基于循环学习率的快照加密训练网络
这个例子展示了如何使用循环学习速率计划和快照集成来训练网络对目标图像进行分类,以获得更好的测试准确性。在本例中,您将学习如何在学习率计划中使用余弦函数,在训练期间拍摄网络快照以创建模型集成,并将l2范数正则化(权重衰减)添加到训练损失中。
这个例子在cioe -10数据集[2]上训练残差网络[1],使用自定义的循环学习率:对于每一次迭代,求解器使用移位余弦函数[3]给出的学习率α(t) = (alpha0/2) * cos(π*国防部(t - 1 t / M) / (t / M) + 1),在那里T是迭代次数,T为训练迭代的总次数,alpha0.是初始学习率,以及M为周期数/快照数。这种学习率计划有效地将训练过程分为M周期。每个周期以一个单调衰减的大学习率开始,迫使网络探索不同的局部极小值。在每个训练周期结束时,您拍摄网络快照(即,在本次迭代中保存模型),然后平均所有快照模型的预测,也称为快照置乱[4] ,以提高最终测试精度。
准备数据
下载CIFAR-10数据集[2]。数据集包含60,000个图像。每个图像的大小为32°32,具有三个颜色通道(RGB)。数据集的大小为175 MB。根据您的Internet连接,下载过程可能需要时间。
datadir = tempdir;downloadCIFARData (datadir);
加载CIFAR-10训练和测试图像为4-D阵列。训练集包含50,000张图像,测试集包含10,000张图像。
[xtrain,ytrain,xtest,ytest] = loadcifardata(Datadir);Classes =类别(YTrain);numclasses = numel(类);
您可以使用以下代码显示训练图像的随机样本。
数字;IDX = RANDPERM(大小(XTRAIN,4),20);IM = IMTILE(XTrain(::::,idx),“ThumbnailSize”,[96,96]);imshow(im)
创建一个augmentedImageDatastore用于网络培训的对象。在训练期间,数据存储架随机将训练图像随机翻转垂直轴,随机将最多四个像素水平和垂直转换。数据增强有助于防止网络过度接收和记忆培训图像的确切细节。
imageSize = [32 32 3];pixelRange = [-4 4];imageAugmenter = imageDataAugmenter (...“RandXReflection”,真的,...“RandXTranslation”pixelRange,...'randytranslation', pixelRange);augimdsTrain = augmentedImageDatastore(图象尺寸、XTrain YTrain,...“数据增强”,imageaugmender);
定义网络体系结构
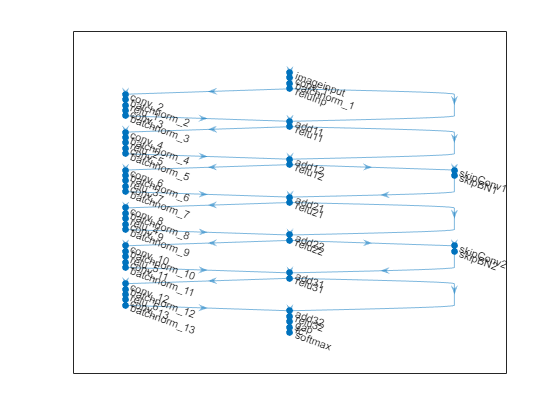
创建一个具有6个标准卷积单元(每级两个单元)和16宽的残差网络[1]。总网络深度为2*6+2 = 14。此外,使用“的意思是”选项在图像输入层。
NetWidth = 16;图层= [imageInputLayer(图像化,“姓名”,“输入”,“的意思是”,平均(XTrain,4))卷积2层(3,netWidth,“填充”,'相同的',“姓名”,“康文普”) batchNormalizationLayer (“姓名”,“BNInp”)雷卢耶(“姓名”,'reluinp')卷积单元(netWidth,1,'s1u1')附加层(2,“姓名”,“add11”)雷卢耶(“姓名”,“relu11”)卷积单元(netWidth,1,'s1u2')附加层(2,“姓名”,“add12”)雷卢耶(“姓名”,“relu12”)卷积帆船(2 * NetWidth,2,'s2u1')附加层(2,“姓名”,“add21”)雷卢耶(“姓名”,“relu21”)卷大钢筋(2 * NetWidth,1,'s2u2')附加层(2,“姓名”,“add22”)雷卢耶(“姓名”,“relu22”) convolutionalUnit (4 * netWidth 2‘S3U1’)附加层(2,“姓名”,“add31”)雷卢耶(“姓名”,“relu31”) convolutionalUnit (4 * netWidth 1‘S3U2’)附加层(2,“姓名”,“add32”)雷卢耶(“姓名”,“relu32”) averagePooling2dLayer (8,“姓名”,“globalPool”)全连接层(10,“姓名”,'fcfinal'));lgraph = layerGraph(层);lgraph = connectLayers (lgraph,'reluinp',“add11 / in2”); lgraph=连接层(lgraph,“relu11”,'Add12 / In2');skip1 =[卷积2dlayer (1,2*netWidth,“大步走”,2,“姓名”,“skipConv1”) batchNormalizationLayer (“姓名”,“skipBN1”));lgraph = addLayers (lgraph skip1);lgraph = connectLayers (lgraph,“relu12”,“skipConv1”); lgraph=连接层(lgraph,“skipBN1”,“add21 / in2”); lgraph=连接层(lgraph,“relu21”,“add22 / in2”);skip2 =[卷积2dlayer (1,4*netWidth,“大步走”,2,“姓名”,“skipConv2”) batchNormalizationLayer (“姓名”,“skipBN2”)]; lgraph=addLayers(lgraph,skip2);lgraph=连接层(lgraph,“relu22”,“skipConv2”); lgraph=连接层(lgraph,“skipBN2”,“add31 / in2”); lgraph=连接层(lgraph,“relu31”,“add32/in2”);
绘制ResNet架构。
图形;绘图(lgraph)
创建一个dlnetwork对象从层图。
dlnet=dlnetwork(lgraph);
定义模型梯度函数
创建helper函数modelGradients,列在示例的末尾。该函数接受dlnetwork对象DLNET.和迷你批次输入数据dlX与相应的标签Y,并返回损失相对于可学习参数的梯度DLNET..该函数还返回给定迭代时网络的损失和不可学习参数的状态。
指定培训选项
指定训练选项。训练200个历元,最小批量为64。
numEpochs=200;miniBatchSize=64;numObservations=numel(YTrain);速度=[];动量=0.9;重量衰减=1e-4;
指定特定于周期学习率的培训选项。Alpha0是初始学习率和numsnapshots.为训练期间的循环次数或快照次数。
alpha0 = 0.1;numSnapshots = 5;epochsPerSnapshot = numEpochs. / numSnapshots;iterationsPerSnapshot =装天花板(numObservations. / miniBatchSize) * numEpochs. / numSnapshots;modelPrefix =“快照时代”;
将培训进度可视化到绘图中。
阴谋=“训练进步”;
初始化训练图。
如果plots ==“训练进步”[lossLine, learnRateLine] = plotLossAndLearnRate ();终止
火车模型
用minibatchqueue在培训期间处理和管理小批量图像。对于每个小批量:
使用自定义小批量预处理功能
预处理小批量(在此示例的末尾定义为单热编码类标签。使用尺寸标签格式化图像数据
“SSCB”(spatial, spatial, channel, batch)。默认情况下,minibatchqueue对象将数据转换为dlarray.底层类型的对象单。请勿向类标签添加格式。在可用的GPU上进行训练。默认情况下,
minibatchqueue对象将每个输出转换为gpuArray如果有可用的GPU。使用GPU需要并行计算工具箱™和支持的GPU设备。金宝app有关支持的设备的信息,请参见金宝appGPU支金宝app持情况(并行计算工具箱).
augimdsTrain。MiniBatchSize = miniBatchSize; mbqTrain = minibatchqueue(augimdsTrain,...“MiniBatchSize”miniBatchSize,...“MiniBatchFcn”@preprocessMiniBatch,...“MiniBatchFormat”,{“SSCB”,''});
使用自定义训练循环训练模型。对于每个历元,洗牌数据存储,循环小批量数据,并保存模型(快照)(如果当前历元是epochspersnapshot..在每个纪元的末尾,展示训练的进展情况。为每个mini-batch:
评估模型梯度和损失使用
dlfeval和modelGradients作用更新网络的不可学习参数的状态。
确定周期学习率计划的学习率。
使用以下命令更新网络参数:
sgdmupdate作用在每次迭代时绘制损失和学习率。
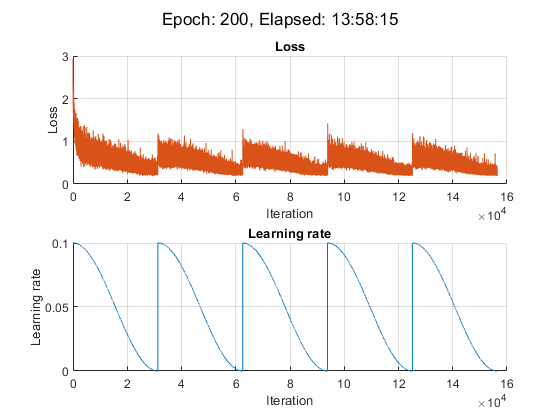
就本例而言,在NVIDIA上进行培训大约需要14小时™ 泰坦RTX。
迭代= 0;开始=抽搐;%循环纪元。对于时代= 1:numEpochs%Shuffle数据。洗牌(mbqTrain);%保存快照模型。如果〜mod(epochspersnapshot)保存(modelprefix + epoch +“。垫”,“dlnet”);终止%循环小批。尽管hasdata(mbqTrain) iteration = iteration + 1;%读取小批数据。[DLX,DLY] =下一个(MBQTrain);使用dlfeval和% modelGradients函数。[渐变,损失,状态] = DLFeval(@ Maposgradients,Dlnet,DLX,DLY,举重);%更新非可爱参数的状态。dlnet。=状态;%确定周期学习率计划的学习率。learnRate=0.5*alpha0*(cos((pi*mod(迭代-1,迭代Persnapshot)。/iterationPersnapshot))+1);%使用SGDM优化器更新网络参数。[dlnet.Learnables,velocity]=sgdmupdate(dlnet.Learnables,梯度,速度,learnRate,动量);%显示培训进度。如果plots ==“训练进步”d =持续时间(0,0,toc(start),“格式”,“hh: mm: ss”);添加点(lossLine、iteration、double(gather(extractdata(loss)))添加点(learnRateLine、iteration、learnRate);sgtitle(”时代:“+纪元+,已过:+字符串(d))绘制终止终止终止
创建快照集合和测试模型
结合训练时拍摄的M张网络快照,形成最终的集成,并测试模型的分类精度。集合预测对应于所有M个独立模型的全连接层输出的平均值。
在CIFAR-10数据集提供的测试数据上测试模型。使用控件管理测试数据集minibatchqueue对象具有与训练数据相同的设置。
augimdsTest = augmentedImageDatastore(图象尺寸、XTest欧美);augimdsTest。MiniBatchSize = miniBatchSize; mbqTest = minibatchqueue(augimdsTest,...“MiniBatchSize”miniBatchSize,...“MiniBatchFcn”@preprocessMiniBatch,...“MiniBatchFormat”,{“SSCB”,''});
评估每个快照网络的准确性。使用modelPredictions在此示例结束时定义的函数以迭代测试数据集中的所有数据。该函数从模型,预测类和与真实类的比较返回完全连接的图层的输出。
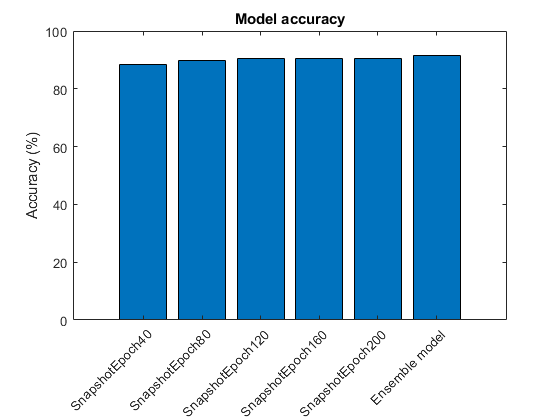
modelName =细胞(numSnapshots + 1, - 1);fcOutput = 0 (numClasses元素个数(欧美),numSnapshots + 1);classPredictions =细胞(1,numSnapshots + 1);modelAccuracy = 0 (numSnapshots + 1, - 1);对于m = 1:numsnapshots modelname {m} = modelprefix + m * epochspersnapshot;load(modelname {m} +“。垫”);重置(mbqTest);[fcOutputTest, classPredTest classCorrTest] = modelPredictions (dlnet、mbqTest、类);fcOutput(:,:,米)= fcOutputTest;classPredictions {m} = classPredTest;modelAccuracy (m) = 100 *意味着(classCorrTest);disp (modelName {m} +准确性:“+ modelAccuracy(m)+"%")终止
SNAPSHOTEPOCH40精度:88.35%Snapshotepoch80精度:89.93%Snapshotepoch120精度:90.51%Snapshotepoch160精度:90.33%Snapshotepoch200精度:90.63%
要确定集成网络的输出,请计算每个快照网络的完全连接输出的平均值。使用onehotdecode与真实类进行比较,以评估集合的准确性。
FcOutput(:,:,结束)=均值(fcOutput(::,:,1:结束-1),3);classpricictions {end} = onehotdecode(softmax(fcoutput(:,exp)),classes,1,“分类”); classcorresemble=classPredictions{end}==YTest';模型精度(end)=100*平均值(类别);模型名{end}=“集合模型”;disp (“整体精度:“+模型精度(完)+"%")
整体精度:91.59%
绘制准确性
为所有快照模型和集合模型设置测试数据的准确性。
图;酒吧(ModelAccuracy);ylabel(的精度(%));xticklabels (modelName) xtickangle(45)标题(“模型精度”)
辅助函数
模型梯度函数
这个modelGradients功能需要一个dlnetwork对象DLNET.,输入数据的一小批dlX,标签Y,以及权重衰减的参数。该函数返回梯度、损失和不可学习参数的状态。要自动计算梯度,请使用Dlgradient.作用
功能[gradient,loss,state] = modelGradients(dlnet,dlX,Y,weightDecay) [dlpred,state] = forward(dlnet,dlX);dlYPred = softmax (dlYPred);loss = cross - sentropy(dlYPred, Y);%L2正则化(权重衰减)allParams = dlnet.Learnables (dlnet.Learnables。参数= =“重量”| dlnet.Learnables.Parameter = =“规模”,:)。价值;l2norm = cellfun(@(x)sum(x。^ 2,'全部'),allparams,“UniformOutput”、假);l2Norm =总和(猫(l2Norm {:}));loss = loss + weightDecay*0.5*l2Norm;梯度= dlgradient(损失、dlnet.Learnables);终止
模型预测功能
这个modelPredictions函数接受一个输入dlnetwork对象DLNET., 一种minibatchqueue的输入数据MBQ.,并通过迭代所有数据来计算模型预测minibatchqueue.函数使用onehotdecode功能要查找最高分的预测类,然后将预测与真实类进行比较。该函数返回网络输出,类预测和表示正确和不正确预测的零的向量。
功能[RawPredictions,ClassPrictictions,ClassCorr] = ModelPredictions(DLNET,MBQ,类)RAWPREDITIONS = [];classpricictions = [];classcorr = [];尽管hasdata(mbq) [dlX,dlY] = next(mbq);% 作出预测dlypred =预测(Dlnet,DLX);RawPredictions = [RawPredictions提取数据(收集(Dlypred))];%将网络输出转换为概率并确定预测值%的类dlYPred = softmax (dlYPred);ypredbatch = onehotdecode(dlypred,classes,1);classPredictions = [classPredictions YPredBatch];%比较预测的和真实的类Y = onehotdecode(海底、类1);classCorr = [classCorr YPredBatch == Y];终止终止
情节丢失和学习率功能
这个plotLossAndLearnRate功能允许在训练期间显示每次迭代的损失和学习率的地块。
功能[lossLine,learnRateLine]=plotLossAndLearnRate()图形子图(2,1,1);lossLine=animatedline(“颜色”,[0.85 0.325 0.098]);标题(“损失”); xlabel('迭代')ylabel(“损失”网格)在子图(2,1,2);sewnroateline =动画线条(“颜色”,[0 0.447 0.741]);标题(学习速率的); xlabel('迭代')ylabel(学习速率的网格)在终止
卷积单位函数
这个convolutionalUnit (numF、跨步、标签)函数创建一个由两个卷积层和相应的批处理规范化和ReLU层组成的层数组。numf.是卷积滤波器的数量,大步走是第一个卷积层的步幅,和标签是附加在所有层名称前的标记。
功能层=卷积单位(numF,步幅,标记)层=[卷积2层(3,numF,“填充”,'相同的',“大步走”大步走“姓名”,标签,'conv1'])BatchnormalizationLayer(“姓名”,标签,“BN1”])雷卢耶(“姓名”,标签,“relu1”])卷积2dlayer(3,numF,“填充”,'相同的',“姓名”,标签,'conv2'])BatchnormalizationLayer(“姓名”,标签,“BN2”)));终止
数据预处理功能
这个预处理小批量函数使用以下步骤对数据进行预处理:
从传入单元格数组中提取图像数据并将其连接到数字阵列中。通过第四维度连接图像数据将第三维度添加到每个图像,以用作单例通道维度。
从传入的单元格数组中提取标签数据,并沿第二维度连接到分类数组中。
单热编码分类标签到数字阵列中。编码到第一维度生成符合网络输出的形状的编码阵列。
功能[X,Y]=预处理小批量(XCell,YCell)%从单元格提取图像数据并连接X=cat(4,XCell{:});%提取来自细胞和连接的标记数据Y=cat(2,YCell{:});%一次性编码标签y = onehotencode(y,1);终止
参考文献
何开明,张翔宇,任少青,孙健“图像识别的深度残差学习”。在计算机愿景和模式识别的IEEE会议的诉讼程序,pp.770-778。2016年。
[2] Krizhevsky,亚历克斯。“从微小图像中学习多层特征。”(2009)。https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
[3] Loshchilov,Ilya和Frank Hutter.《Sgdr:带热重启的随机梯度下降》(2016)。arXiv预印本arXiv: 1608.03983.
[4] 黄,高,李一轩,杰夫·普利斯,庄刘,约翰·E·霍普克罗夫特和基连·Q·温伯格。“快照合奏:第1列,免费获得m。”(2017年)。arXiv预印本arXiv:1704.00109.
另见
dlarray.|dlfeval|Dlgradient.|dlnetwork|分层图|minibatchqueue|onehotdecode|onehotencode|sgdmupdate|乙状结肠
相关的话题
您还可以从以下列表中选择一个网站:
