列车网络与数字功能
这个例子展示了如何创建和训练一个简单的神经网络用于深度学习特征数据分类。
如果您有一组数字特征数据(例如一组没有空间或时间维度的数字数据),那么您可以使用特征输入层训练一个深度学习网络。有关如何训练网络进行图像分类的示例,请参见创建简单的深度学习网络分类.
此示例示出了如何训练网络以给定的数字传感器读数,统计信息和分类标签的混合物的传输系统的齿轮齿条件进行分类。
加载数据
加载变速箱数据集进行训练。该数据集由传输系统的208个合成读数组成,该传输系统由18个数字读数和3个分类标签组成:
SigMean- 振动信号的平均SigMedian-振动信号中值SigRMS- 振动信号RMSSigVar-振动信号方差SigPeak-振动信号峰值SigPeak2Peak- 振动信号峰峰值SigSkewness—振动信号偏度SigKurtosis- 振动信号峰度SigCrestFactor- 振动信号波峰因数SigMAD-振动信号MADSigRangeCumSum—振动信号范围累积和SigCorrDimension-振动信号相关维数SigApproxEntropy-振动信号近似熵SigLyapExponent-振动信号Lyap指数PeakFreq——峰值频率。HighFreqPower-高频功率EnvPower——环境的力量PeakSpecKurtosis-谱峰度的峰值频率SensorCondition-传感器状态,指定为“传感器漂移”或“无传感器漂移”ShaftCondition-轴的状态,指定为“轴磨损”或“无轴磨损”GearToothCondition-齿轮的状况,指定为“齿故障”或“无齿故障”
从CSV文件中读取传输框数据“transmissionCasingData.csv”.
文件名=“transmissionCasingData.csv”;TBL = readtable(文件名,'TextType',“字符串”);
属性将用于预测的标签转换为分类的convertvars函数。
labelName =“GearToothCondition”;台= convertvars(资源描述、labelName“绝对”);
查看表的前几行。
头(台)
ans =8×21表SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis SensorCondition ShaftCondition GearToothCondition ________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ _______________ __________________ -0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314-0.041525 2.2666 2.0514 0.8081 1.1429 28562 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 “传感器漂移”, “无轴的磨损” 无齿故障-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 0 5.08E-08 9.16e-08 226.12 “传感器漂移”, “无轴的磨损” 无齿故障1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 0 6.74E-06 2.85E-07 162.13 “传感器漂移”, “轴的磨损” 无齿故障1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 0 4.99e-06 2.4E-07 162.13 “传感器漂移”“轴穿”无齿故障1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62E-06 2.28e-07 230.39 “传感器漂移”, “轴的磨损” 无齿故障1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.24391.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 “传感器漂移”, “轴的磨损” 无齿故障1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 0 1.73e-06 1.55e-07 230.39 “传感器漂移”, “轴的磨损” 无齿故障1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.80583 31554 1.1345 0.0353 44.223 0 1.11e-06 1.39E-07 230.39 “传感器漂移”, “轴的磨损” 无齿故障
要使用分类特征训练网络,必须首先将分类特征转换为数字。首先,将分类预测符转换为分类预测符convertvars函数的方法是指定一个包含所有分类输入变量名称的字符串数组。在这个数据集中,有两个带有名称的分类特性“SensorCondition”和“ShaftCondition”.
categoricalInputNames = [“SensorCondition”“ShaftCondition”];TBL = convertvars(TBL,categoricalInputNames,“绝对”);
循环分类输入变量。为每一个变量:
属性将分类值转换为一个热点编码向量
onehotencode函数。将一个热点向量加到表中
addvars函数。指定在包含相应类别数据的列之后插入向量。删除包含分类数据的相应列。
为了I = 1:numel(categoricalInputNames)名称= categoricalInputNames(ⅰ);OH = onehotencode(TBL(:,名));TBL = addvars(TBL,OH,'后'、名称);台(:名字)= [];结尾
分裂矢量成使用单独的列splitvars函数。
台= splitvars(台);
查看表的前几行。请注意,分类预测器被分割为多个列,其中分类值作为变量名。
头(台)
ans =表8×23SigMean SigMedian SigRMS SigVar SigPeak SigPeak 2peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower peakspec峰度无传感器漂移传感器漂移无轴磨损轴磨损齿轮齿状况________ _________ ______ _______ _______ _______________________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ____________ _____________ __________ __________________ - 0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 1.1429 0.031581 79.931 28562 06.75 e-06 3.23 e-07 162.13 0 1 1 0没有牙齿错-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 29418 1.1362 0.037835 70.325 5.08 e-08 9.16 e-08 226.12 0 1 1 0没有牙齿错1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31710 1.1479 0.031565 125.19 6.74 e-06 2.85 e-07 162.13 0 1 0 1没有牙错1.0227 1.0045 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 1.1472 0.032088 112.5 4.99 e-06 2.4 e-07 162.13 0 1 0 1没有牙齿错1.0123 1.0024 1.4202 0.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 3.62 e-06 2.28 e-07 230.39 0 1 0 1没有牙齿错1.0275 1.0102 1.4338 1.00012.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 2.55 e-06 1.65 e-07 230.39 0 1 0 1没有牙齿错1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 31665 1.1417 0.034159 98.838 1.73 e-06 1.55 e-07 230.39 0 1 0 1没有牙齿错1.0459 1.0257 1.4402 0.98047 2.8157 3.6314 -0.035405 2.2757 1.955 0.8058331554 1.1345 0.0353 44.223 0 1.11e-06 1.39e-07 230.39 0 1 0 1 No Tooth Fault
查看数据集的类名。
类名=类别(TBL {:,标签})
一会=2 x1细胞{'无牙齿故障'}{'牙齿故障'}
将数据集分割为训练集和验证集
将数据集划分为训练、验证和测试分区。留出15%的数据用于验证,15%用于测试。
查看数据集中的观察数。
numObservations =大小(1台)
numObservations = 208
确定每个分区的观察数。
地板numObservationsTrain = (0.7 * numObservations)
numObservationsTrain = 145
地板numObservationsValidation = (0.15 * numObservations)
numObservationsValidation = 31
numObservationsTest = numObservations - numObservationsTrain - numObservationsValidation
numObservationsTest = 32
创建一个与观察值对应的随机索引数组,并使用分区大小对其进行分区。
IDX = randperm(numObservations);idxTrain = IDX(1:numObservationsTrain);idxValidation = IDX(numObservationsTrain + 1:numObservationsTrain + numObservationsValidation);idxTest = IDX(numObservationsTrain + numObservationsValidation + 1:结束);
使用索引将数据表划分为训练、验证和测试分区。
tblTrain = TBL(idxTrain,:);tblValidation = TBL(idxValidation,:);TBLTEST = TBL(idxTest,:);
定义网络体系结构
定义用于分类的网络。
限定具有特征输入层的网络,并指定的特征的数目。另外,配置输入层中使用Z分数归一化归一化的数据。接着,包括具有后面是批标准化层和RELU层输出大小50完全连接的层。对于分类,指定与对应于类别数输出大小另一个完全连接层,接着是SOFTMAX层和分类层。
numFeatures = size(tbl,2) - 1;numClasses =元素个数(类名);[featureInputLayer(numFeatures,'正常化',“zscore”) fulllyconnectedlayer (50) batchNormalizationLayer relullayer fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
指定培训选项
指定培训选项。
用亚当来训练网络。
使用16号小批量列车。
每个纪元都洗牌数据。
在培训期间通过指定验证数据监控网络的准确性。
在绘图中显示训练进度,并抑制verbose命令窗口输出。
该软件在训练数据上对网络进行训练,并在训练期间定期计算验证数据的准确性。验证数据不用于更新网络权重。
miniBatchSize = 16;选项= trainingOptions('亚当',…'MiniBatchSize'miniBatchSize,…'洗牌',“every-epoch”,…“ValidationData”tblValidation,…“阴谋”,“训练进步”,…'verbose'、假);
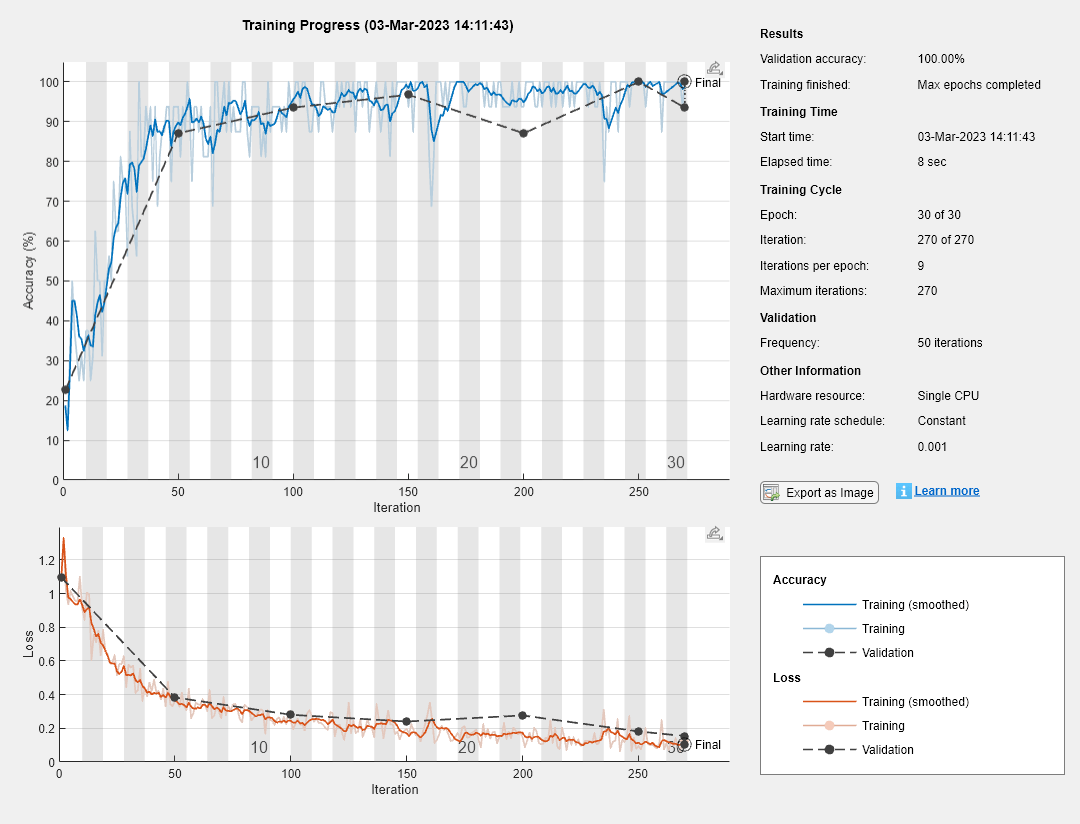
列车网络的
使用定义的体系结构训练网络层数、培训数据和培训选项。默认情况下,Trainnetwork.如果GPU可用,则使用GPU,否则使用CPU。GPU上的培训需要并行计算工具箱™和支持的GPU设备。金宝app有关支持的设备的信息,请参见金宝appGPU支金宝app持情况(并行计算工具箱).属性也可以指定执行环境“执行环境”的名称-值对参数trainingOptions.
培训进度图显示了小批损失和准确性以及验证损失和准确性。有关培训进度图的更多信息,请参见监控深度学习训练进展.
网= trainNetwork (tblTrain、labelName层,选择);
测试网络
利用训练好的网络预测测试数据的标号,并计算其精度。指定与培训相同的小批量大小。
YPred =分类(净,tblTest (: 1: end-1),'MiniBatchSize',miniBatchSize);
计算分类精度。准确率是指网络预测正确标签的比例。
欧美= tblTest {: labelName};精度= sum(YPred == YTest)/numel(YTest)
精度= 0.9688
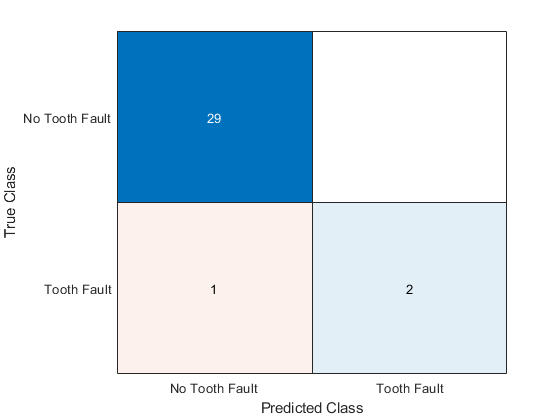
查看混淆矩阵的结果。
YPred图confusionchart(欧美)
也可以看看
Trainnetwork.|trainingOptions|fullyConnectedLayer|深层网络设计师|featureInputLayer
相关的例子
更多关于
你也可以从以下列表中选择一个网站:
