使用深度学习的序列到序列回归
此示例显示如何通过使用深度学习来预测引擎的剩余使用寿命(RUL)。
要培训深度神经网络以预测时间序列或序列数据的数值,可以使用长短期内存(LSTM)网络。
本例使用[1]中描述的涡扇发动机退化模拟数据集。该示例训练一个LSTM网络来预测发动机的剩余使用寿命(预测性维修),以周期为单位,给定表示发动机中各种传感器的时间序列数据。训练数据包含100台发动机的模拟时间序列数据。每个序列在长度上各不相同,并对应于一个完整的运行到故障(RTF)实例。测试数据包含100个部分序列以及每个序列结束时对应的剩余使用寿命值。
数据集包含100个培训观察和100个测试观察。
下载数据
下载并解压涡轮风扇发动机退化模拟数据集https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/[2].
TurboOMAN发动机劣化模拟数据集的每次序列都代表了一个不同的发动机。每个发动机从未知程度的初始磨损和制造变化开始。发动机正常运行在每次序列的开始时,并在序列期间的某个点在某些位置开发故障。在训练集中,故障的幅度幅度大,直到系统故障增加。
数据包含带有26列的ZIP压缩文本文件,由空格分隔。每行是在单个操作周期期间拍摄的数据的快照,每列都是不同的变量。列对应以下:
第1列 - 单元号
第2列 - 循环中的时间
列3-5 - 操作设置
列6-26 -传感器测量1-21
创建一个目录以存储TurboOman引擎劣化模拟数据集。
datafolder = fullfile(tempdir,“涡扇”);如果〜存在(DataFolder,'dir'mkdir (dataFolder);结束
下载并提取涡轮机发动机劣化模拟数据集https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/.
从文件中解压缩数据CMAPSSData.zip.
文件名=“cmapssdata.zip”;解压缩(文件名,dataFolder)
准备培训数据
使用该功能加载数据processturbofandatatrain附加到这个例子。这个函数processturbofandatatrain从filenamePredictors并返回单元格阵列XTrain和ytrain.,其中包含训练预测器和反应序列。
filenamePredictors = fullfile (dataFolder,“train_FD001.txt”);[XTrain, YTrain] = processTurboFanDataTrain (filenamePredictors);
删除带有常量值的特性
对于所有时间步骤保持不变的功能可能会对培训产生负面影响。找到具有相同最小值和最大值的数据行,然后删除行。
m = min ([XTrain {:}], [], 2);M = max ([XTrain {:}], [], 2);idxConstant = M == M;为i = 1:numel(xtrain)xtrain {i}(idxconstant,:) = [];结束
查看序列中剩余特性的个数。
numfeatures = size(xtrain {1},1)
numfeatures = 17.
正常化培训预测因子
将训练预测量归一化,使其均值和单位方差为零。为了计算所有观测值的平均值和标准差,将序列数据水平连接。
mu =均值([xtrain {:}],2);sig = std([xtrain {:}],0,2);为i = 1:numel(xtrain)xtrain {i} =(xtrain {i} - mu)./ sig;结束
剪辑响应
要从序列数据学习更多时,当引擎接近故障时,将夹在阈值150处的响应。这使得网络对待具有较高rul值的实例。
thr = 150;为i = 1:numel(YTrain) YTrain{i}(YTrain{i} >) = thr;结束
此图显示了第一个观察结果和相应的剪切响应。

准备填充数据
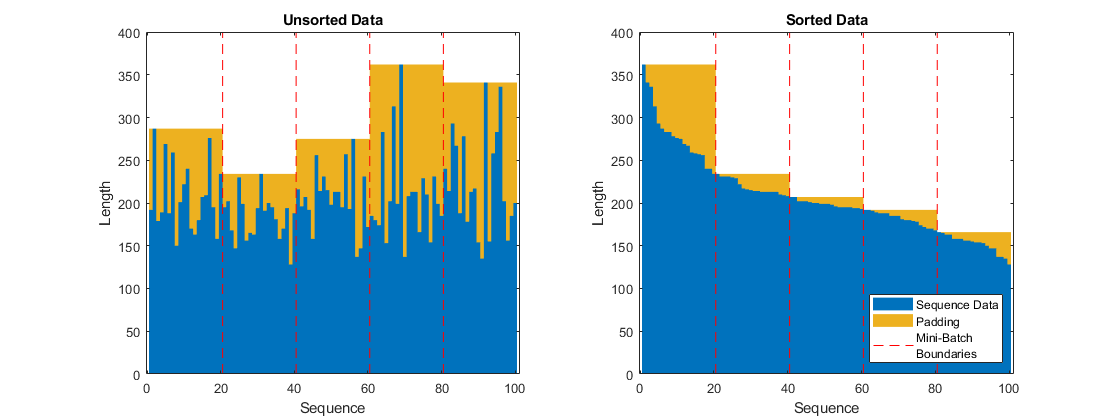
为了最小化添加到迷你批次的填充量,通过序列长度对训练数据进行排序。然后,选择迷你批量大小,均匀划分训练数据,并减少粉碎中的填充量。
按顺序长度对培训数据进行排序。
为i = 1:numel(xtrain)序列= xtrain {i};Sequencelengths(i)=大小(序列,2);结束[sequenceLengths, idx] =排序(sequenceLengths,“下降”);XTrain = XTrain(IDX);YTrain = Ytrain(IDX);
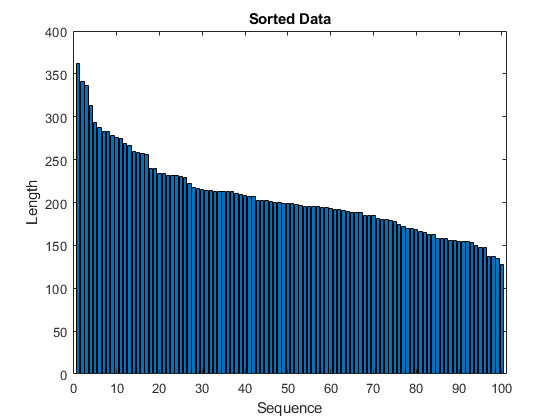
在条形图中查看排序的序列长度。
图酒吧(sequenceLengths)包含(“序列”)ylabel(“长度”) 标题(“排序数据”)
选择一个小批大小的训练数据平均分割,减少填充的数量在小批。指定小批量大小为20。该图演示了添加到未排序和已排序序列中的填充。
minibatchsize = 20;
定义网络体系结构
定义网络架构。创建LSTM网络,LSTM层包含200个隐藏单元,全连接层大小为50,dropout概率为0.5。
numResponses =大小(YTrain {1}, 1);numHiddenUnits = 200;层= [...sequenceInputLayer numFeatures lstmLayer (numHiddenUnits,'OutputMode','顺序')全连接层(50)optOutlayer(0.5)全连接列(NumResponses)回归范围];
指定培训选项。使用求解器的迷你批次批量拨打60张时期的列车“亚当”.设置学习速率为0.01。为了防止梯度爆炸,设置梯度阈值为1。要保持序列按长度排序,请设置'洗牌'来“永远”.
maxEpochs = 60;miniBatchSize = 20;选择= trainingOptions (“亚当”,...“MaxEpochs”maxEpochs,...“MiniBatchSize”,小匹马,...'italllearnrate',0.01,...'gradientthreshold',1,...'洗牌',“永远”,...“阴谋”,“训练进步”,...'verbose',0);
培训网络
训练网络使用Trainnetwork..
net = trainnetwork(xtrain,ytrain,图层,选项);
测试网络
使用该功能准备测试数据processTurboFanDataTest附加到这个例子。这个函数processTurboFanDataTest从filenamePredictors和filenamamersponses.并返回单元格阵列XTest.和ytest.,其分别包含测试预测器和响应序列。
filenamePredictors = fullfile (dataFolder,“test_fd001.txt”);filenamersponses = fullfile(datafolder,“rul_fd001.txt”);[xtest,ytest] = procesctturbofandataTest(filenamepredictors,filenamersponses);
使用恒定值删除功能IdxConstant.从训练数据计算。使用与训练数据中的相同的参数正常化测试预测器。在用于培训数据的相同阈值下剪切测试响应。
为i = 1:numel(xtest)xtest {i}(idxconstant,:) = [];xtest {i} =(xtest {i} - mu)./ sig;ytest {i}(ytest {i}> thr)= thr;结束
使用测试数据进行预测预测.要防止函数向数据添加填充,请指定mini-batch大小为1。
ypred =预测(net,xtest,“MiniBatchSize”,1);
LSTM网络一次对部分序列进行预测一次。在每个时间步骤中,网络在此时间步骤中使用该值的值,以及从上一时间步骤计算的网络状态。网络在每个预测之间更新其状态。这预测函数返回这些预测的序列。预测的最后一个元素对应于部分序列的预测RUL。
或者,您可以通过使用一次执行一次预测predictAndUpdateState.当您具有到达流的时间步骤的值时,这很有用。通常,与一次进行预测相比,在完全序列上进行预测更快。有关示例,显示如何通过在单时间步骤预测之间更新网络来预测未来时间步骤,请参阅使用深度学习的时间序列预测.
可视化绘图中的一些预测。
IDX = RANDPERM(NUMER(YPRED),4);数字为i = 1:numel(idx)子图(2,2,i)plot(ytest {idx(i)},' - ') 抓住上绘图(ypred {idx(i)},“。”) 抓住离开Ylim ([0 THR + 25]) title(“测试观察”+ idx(i))xlabel(“时间步”)ylabel(“rul”)结束传奇([“测试数据”“预料到的”],'地点','东南')
对于给定的部分序列,预测的当前RUL是预测序列的最后一个元素。计算预测的均方根误差(RMSE),并在直方图中可视化预测误差。
为i = 1:numel(ytest)ytestlast(i)= ytest {i}(结束);ypredlast(i)= ypred {i}(结束);结束图Rmse = sqrt((ypredlast - ytestlast)。^ 2))直方图(ypredlast - ytestlast)标题(“rmse =”+ rmse) ylabel (“频率”)Xlabel(“错误”)
参考
Saxena, Abhinav, Kai Goebel, Don Simon和Neil Eklund。航空发动机从运行到失效仿真的损伤扩展模型在《预后与健康管理》,2008年。2008年榜单。国际会议上,pp。1-9。IEEE,2008。
Saxena,Abhinav,Kai Goebel。“TurboOman发动机劣化模拟数据集。”美国宇航局艾姆斯预测数据仓库https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/美国宇航局艾姆斯研究中心,加州莫菲特场
另请参阅
lstmlayer.|predictAndUpdateState|sequenceInputLayer|培训选项|Trainnetwork.
相关话题
您还可以从以下列表中选择一个网站:
