一些时间。 集 dataFolder = tempdir;广告= audioDatastore (dataFolder,......“IncludeSubfolders”,真的,......“FileExtensions”,“wav”,......“LabelSource”,'foldernames'); 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的语音指令识别. |
音频分类,语音识别 |
Mozilla共同的声音
|
Mozilla Common Voice数据集包括语音录音和相应的文本文件。数据还包括人口统计元数据,如年龄、性别和口音。 下载并提取Mozilla公共语音数据集数据集https://voice.mozilla.org/.数据集是一个打开的数据集,这意味着它可以随时间延长。截至2019年10月,数据集约为28 GB。根据你的网络连接,下载过程可能需要一些时间。集 dataFolder = tempdir;广告= audioDatastore (fullfile (dataFolder,“剪辑”));
有关如何处理这些数据进行深度学习的示例,请参见使用GRU网络进行性别分类. |
音频分类,语音识别。 |
自由口语数字数据集
|
截止到2019年1月29日,“自由口语数字数据集”是由4名演讲者的2000段英语数字0到9的录音组成的。在这个版本中,两名讲话者的母语是美国英语,两名讲话者的母语是非英语,分别带有比利时、法国和德国口音。数据采样频率为8000 Hz。 下载自由语音数字数据集(FSDD)录音https://github.com/Jakobovski/free-spoken-digit-dataset. 集 datafolder = fullfile(tempdir,“free-spoken-digit-dataset”,“录音”);广告= audioDatastore (dataFolder); 有关如何处理这些数据进行深度学习的示例,请参见用小波散射和深度学习的口语数字识别. |
音频分类,语音识别。 |
柏林情感语言数据库
|
柏林情感语言数据库[22]含有10个演员口语的话语,旨在表达以下情绪之一:愤怒,无聊,厌恶,焦虑/恐惧,幸福,悲伤或中立。情绪是独立的。 文件名是表示说话者ID、所讲文本、情感和版本的代码。该网站包含破译密码的钥匙,以及演讲者的性别和年龄等附加信息。 下载柏林情绪演讲数据库http://emodb.bilderbar.info/index-1280.html.数据集大约是40mb。根据你的互联网连接,下载过程可能需要一些时间。 集 dataFolder = tempdir;广告= audioDatastore (fullfile (dataFolder,“wav”));
有关如何处理这些数据进行深度学习的示例,请参见语音情感认可. |
音频分类,语音识别。 |
TUT声学场景2017
|
下载并提取TUT声学场景2017数据集[23]从TUT声学场景2017,开发数据集和TUT声学场景2017,评估数据集. 该数据集由15个声学场景的10秒音频片段组成,包括公共汽车,车,图书馆. 有关如何处理这些数据进行深度学习的示例,请参见基于后期融合的声场景识别. |
声学场景分类 |



参考文献
[1] Lake, Brenden M., Ruslan Salakhutdinov, Joshua B. Tenenbaum。“通过概率程序归纳的人类层面概念学习”。科学350,不。6266(2015年12月11日):1332-38。https://doi.org/10.1126/science.aab3050。
TensorFlow团队。“花”https://www.tensorflow.org/datasets/catalog/tf_flowers
[3] Kat,郁金香、图像、https://www.flickr.com/photos/swimparallel/3455026124.知识共享许可协议(CC BY)。
Rob Bertholf [4]向日葵、图像、https://www.flickr.com/photos/robbertholf/20777358950.知识共享2.0通用许可证。
[5]帕文,玫瑰、图像、https://www.flickr.com/photos/55948751@N00.知识共享2.0通用许可证。
[6]约翰哈斯拉姆,蒲公英、图像、https://www.flickr.com/photos/foxypar4/645330051.知识共享2.0通用许可证。
[7] Krizhevsky,亚历克斯。"从微小图像中学习多层特征"硕士论文,多伦多大学,2009。https://www.cs.toronto.edu/%7Ekriz/learning-features-2009-TR.pdf.
[8]荆棘,加布里埃尔J.,Julien Fauuaryur和Roberto Cipolla。“视频中的语义对象类:高清地面真相数据库。”模式识别的字母30日,没有。2(2009年1月):88-97。https://doi.org/10.1016/j.patrec.2008.04.005
肯克尔,罗纳德,卡尔·塞尔瓦乔,克里斯托弗·卡南。用于语义分割的高分辨率多光谱数据集。ArXiv: 1703.01918 (Cs), 2017年3月6日。https://arxiv.org/abs/1703.01918
Isensee, Fabian, Philipp Kickingereder, Wolfgang Wick, Martin Bendszus和Klaus H. Maier-Hein。脑肿瘤分割和放射组学生存预测:对BRATS 2017挑战的贡献在脑损伤:胶质瘤,多发性硬化症,中风和创伤性脑损伤, Alessandro Crimi, Spyridon Bakas, Hugo Kuijf, Bjoern Menze, and Mauricio Reyes编辑,10670:287-97。瑞士Cham:施普林格International Publishing, 2018。https://doi.org/10.1007/978-3-319-75238-9_25
Ehteshami Bejnordi, Babak, Mitko Veta, Paul Johannes van Diest, Bram van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen A. W. M. van der Laak, et al.“深度学习算法检测乳腺癌女性淋巴结转移的诊断评估”。《美国医学会杂志》318年,没有。22(2017年12月12日):2199。https://doi.org/10.1001/jama.2017.14585
[12] Grubinger, M., P. Clough, H. Müller, T. Deselaers。IAPR TC-12基准:一种新的视觉信息系统评估资源。基于内容的图像检索语言资源。意大利热那亚。第五卷,2006年5月,第10页。
伊格纳托夫,安德烈,卢克·范古尔和拉杜·蒂莫夫特。“用单一的深度学习模型取代移动相机ISP。”ArXiv: 2002.05509 (Cs,套)2020年2月13日。http://arxiv.org/abs/2002.05509。项目网站.
[14] LIVE:图像和视频工程实验室。https://live.ece.utexas.edu/research/ChallengedB/Index.html..
工藤、民一、富山俊和《新报》。“利用通行区域进行多维曲线分类”。模式识别字母20,no。11-13(1999年11月):1103-11。https://doi.org/10.1016/s0167 - 8655 (99) 00077 - x
工藤、民一、富山俊和《新报》。日语元音数据集.由UCI机器学习知识库分发。https://archive.ics.uci.edu/ml/datasets/japanese+vowels.
[17] Saxena,Abhinav,Kai Goebel。“TurboOman发动机劣化模拟数据集。”NASA Ames预诊数据仓库https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/NASA艾姆斯研究中心,加州莫菲特菲尔德
Rieth, Cory A., Ben D. Amsel, Randy Tran, Maia B. Cook。用于异常检测评估的额外Tennessee Eastman过程模拟数据哈佛Dativeres.,版本1,2017。https://doi.org/10.7910/dvn/6c3jr1..
Goldberger, Ary L., Luis A. N. Amaral, Leon Glass, Jeffery M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. miietus, George B. Moody, Chung-Kang Peng,和H. Eugene Stanley。“PhysioBank, PhysioToolkit和PhysioNet:复杂生理信号新研究资源的组成部分”循环101, No. 23, 2000, pp. e215-e220。https://circ.ahajournals.org/content/101/23/e215.full
[20]拉古纳,巴勃罗,罗杰G.马克,阿里L.戈德伯格,乔治B.穆迪。心电图QT间期和其他波形间隔测量算法评估数据库。计算机在心脏病学24, 1997,第673-676页。
[21]监狱长P。“语音指令:单字语音识别的公共数据集”,2017。可以从http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权2017年谷歌。Speech Commands Dataset是在Creative Commons Attribution 4.0许可下使用的,可以在这里获得:https://creativecommons.org/licenses/by/4.0/legalcode.
[22] Burkhardt, Felix, Astrid Paeschke, Melissa A. Rolfes, Walter F. Sendlmeier和Benjamin Weiss。《德语情感语言数据库》Interspeech论文集2005.葡萄牙里斯本:国际语言传播协会,2005年。
Mesaros, Annamaria, Toni Heittola和Tuomas Virtanen。“声学场景分类:DCASE 2017挑战赛参赛作品概述。”在2018第十六届声信号增强国际研讨会(IWAENC),pp.411-415。IEEE,2018年。
另请参阅
相关的话题
你也可以从以下列表中选择一个网站:
