时间序列回归VIII:滞后变量和估计偏差
该示例显示了滞后预测器如何影响多元线性回归模型的最小二乘估计。在前面的示例中的演示文稿之后,它是关于时间序列回归的一系列示例中的第八。
介绍
许多经济学模型是动态的,使用滞后变量将反馈随时间合并。相比之下,静态时间序列模型代表专门响应当前事件的系统。
滞后变量有几种类型:
分布式滞后(DL)变量是滞后的值 观察到的外源性预测变量 .
自回归(AR)变量是滞后的值 观察到的内源性反应变量 .
移动平均线(MA)变量是滞后的值 未观测到的随机创新过程 .
动态模型通常使用不同类型的滞后变量的线性组合来构建,以创建ARMA、ARDL和其他混合变量。在每种情况下,建模的目标都是准确而简明地反映相关经济因素之间的重要相互作用。
动态模型规范提出了这样一个问题:哪些滞后很重要?一些模型,如季节模型,在数据的不同时期使用滞后。其他模型基于对经济行动者如何以及何时对不断变化的条件作出反应的理论考虑。一般来说,滞后结构识别对已知先行指标的响应的时间延迟。
然而,滞后结构必须不仅仅是代表可用理论。由于动态规格产生可能影响标准回归技术的变量之间的相互作用,因此还必须考虑到精确的模型估计来设计滞后结构。
规范问题
考虑多个线性回归(MLR)模型:
在哪里 是观察到的反应, 包括每个潜在相关预测变量的列,包括滞后变量,和 是一个随机创新过程。中系数估计的准确性 取决于的组成列 ,以及联合分配 .选择预测 这在统计上和经济上显着通常涉及估计,残余分析和重新判断的循环。
典型的线性模型(CLM)假设,在示例中讨论时间序列回归I:线性模型,允许普通最小二乘(OLS)产生的估计 具有理想的特性:相对于其他估计量,无偏、一致和有效。滞后指标在 ,但是,可能会引入违反CLM假设的情况。具体的违规取决于模型中滞后变量的类型,但动态反馈机制的存在,通常倾向于夸大与静态规范相关的问题。
模型规范问题通常是相对于响应变量的数据生成过程(DGP)进行讨论的 .然而,在实际中,DGP是一个理论结构,只有在仿真中才能实现。没有模型能完全捕捉真实世界的动态,模型系数也在其中 始终是真实DGP中的子集。结果,创新 成为过程的固有随机性的混合和潜在大量的省略变量(OVS)。自相关 在经济学模型中是常见的,其中Ovs随着时间的推移表现出持久性。而不是将模型与理论DGP进行比较,而是更实际的是评估数据中是否或多大程度,从残留物中的自相关区分中的动态。
最初,LAG结构可以包括在多个近时段的经济因素观察。但是,时间观察T.可能与观测结果相关吗T.- 1,T.- 通过经济惯性,等等。因此,滞后结构可以过度证明通过包括一系列滞后预测因子的响应动态,其仅为DGP的边际贡献。该规范将夸大过去历史的影响,并且未能对模型施加相关的限制。扩展滞后结构还需要扩展的预先数据数据,降低样本大小并降低估计程序中的自由度。因此,过度的模型可能表现出具有共同性和高估计方差的明显问题。由此产生的估计 精度低,并且变得难以分离个别效果。
为了减少预测估计依赖性,可以限制滞后结构。然而,如果限制过于严重,则会产生估计的其他问题。可能会限制滞后结构underspecify.除了实际上是DGP的重要组成部分的预测因子,响应的动态。这导致了一个模型,低估了过去历史的影响,强迫重要的预测因子进入创新过程。如果滞后预测因素 是否与近似滞后预测因子相关 ,违反了重量级的严格重大性的CLM假设,并且OLS估计 变得偏见和不一致。
具体问题与不同类型的滞后预测器相关联。
滞后外生因素 ,他们自己,不要违反CLM假设。然而,通常至少最初描述DL模型,通过长序列潜在的相关滞后,因此遭受上述超薄问题。常见的,如果有点临时,用于对滞后权重的限制施加的方法(即系数 )在该示例中讨论时间序列回归IX:滞后订单选择.然而,原则上,分析了静态模型的DL模型平行。仍然仍然检查与共同性,有影响力的观察,虚假回归,自相关或异源创新等相关的估计问题。
滞后的内源性预测因子 有更多的问题。AR模型引入了CLM假设的违背,导致有偏差的OLS估计 .在没有任何其他CLM违规的情况下,估计仍然是一致的和相对有效的。考虑一个简单的一阶自回归 在 :
在这个模型中, 是由两者共同决定的 和 .一步一步向后转动等式, 是由两者共同决定的 和 那 是由两者共同决定的 和 等等。,由轨迹的预测 与创新过程的整个历史相关。与规格不足一样,CLM严格外生性假设被违反,OLS估计 成为有偏见。因为 必须吸收各自的影响吗 ,模型残留不再代表真正的创新[10].
当AR模型的创新是自相关时,问题复杂。如该示例中所讨论的时间序列回归VI:残留诊断如果潜在的高差异,在没有其他CLM违规的情况下,在没有其他CLM违规的情况下的自相关创新,如果潜在的高方差,OLS对模型系数的估计。在这种情况下,主要复杂性是系数标准误差的通常估计变为偏差。(异源创新的影响是相似的,尽管通常不那么明显。)如果自相关的创新与违反严格的重生,那么就像AR条款产生的那样,估计 变得偏见和不一致。
如果落后于创新 被用作预测因子,估计过程的性质从根本上改变,因为无法直接观察到创新。估计要求MA术语倒置以形成无限的AR表示,然后限制为生产可以在实践中估计的模型。由于在估计期间必须施加限制,因此需要不同于OL的数值优化技术,例如最大似然估计(MLE)。在示例中考虑了MA术语的模型时间序列回归IX:滞后订单选择.
模拟估计偏差
为了说明由滞后的内源预测器引入的估计偏差,请考虑以下DGP:
我们运行两组重复的模型蒙特卡罗模拟。第一个集合使用通常和独立分布(nid)创新 .第二组使用AR(1)创新 .
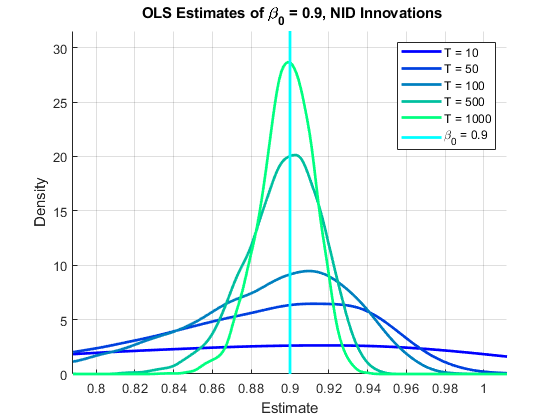
%构建模型组件:beta0 = 0.9;y_t的% AR(1)参数gamma0 = 0.2;E_T的%AR(1)参数AR1 = arima ('AR'beta0,“不变”,0,'方差',1);AR2 = ARIMA('AR',gamma0,“不变”,0,'方差',1);%模拟样本量:T = (50100500, 1000);numSizes =长度(T);%运行模拟:numObs = max (T);仿真路径的数量长度numPaths = 1 e4;%仿真路径数量伯恩= 100;%初始瞬态期间,被丢弃σ= 2.5;%创新的标准偏差e0 = sigma * randn(伯恩+ numobs,numpaths,2);%nid创新E1Full = E0 (:: 1);Y1Full =过滤器(AR1 E1Full);%AR(1)进程与NID创新e2full =滤波器(AR2,E0(:,:,2));Y2FULL =滤波器(AR1,E2FULL);%AR(1)与AR(1)创新的进程清晰的E0.%提取仿真数据,暂态期后:y1 = y1full(伯恩+ 1:结束,:);%y1(t)LY1 = Y1Full(燃烧:end-1:);%Y1(T-1)Y2 = Y2Full(燃烧+ 1:最终,);% Y2 (t)ly2 = y2full(伯恩:结束-1,:);%Y2(T-1)清晰的y1full.Y2Full计算β的OLS估计值:Betahat1 =零(Numsizes,NumPaths);betahat2 = zeros(numsizes,numpaths);为i = 1:numquize n = t(i);为j = 1: numPaths BetaHat1 (i, j) = LY1 (1: n, j) \ Y1 (1: n, j);BetaHat2 (i, j) = LY2 (1: n, j) \ Y2 (1: n, j);结束结束%设置绘图域:w1 = std(betahat1(:));x1 =(beta0-w1):( w1 / 1e2):( beta0 + w1);w2 = std(betahat2(:));X2 =(beta0-W2):( W2 / 1E2):( beta0 + w2);%创建数字和绘图处理:hfig1 =图;抓住在hplots1 =零(Numsize,1);hfig2 =数字;抓住在hplots2 =零(numquizing,1);% Plot estimator分布:颜色=冬天(Numsizes);为i = 1:numsize c =颜色(i,:);图(HFIG1);f1 = ksdentions(betahat1(i,:),x1);hplots1(i)= plot(x1,f1,“颜色”,C,'行宽'2);图(hFig2);f2 = ksdensity (BetaHat2(我,:),x2);hPlots2 (i) =情节(x2, f2,“颜色”,C,'行宽'2);结束%注释图:图(hFig1) hBeta1 = line([beta0 beta0],[0 (1.1)*max(f1)],“颜色”那'C'那'行宽'2);包含('估计') ylabel ('密度') 标题(['{\ bf ols估计\ beta_0 =',num2str(beta0,2),创新}’”,国家免疫日])传奇([hplots1; hbeta1],[strcat({'t ='},num2str(t','%-D'));“\ beta_0 = 'num2str (beta0 2)]])轴紧网格在抓住离开
图(hFig2) hBeta2 = line([beta0 beta0],[0 (1.1)*max(f2)],“颜色”那'C'那'行宽'2);包含('估计') ylabel ('密度') 标题(['{\ bf ols估计\ beta_0 =',num2str(beta0,2),',AR(1)创新}'])传奇([hplots2; hbeta2],[strcat({'t ='},num2str(t','%-D'));“\ beta_0 = 'num2str (beta0 2)]])轴紧网格在抓住离开
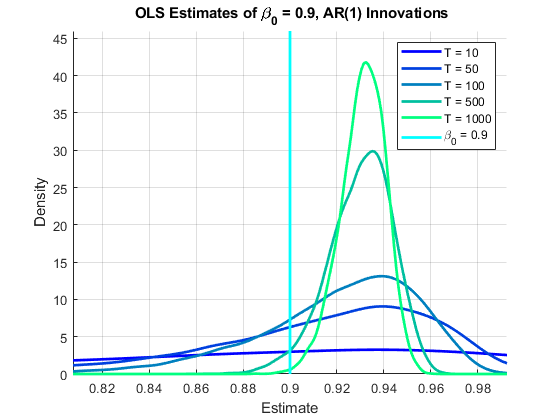
在上面的所有模拟中, .这些图是…的分布 在每个过程的多种模拟中,显示OLS估计器的偏差和变化作为样本大小的函数。
分布的歪斜使得难以在视觉上评估他们的中心。偏差被定义为 ,所以我们使用旨在衡量总估计的含义。在NID创新的情况下,随着总体估计朝向的总体估计增加,相对较小的负面偏差消失了 :
AggBetaHat1 =意味着(BetaHat1, 2);fprintf('%-6s%-6s \ n'那'尺寸'那“Mean1”)
尺寸为1
为i = 1:numquize fprintf('%-6u%-6.4f \ n'AggBetaHat1 T(我),(我))结束
10 0.7974 50 0.8683 100 0.8833 500 0.8964 1000 0.8981
在AR(1)创新的情况下,在小样本中具有负偏差的合计估计值单调地向 ,但在中等样本量时通过DGP值,在大样本量时逐渐变得更有正偏差:
aggbetahat2 =平均值(betahat2,2);fprintf('%-6s%-6s \ n'那'尺寸'那“非常刻薄的”)
尺寸为2
为i = 1:numquize fprintf('%-6u%-6.4f \ n',t(i),aggbetahat2(i))结束
10 0.8545 50 0.9094 100 0.9201 500 0.9299 1000 0.9310
OLS估计在自相关创新存在中的不一致是在经济学家中众所周知的。然而,它还可以为一系列样本尺寸提供准确的估计,其具有不太受欢迎的实际后果。我们在该部分进一步描述了这种行为动态和相关效果.
在OLS估计方面,上述两组模拟的主要区别在于创新和预测器之间的交互是否存在延迟。在具有NID创新的AR(1)过程中,预测器 同时不相关 ,但与之前所有的创新相关,如前所述。在具有AR(1)创新的AR(1)过程中,预测器 成为与 同样,通过自相关 和 .
要查看这些关系,我们计算之间的相关系数 两者都是 和 ,对于每个流程分别为:
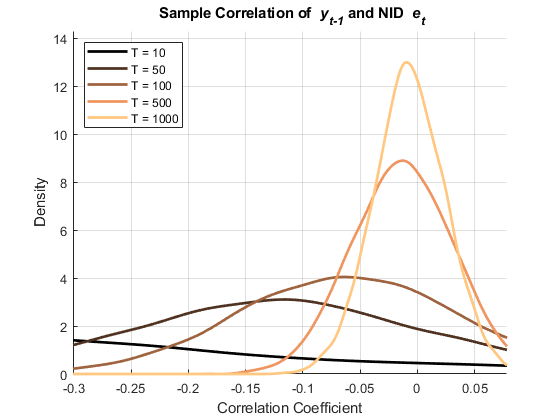
%提取创新数据,瞬态期间:e1 = e1full(伯恩+ 1:结束,:);%E1(T)Le1 = e1full(伯恩:结束-1,:);% E1 (t - 1)e2 = e2full(伯恩+ 1:结束,:);%E2(T)Le2 = E2full(伯恩:结束-1,:);%E2(T-1)清晰的E1Fulle2full.相关系数的%预分配器:corre1 = zeros(numsizes,numpaths);corrle1 = zeros(numsizes,numpaths);corre2 =零(numsizes,numpaths);corrle2 = zeros(numsizes,numpaths);%Compute Corlelation系数:为i = 1:numquize n = t(i);为j = 1: numPaths% NID创新:(CorrE1 (i, j) = corr LY1 (1: n, j), E1 (1: n, j));(CorrLE1 (i, j) = corr LY1 (1: n, j), LE1 (1: n, j));AR(1)创新的百分比(CorrE2 (i, j) = corr LY2 (1: n, j) E2 (1: n, j));(CorrLE2 (i, j) = corr LY2 (1: n, j), LE2 (1: n, j));结束结束%设置绘图域:sigmaE1 =性病(CorrE1 (:));muE1 =意味着(CorrE1 (:));xE1 = (muE1-sigmaE1): (sigmaE1/1e2): (muE1 + sigmaE1);sigmaLE1 =性病(CorrLE1 (:));muLE1 =意味着(CorrLE1 (:));xLE1 = (muLE1-sigmaLE1/2): (sigmaLE1/1e3): muLE1;sigmaE2 =性病(CorrE2 (:));muE2 =意味着(CorrE2 (:));xE2 = (muE2-sigmaE2): (sigmaE2/1e2): (muE2 + sigmaE2);sigmaLE2 =性病(CorrLE2 (:)); muLE2 = mean(CorrLE2(:)); xLE2 = (muLE2-sigmaLE2):(sigmaLE2/1e2):(muLE2+sigmaLE2);%创建数字和绘图处理:hfige1 =图;抓住在hplotse1 =零(numquizing,1);hfigle1 =图;抓住在hPlotsLE1 = 0 (numSizes, 1);hFigE2 =图;抓住在hplotse2 =零(Numsizing,1);hfigle2 =图;抓住在hplotsle2 =零(numquizing,1);% Plot相关系数分布:颜色=铜(Numsizes);为i = 1:numsize c =颜色(i,:);图(hfige1)fe1 = ksdenty(corre1(i,:),xe1);hplotse1(i)= plot(xe1,fe1,“颜色”,C,'行宽'2);图(hFigLE1) fLE1 = ksdensity(CorrLE1(i,:),xLE1);hPlotsLE1 (i) =情节(xLE1 fLE1,“颜色”,C,'行宽'2);图(hfige2)fe2 = ksdenty(corre2(i,:),xe2);hplotse2(i)= plot(xe2,fe2,“颜色”,C,'行宽'2);图(hFigLE2) fLE2 = ksdensity(CorrLE2(i,:),xLE2);hPlotsLE2 (i) =情节(xLE2 fLE2,“颜色”,C,'行宽'2);结束清晰的CorrE1corlle1.CorrE2corlle2.%注释图:图(hFigE1)包含('相关系数') ylabel ('密度')标题('{\ bf样本相关{\它y_ {t-1}}和nid {\它e_t}}')传奇(Hplotse1,Strcat({'t ='},num2str(t','%-D')),“位置”那“西北”)轴紧网格在ylim([0(1.1)* max(fe1)])持有离开
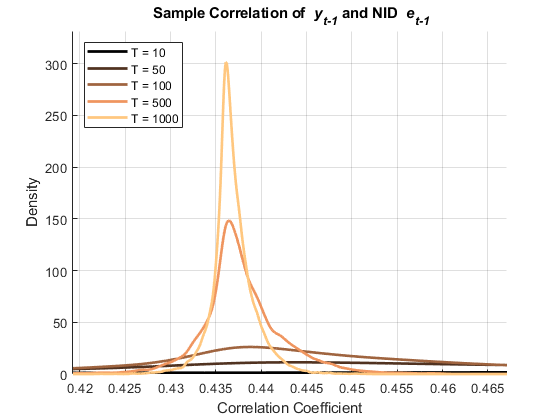
图(Hfigle1)Xlabel('相关系数') ylabel ('密度')标题('{\ bf y_ {t-1}}和nid {\它e_ {t-1}}'的{\ bf样本相关性)传说(hPlotsLE1 strcat ({'t ='},num2str(t','%-D')),“位置”那“西北”)轴紧网格在ylim([0(1.1)* max(fle1)]持有离开
图(hfige2)xlabel('相关系数') ylabel ('密度')标题('{\ bf y_ {t-1}}和ar(1){\ e_t}}')传奇(Hplotse2,Strcat({'t ='},num2str(t','%-D')),“位置”那“西北”)轴紧网格在ylim([0(1.1) *马克斯(铁)])离开
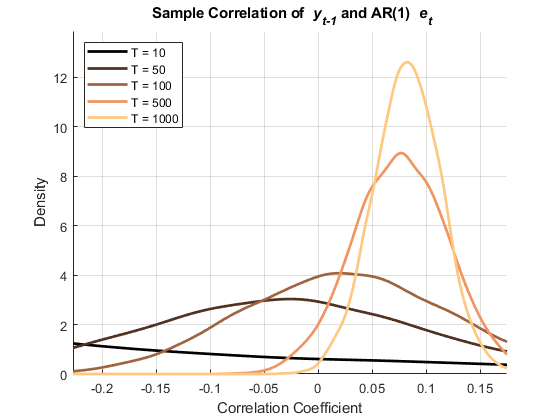
图(Hfigle2)Xlabel('相关系数') ylabel ('密度')标题(的{{\ bf样本相关性\它y_ {t - 1}}和AR(1){\它e_ {t - 1}}}”)传奇(hplotsle2,strcat({'t ='},num2str(t','%-D')),“位置”那“西北”)轴紧网格在ylim([0(1.1)* max(fle2)])保持离开
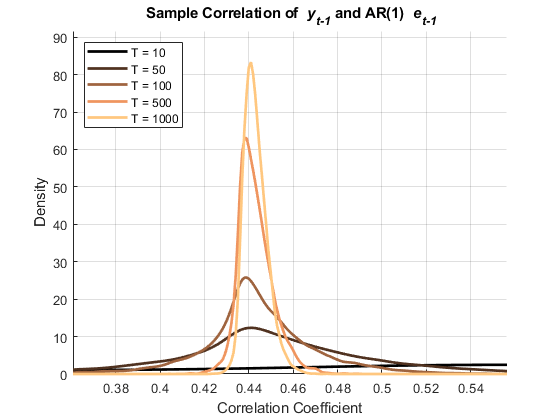
这些图显示了两者之间的相关性 和 在这两种情况下。之间的相关性 和 ,然而,只有在AR(1)创新的情况下才会持续渐进。
相关系数是自相关标准度量的基础。上图突出了有限样本中相关系数的偏差和方差,使得模型残差中自相关的实际评价变得复杂。Fisher ([3]那[4]那[5]),谁建议了一些替代方案。
使用有偏估计 估计 在残差中也是有偏差的[11].如前所述,在AR(1)创新的情况下,OLS残差不能准确地代表工艺创新,因为倾向于 吸收通过自相关干扰产生的系统影响。
为了进一步复杂化问题,Durbin-Watson统计数据普遍报告为一定程度的一阶自相关的衡量标准,是偏向于检测之间的任何关系 和 在存在这种关系的AR模型中。偏差是内偏差的两倍 [8].
因此,OLS可以持续高估 而残差自相关的标准度量低估了导致不一致的条件。这就产生了一种扭曲的契合度,以及对动态术语重要性的误读。德国的 在这种背景下,测试同样无效[7].德国的 测试或相同的Breusch-Godfrey测试通常是优选的[1].
近似估计器偏置
在实践中,必须从可用数据发现产生时间序列的过程,并且该分析最终受到估计偏差和方差的信心丧失的限制。经济数据的样本尺寸通常在上述模拟中考虑的下端,因此不准确可能是显着的。对自回归模型的预测性能的影响可能是严重的。
对于具有简单创新结构的简单AR模型,理论上可以获得OLS估计器偏置的近似。当评估从单个数据样本导出的AR模型系数的可靠性时,这些公式非常有用。
在NID创新的情况下,我们可以将模拟偏差与广泛使用的近似值进行比较[11]那[13]:
m = min(t);m = max(t);ebias1 = aggbetahat1-beta0;%估计偏见tBias1 = 2 * beta0. / T;%理论偏见eB1interp = interp1 (T eBias1 m: m,“pchip”);tb1interp = Interp1(t,tbias1,m:m,“pchip”);图绘图(t,ebias1,'ro'那'行宽', 2)在he1 = plot(m:m,eb1interp,'r'那'行宽'2);情节(T, tBias1“波”)ht1 = plot(m:m,tb1interp,'B');抓住离开传说([he1 ht1],'模拟偏见'那“近似理论偏见”那“位置”那'e')包含('样本大小') ylabel ('偏见')标题(“{\bf估计偏差,NID创新}”) 网格在
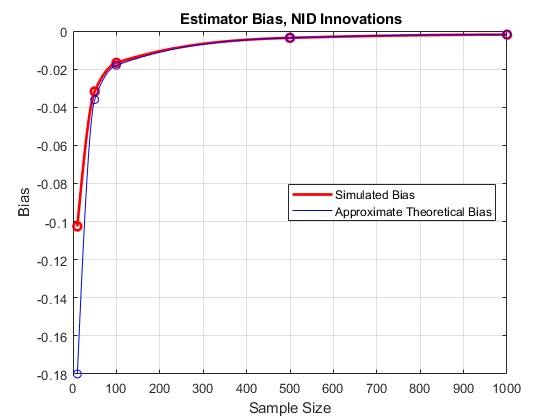
即使在中等规模的样本中,这种近似也是相当可靠的,一般在 绝对值下降。
在AR(1)创新的情况下,偏差取决于两者 和 .渐近地,它近似[6]:
ebias2 = Aggbetahat2-Beta0;%估计偏见tbias2 = gamma0 *(1-beta0 ^ 2)/(1 + gamma0 * beta0);%渐近偏见eb2interp = Interp1(t,ebias2,m:m,“pchip”);图绘图(t,ebias2,'ro'那'行宽', 2)在he2 = plot(m:m,eb2interp,'r'那'行宽'2);ht2 =情节(0:M, repmat (tBias2 1 M + 1),'B'那'行宽'2);抓住离开传奇([何ht2],'模拟偏见'那“近似渐近偏见”那“位置”那'e')包含('样本大小') ylabel ('偏见')标题(“{\bf估计偏差,AR(1)创新}”) 网格在
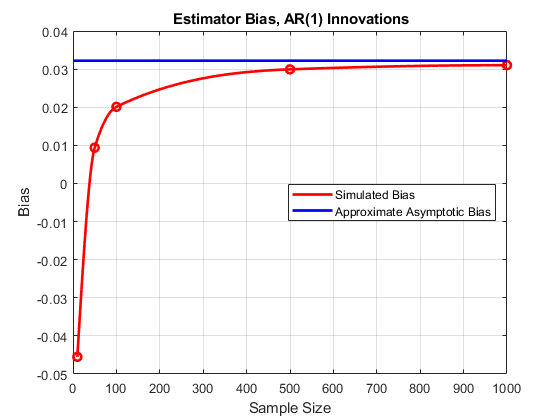
在这里,随着样本大小的增加,我们看到偏置从负到正值,然后最终接近渐近绑定。大约25到100的样品尺寸范围为约25到100,其中偏置的绝对值低于0.02。在这样的“甜蜜点”中,OLS估计器可以优于旨在专门占用自相关的替代估计器。我们在该部分进一步描述了这种行为动态和相关效果.
绘制近似渐近偏差是有用的 作为两者的函数 和 ,以观察自相关程度的变化对两者的影响 和 :
Figure beta = -1:0.05:1;γ= 1:0.05:1;[βγ]= meshgrid(βγ);抓住在冲浪(β,γ,伽玛。*(1-beta。^ 2)./(1 +伽玛。* beta))图= GCF;cm =图.Colormap;numc = size(cm,1);zl = zlim;ZScale = ZL(2)-ZL(1);ISIM =(TBIAS2-ZL(1))* NUMC / ZSCALE;CSIM = INTERP1(1:NUMC,CM,ISIM);HSIM = PLOT3(BETA0,GAMMA0,TBIAS2,“柯”那“MarkerSize”,8,“MarkerFaceColor”,CSIM);查看(-20,20)x = gca;u = ax.xtick;v = ax.ytick;网格(u,v,zeros(长度(v),长度(u)),“FaceAlpha”, 0.7,“EdgeColor”那“k”那“线型”那':')举行离开传奇(HSIM,“模拟模式”那“位置”那'最好')包含('\ beta_0') ylabel (“\ gamma_0”) zlabel ('偏见')标题('{\ bf近似渐近偏见}')窗体彩色杆网格在
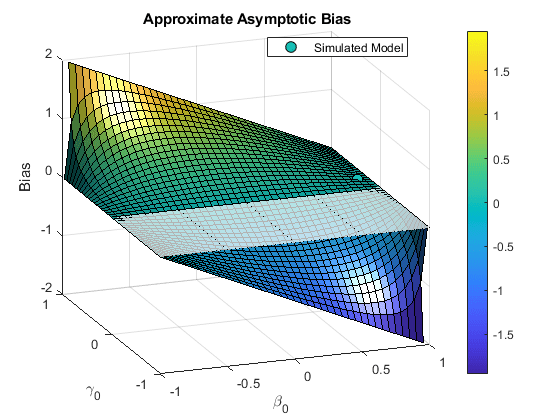
渐近偏差变得显着 和 向相反的方向移动,远离零自相关。当然,在有限的样本中,偏差可能要小得多。
动态和相关效果
如所讨论的,使用OLS进行动态模型估计的挑战因违反CLM假设而产生。两次违规是至关重要的,我们将更详细地讨论其影响。
第一个是动态效果,由预测器之间的相关性引起的 和以前的所有创新 .这发生在任何AR模型中,并导致有限样本的有偏OLS估计。在没有其他违规行为的情况下,苏丹生命线行动仍然保持一致,而且在大样本中偏见消失了。
第二是相关的影响,这是由预测因子之间的同期相关性引起的 和创新 .这种情况发生在创新过程是自相关的时候,并导致预测器的OLS系数接收到太多或太少的响应的同步变化,这取决于相关的符号。也就是说,它产生了一种持久的偏见。
上面的第一组模拟说明了这样一种情况 是积极的, 是零。第二组模拟说明了两者的情况 和 是积极的。积极 ,动态效果 是负的。积极 ,相关效果 是积极的。因此,在第一组模拟中,存在跨越样本尺寸的负偏差。然而,在第二组模拟中,两种效果之间存在竞争,在小样本中占据主导的动态效果,并且在大型样品中占主导地位的相关效果。
正AR系数在经济学模型中是常见的,因此彼此偏移的两个效果是典型的,从而产生OLS偏置显着降低的样本尺寸范围。该范围的宽度取决于 和 ,并决定OLS-superior范围其中,OLS优于在创新中为直接解释自相关性而设计的备选估计器。
对影响大小的一些因素的动态和相关效应进行了总结[9].其中包括:
动态效果
随着样本大小的降低而增加。
减少与增加 如果创新的差异是固定的。
减少与增加 如果调整了创新的差异以保持常数 .
随着创新的差异而增加。
相关的影响
随着越来越多地增加 ,以下降的速度。
减少与增加 ,以增加的速度。
可以通过改变上述模拟中的系数来测试这些因素的影响。一般来说,动态效果越大,相关效果越小,较宽的OLS - 优越范围。
千克偏见减少
这钉书匠过程是一个常用的交叉验证技术,用于减少样本统计的偏差。模型系数的Jacknife估算器相对容易计算,无需大型模拟或重新采样。
基本思想是从完整的样本计算估计值和从一系列子样本,然后以消除偏差的一些部分的方式组合估计。通常,对于大小的样本 , OLS估计量的偏差 可以表达为权力的扩张 :
哪里重量 和 取决于特定的系数和模型。如果估计 是在序列上制作的 长度的副页 ,然后是jackknife估计 是:
可以表明千刀估计满足:
从而消除了这一点 来自偏见扩展的术语。偏差实际上是否降低取决于扩展中剩余术语的大小,但千克估计器在实践中表现良好。特别地,该技术对于非正规创新,弓形效果和各种模型误操作稳健[2].
统计和机器学习工具箱™功能钉书匠使用系统序列的“留下次”载位的系统序列实现千刀手术。对于时间序列,删除观察改变了自相关结构。为了保持时间序列中的依赖结构,jackknife程序必须使用非传递的子样本,例如分区或移动块。
以下实现了一个简单的jackknife估计 在每个模拟中使用数据的分区以产生子样本估计 .我们在jackknifing之前和之后的性能进行比较,以NID或AR(1)创新在模拟数据上:
m = 5;%子样本数量% Preallocate记忆:betahat1 =零(m,1);次样本估计,NID创新betaHat2 = 0 (m, 1);%子样本估计,AR(1)创新BetaHat1J = 0 (numSizes numPaths);%jackknife估计,nid创新betahat2j = zeros(numsizes,numpaths);%jackknife估计,ar(1)创新%compute jackknife估计:为i = 1:numquize n = t(i);%样本大小l = n / m;%分区子间隔长度为j = 1: numPaths为s = 1:m betahat1(s)= ly1((s-1)* l + 1:s * l,j)\ y1((s-1)* l + 1:s * l,j);Betahat2(s)= ly2((s-1)* l + 1:s * l,j)\ y2((s-1)* l + 1:s * l,j);Betahat1j(i,j)=(n /(n-l))* betahat1(i,j) - (l /(n-l)* m))*金额(betahat1);Betahat2j(i,j)=(n /(n-l))* betahat2(i,j) - (l /(n-l)* m))*和(betahat2);结束结束结束清晰的Betahat1.Betahat2.显示折刀前后的平均估算值:AggBetaHat1J =意味着(BetaHat1J, 2);清晰的betahat1j.fprintf(% 6 s % 8 s % 8年代\ n”那'尺寸'那“Mean1”那“Mean1J”)
大小Mean1 Mean1J
为i = 1:numquize fprintf('%-6u%-8.4f%-8.4f \ n'AggBetaHat1 T(我),(我),AggBetaHat1J(我))结束
10 0.7974 0.8055 50 0.8683 0.8860 100 0.8833 0.8955 500 0.8964 0.8997 1000 0.8981 0.8998
aggbetahat2j =平均值(betahat2j,2);清晰的betahat2j.fprintf(% 6 s % 8 s % 8年代\ n”那'尺寸'那“非常刻薄的”那'意思是2J')
大小非常刻薄的Mean2J
为i = 1:numquize fprintf('%-6u%-8.4f%-8.4f \ n'AggBetaHat2 T(我),(我),AggBetaHat2J(我))结束
10 0.8545 0.8594 50 0.9094 0.9233 100 0.9201 0.9294 500 0.9299 0.9323 1000 0.9310 0.9323
子样本的数量, ,选择具有最小的样本大小, , 心里。较大 在更大的样本中可能会提高性能,但对于选择子样本大小没有公认的启发式方法,因此有必要进行一些实验。代码可以很容易地修改为使用替代的子采样方法,例如移动块。
结果表明,偏见的偏差均匀减少了NID创新。在AR(1)创新的情况下,该程序似乎更快地通过OLS-Superior的范围推动估计。
总结
该示例显示了一个简单的AR模型,以及一些简单的创新结构,作为说明与动态模型估计有关的一些常规问题的方式。此处的代码很容易修改以观察更改参数值的影响,使用不同的滞后结构等调整创新方差,等等。解释性DL术语也可以添加到模型中。DL术语具有降低估计器偏差的能力,尽管OLS倾向于以牺牲DL系数为代价估计AR系数[11].这里的一般设置允许大量的实验,这是在实践中评估模型时经常需要的。
当考虑任何估计量的偏差和方差所带来的权衡时,重要的是要记住,与高方差无偏估计量相比,方差减小的有偏估计量可能具有更好的均方误差特征。除了计算简单之外,OLS估计器的一个优点是,随着样本量的增加,它能相对有效地减少方差。这通常足以采用OLS作为选择的估计值,甚至对于动态模型也是如此。另一个优点,正如这个例子所显示的,是OLS优越范围的存在,在这个范围内,即使在通常被认为是不利的条件下,OLS也可能优于其他估计量。OLS估计的最薄弱之处是它在小样本中的表现,在小样本中,偏差和方差可能是不可接受的。
在这个例子中提出的估计问题表明,需要新的自相关指标,并在其存在的情况下使用更稳健的估计方法。示例中描述了其中一些方法时间序列回归X:广义最小二乘和HAC估计.然而,正如我们所看到的,自相关AR模型的OLS估计量的不一致性并不足以排除它,一般来说,它是更复杂的、一致的估计量(如最大似然、可行广义最小二乘和工具变量)的可行竞争者,试图消除关联效应,但不改变动态效应。最佳选择将取决于样本量、滞后结构、外生变量的存在,等等,通常需要本例中给出的模拟类型。
参考文献
[1]Breusch t.s.和l.g. Godfrey。动态同时模型中自相关检验的最新工作综述在Currie, D., R. Nobay和D. Peel(编)中,宏观经济分析:宏观经济学和计量经济学论文集。伦敦:Croom Helm, 1981年出版。
[2]钱伯斯,m . J。平稳自回归模型的折刀估计。埃塞克斯大学讨论论文第684号,2011。
[3]费舍尔,r . .来自无定大总体的样本的相关系数值的频率分布Biometrika.卷。10,1915,第507-521页。
[4]Fisher,R.A。“关于从小样本推断的相关系数的”可能的错误“。”密特隆.1921年第1卷,3-32页。
[5]费舍尔,r。偏相关系数的分布密特隆.卷。3,1924,pp。329-332。
[6]海布斯,D。动态时间序列模型中的统计估计和因果推理问题科斯特纳(H. Costner)社会学研究方法.旧金山:乔西-巴斯出版社,1974年出版。
[7]英德尔,b。含滞后因变量模型自相关检验的有限样本功率经济学的信件.卷。14,1984,PP.179-185。
[8]约翰斯顿(J。经济学方法.纽约:麦格劳 - 山,1972年。
[9]Maeshiro,A。“用滞后的依赖变量和自相关干扰教学回归。”作者:王莹,中国经济教育.卷。1996年,第72-84页。
[10]雪道。说明OLS的偏倚yT.=λyT.-1+你T.."作者:王莹,中国经济教育.卷。31,2000,第76-80页。
[11]Malinvaud,E。经济学统计方法.阿姆斯特丹:北荷兰,1970年。
[12]万豪,F.和J. Pope。“估计自相关的偏见。”Biometrika.1954年第41卷,第390—402页。
[13]白色,j·S。“序列相关系数的均值和方差的渐近展开”。Biometrika.第48卷,1961年,85-94页。
您还可以从以下列表中选择一个网站:
