使用深度学习对视频进行分类
这个例子展示了如何结合预先训练的图像分类模型和LSTM网络来创建一个视频分类网络。
创建视频分类深度学习网络:
使用预先训练的卷积神经网络(如GoogLeNet)将视频转换为特征向量序列,从每一帧中提取特征。
在序列上培训LSTM网络以预测视频标签。
通过组合来自两个网络的图层直接来组装一个网络。
下图说明了网络架构。
要将图像序列输入到网络,请使用序列输入层。
使用卷积层提取特征,即对视频的每一帧单独进行卷积操作,先使用序列折叠层,再使用卷积层。
为了恢复序列结构并将输出重塑为矢量序列,需要使用序列展开层和平坦层。
要对得到的向量序列进行分类,首先包括LSTM层,然后是输出层。

载荷净化卷积网络
将视频帧转换为特征向量,使用预先训练的网络的激活。
加载一个预先训练的GoogLeNet模型使用googlenet.函数。该功能需要深度学习工具箱™模型GoogLeNet网络金宝app支持包。如果没有安装此支金宝app持包,则该函数将提供下载链接。
netcnn = googlenet;
加载数据
从中下载HMBD51数据集HMDB:一个大型的人体运动数据库并将RAR文件提取到名为的文件夹中“hmdb51_org”.该数据集包含约2gb的视频数据,超过51类7000个片段,例如“喝”,“运行”,“shake_hands”.
提取RAR文件后,使用支持函数金宝apphmdb51Files获取视频的文件名和标签。
dataFolder =“hmdb51_org”;(文件、标签)= hmdb51Files (dataFolder);
使用读取第一个视频readVideoHelper函数,在本例的最后定义,并查看视频的大小。这个视频是H-经过-W-经过-C-经过-年代数组,H,W,C,年代是视频的高度,宽度,通道数和视频的帧数。
Idx = 1;filename =文件(IDX);视频= readVideo(文件名);大小(视频)
ans =1×4240 320 3 409
查看对应的标签。
标签(IDX)
ans =分类梳头
要查看视频,请使用im函数(需要图像处理工具箱™)。该函数期望的数据范围是[0,1],因此必须先将数据除以255。或者,您可以循环遍历单个帧并使用imshow.函数。
numframes = size(视频,4);数字为i = 1:numFrames frame = video(:,:,:,i);imshow(帧/ 255);drawnow结束
将帧转换为特征向量
通过在将视频帧输入到网络时,使用卷积网络作为特征提取器。将视频转换为特征向量的序列,其中特征向量是输出的激活函数的最后一个池层的GoogLeNet网络(“pool5-7x7_s1”).
这个图表说明了通过网络的数据流。

要读取视频数据并调整它以匹配Googlenet网络的输入大小,请使用readVideo和centerCrop辅助函数,在本例的最后定义。这个步骤可能需要很长时间来运行。将视频转换为序列后,将序列保存在mat -文件中Tempdir.文件夹。如果垫文件已存在,则从垫子文件加载序列,而无需重新调整它们。
inputSize = netCNN.Layers (1) .InputSize (1:2);layerName =“pool5-7x7_s1”;tempFile = fullfile (tempdir,“hmdb51_org.mat”);如果存在(tempfile,“文件”)负载(tempFile“序列”)其他的numFiles =元素个数(文件);序列=细胞(numFiles, 1);为i = 1:numFiles fprintf("读取文件%d…\n", i, numFiles) video = readVideo(files(i));视频= centerCrop(视频、inputSize);序列{我1}=激活(layerName netCNN、视频,“OutputAs”,“列”);结束保存(TempFile,“序列”,“-v7.3”);结束
查看前几个序列的大小。每个序列都是一个D-经过-年代数组,D是特征的数量(池化层的输出大小)和年代为视频的帧数。
序列(1:10)
ans =10×1单元阵列{1024×409单}{1024×395单}{1024×323单}{1024×246单}{1024×159单}{1024×137单}{1024×359单}{1024×191单}{1024×439单}{1024×528单}
准备训练数据
通过将数据划分为培训和验证分区并删除任何长序列来准备培训的数据。
创建培训和验证分区
分区的数据。将90%的数据分配给训练分区,10%分配给验证分区。
numObservations =元素个数(序列);idx = randperm (numObservations);N = floor(0.9 * numobations);idxTrain = idx (1: N);sequencesTrain =序列(idxTrain);labelsTrain =标签(idxTrain);idxValidation = idx (N + 1:结束);sequencesValidation =序列(idxValidation);labelsValidation =标签(idxValidation);
删除长序列
比网络中的典型序列长得多的序列可以将大量填充引入训练过程中。填充太多可能会对分类准确性产生负面影响。
获取训练数据的序列长度,并将其可视化为训练数据的直方图。
numobservationstrain = numel(sequencestain);Sequencelengths =零(1,numobservationstrain);为i = 1:numObservationsTrain sequence = sequencesTrain{i};sequenceLengths (i) =(序列,2)大小;结束图直方图(sequenceLengths)标题(“序列长度”)包含(“序列长度”) ylabel (“频率”)
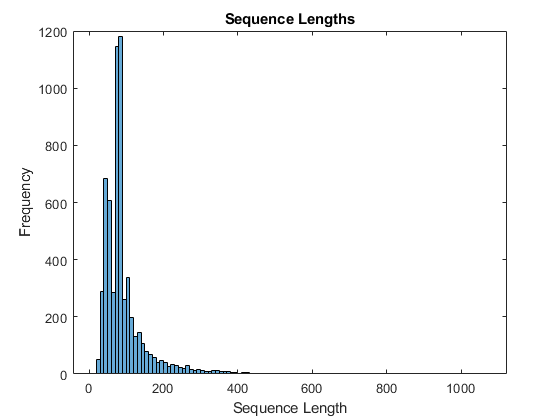
只有少数序列有超过400个时间步。为了提高分类精度,去除时间步长超过400步的训练序列及其相应的标签。
maxlength = 400;idx = sequencelength> maxlength;Sequencestain(IDX)= [];Labelstrain(IDX)= [];
创建LSTM网络
接下来,创建一个LSTM网络,可以对表示视频的特征向量序列进行分类。
定义LSTM网络架构。指定以下网络层。
一个序列输入层,输入大小对应于特征向量的特征维度
一个Bilstm层,其中2000个隐藏单元,之后具有丢弃层。通过设置序列仅输出一个标签
'OutputMode'选项BiLSTM层“最后一次”一种输出大小与类数对应的全连接层,一种软最大层和一种分类层。
numfeatures = size(Sequencestain {1},1);numclasses = numel(类别(labelstrain));图层= [sequentInputlayer(numfeatures,“名字”,“序列”) bilstmLayer (2000,'OutputMode',“最后一次”,“名字”,'bilstm')DropoutLayer(0.5,“名字”,'降低') fullyConnectedLayer (numClasses“名字”,“俱乐部”) softmaxLayer (“名字”,'softmax') classificationLayer (“名字”,“分类”));
指定培训选项
使用使用的培训选项trainingOptions函数。
设置小批量16,初始学习率为0.0001,梯度阈值为2(防止梯度爆炸)。
每个纪元都洗牌数据。
每个epoch验证一次网络。
显示绘图中的培训进度并抑制冗长输出。
miniBatchSize = 16;numObservations =元素个数(sequencesTrain);numIterationsPerEpoch = floor(nummobations / miniBatchSize);选择= trainingOptions ('亚当',…'minibatchsize',小匹马,…“InitialLearnRate”1的军医,…“GradientThreshold”2,…'洗牌',“every-epoch”,…“ValidationData”{sequencesValidation, labelsValidation},…“ValidationFrequency”,numiterationsperepoch,…“阴谋”,“训练进步”,…'verbose'、假);
火车LSTM网络
训练网络使用trainNetwork函数。这可能需要很长时间运行。
[netlstm,Info] = Trainnetwork(Sequencestrain,Labelstrain,图层,选项);

计算网络在验证集上的分类精度。使用与培训选项相同的小批量。
YPred =分类(netLSTM sequencesValidation,'minibatchsize',小匹匹匹匹配);yvalidation = labelsvalidation;精度=均值(ypred == yvalidation)
精度= 0.6647
组装视频分类网络
要创建一个直接对视频进行分类的网络,可以使用两个创建的网络的层来组装一个网络。利用卷积网络的层将视频转换为向量序列,利用LSTM网络的层对向量序列进行分类。
下图说明了网络架构。
要将图像序列输入到网络,请使用序列输入层。
使用卷积层提取特征,即对视频的每一帧单独进行卷积操作,先使用序列折叠层,再使用卷积层。
为了恢复序列结构并将输出重塑为矢量序列,需要使用序列展开层和平坦层。
要对得到的向量序列进行分类,首先包括LSTM层,然后是输出层。

添加回旋的层
首先,创建Googlenet网络的图层图。
cnnLayers = layerGraph (netCNN);
删除输入层(“数据”)和用于激活的池化层之后的层(“pool5-drop_7x7_s1”,“损失3分类器”,“概率”,“输出”).
LayerNames = [“数据”“pool5-drop_7x7_s1”“损失3分类器”“概率”“输出”];cnnLayers = removeLayers (cnnLayers layerNames);
添加序列输入层
创建一个序列输入层,接受包含与GoogLeNet网络输入大小相同的图像序列。要使用与GoogLeNet网络相同的平均图像对图像进行归一化,请设置'正常化'选项的顺序输入层“zerocenter”和“的意思是”选项为GoogLeNet输入层的平均图像。
inputSize = netCNN.Layers (1) .InputSize (1:2);averageImage = netCNN.Layers (1) .Mean;inputLayer = sequenceInputLayer([inputSize 3],…'正常化',“zerocenter”,…“的意思是”averageImage,…“名字”,“输入”);
将序列输入层添加到层图中。为了将卷积层独立应用于序列图像,在序列输入层和卷积层之间加入序列折叠层,去除图像序列的序列结构。将序列折叠层的输出连接到第一卷积层的输入(“conv1-7x7_s2”).
图层= [InputLayer SequenceFoldingLayer(“名字”,“折”));Lgraph = Addlayers(CNNLayers,层);lgraph = connectLayers (lgraph,“折/”,“conv1-7x7_s2”);
添加LSTM层
通过去除LSTM网络的序列输入层,将LSTM层添加到层图中。为了恢复被序列折叠层删除的序列结构,在卷积层之后再加一个序列展开层。LSTM层期望向量序列。为了将序列展开层的输出重塑为矢量序列,在序列展开层之后再添加一个flatten层。
从LSTM网络中取出图层并删除序列输入层。
lstmLayers = netLSTM.Layers;lstmLayers (1) = [];
将序列折叠层、flatten层、LSTM层添加到层图中。连接最后一个卷积层(“pool5-7x7_s1”)到序列展开层的输入(“展开/在”).
图层= [sexthunfoldinglayer(“名字”,“展开”)Flattenlayer(“名字”,“平”) lstmLayers);lgraph = addLayers (lgraph层);lgraph = connectLayers (lgraph,“pool5-7x7_s1”,“展开/”);
要使展开层恢复序列结构,请连接“miniBatchSize”序列折叠层的输出到序列展开层的相应输入。
lgraph = connectLayers (lgraph,“折叠/小纤维”,“展开/小纤维”);
组装网络
检查网络是否有效使用分析函数。
analyzeNetwork (lgraph)
组装网络,以便它已准备好使用预测assembleNetwork函数。
净= assembleNetwork (lgraph)
net =具有属性的dagnetwork:图层:[148×1 nnet.cnn.layer.layer]连接:[175×2表]
使用新数据进行分类
阅读并中间裁剪视频“pushup.mp4”使用与之前相同的步骤。
文件名=“pushup.mp4”;视频= readVideo(文件名);
要查看视频,请使用im函数(需要图像处理工具箱)。该函数期望的数据范围是[0,1],因此必须先将数据除以255。或者,您可以循环遍历单个帧并使用imshow.函数。
numframes = size(视频,4);数字为i = 1:numFrames frame = video(:,:,:,i);imshow(帧/ 255);drawnow结束

使用组装网络对视频进行分类。的分类函数预计包含输入视频的单元格数组,因此您必须输入包含该视频的1×1个单元格数组。
视频= centerCrop(视频、inputSize);{视频}YPred =分类(净)
YPred =分类俯卧撑
辅助功能
的readVideo函数读取视频文件名并返回一个H-经过-W-经过-C -经过-年代数组,H,W,C,年代是视频的高度,宽度,通道数和视频的帧数。
函数视频= readVideo(filename) vr = VideoReader(filename);H = vr.Height;W = vr.Width;C = 3;%预分配视频阵列numFrames =地板(虚拟现实。Duration * vr.FrameRate); video = zeros(H,W,C,numFrames);%阅读框架我= 0;而hasFrame(vr) i = i + 1;视频(::,:,我)= readFrame (vr);结束%删除未分配的框架如果尺寸(视频,4)> i视频(:,:,:,i + 1:结束)= [];结束结束
的centerCrop函数可以裁剪视频的最长边并调整其大小输入.
函数sz = size(video); / /视频大小如果深圳(1)<深圳(2)%视频是横向的IDX =楼层((SZ(2) - SZ(1))/ 2);视频(:,1 :( idx-1),:,:) = [];视频(:,(sz(1)+1):结束,:,:) = [];eleesif.深圳(2)<深圳(1)%视频是纵向的IDX =楼层((SZ(1) - SZ(2))/ 2);视频(1 :( idx-1),:,:,:) = [];视频((sz(2)+1):结束,::,:) = [];结束videoResized = imresize(视频、inputSize (1:2));结束
另请参阅
flattenLayer|lstmlayer.|sequenceFoldingLayer|sequenceInputLayer|sequenceUnfoldingLayer|trainingOptions|trainNetwork
相关的话题
你也可以从以下列表中选择一个网站:
