时间序列回归VI:残留诊断
这个例子展示了如何评估模型假设,并通过检查残差系列来调查重新规范的机会。这是关于时间序列回归的一系列例子中的第6个,在前面的例子中有介绍。
介绍
本系列前面示例中的信用违约数据分析提出了许多不同的模型,使用数据的各种转换和预测因子的各种子集。残差分析是减少考虑的模型数量、评估选项和建议重新指定路径的必要步骤。多元线性回归(MLR)模型,残差明显偏离经典线性模型(CLM)假设(在示例中讨论时间序列回归I:线性模型)不太可能表现良好,无论是在解释可变关系还是预测新响应。已经开发出许多统计测试来评估CLM假设关于创新过程,如残留系列中的表现。我们在这里检查一些测试。
我们首先从上一个例子加载相关数据时间序列回归v:预测器选择:
加载data_tsreg5.
剩余地块
以下内容为前一示例中确定的每个模型生成两个模型类别(未差异数据和差异数据)的残差图:
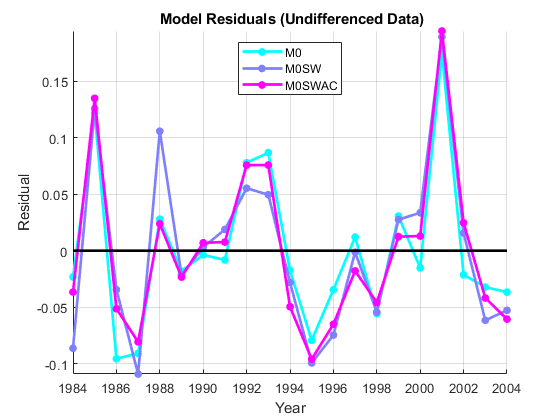
地图=酷(3);%型号颜色图% Undifferenced数据:res0=M0.Residuals.Raw;res0SW=M0SW.Residuals.Raw;res0SWAC=M0SWAC.Residuals.Raw;model0Res=[res0,res0SW,res0SWAC];数字保持在斧头= GCA;ax.colororder =地图;绘图(日期,model0res,'.-'那“线宽”2.'Markersize',20)绘图(日期,零(大小(日期)),'k-'那“线宽”,2)持有离开传奇({'m0'那'm0sw'那'm0swac'},'地点'那'n')xlabel('年')ylabel('剩余的')头衔('{\ BF模型残差(无论数据)}')轴心紧网格在
%差异数据:resD1 = MD1.Residuals.Raw;res0SW = MD1SW.Residuals.Raw;res0SWAC = MD1SWA.Residuals.Raw;modelD1Res =南(长度(日期),3);modelD1Res (2:,:) = (resD1、res0SW res0SWAC);图保存在斧头= GCA;ax.colororder =地图;绘图(日期,Modeld1res,'.-'那“线宽”2.'Markersize',20)绘图(日期,零(大小(日期)),'k-'那“线宽”,2)持有离开传奇({'md1'那“MD1SW”那'md1swa'},'地点'那'n')xlabel('年')ylabel('剩余的')头衔('{\ bf模型残差(差异数据)}')轴心紧网格在
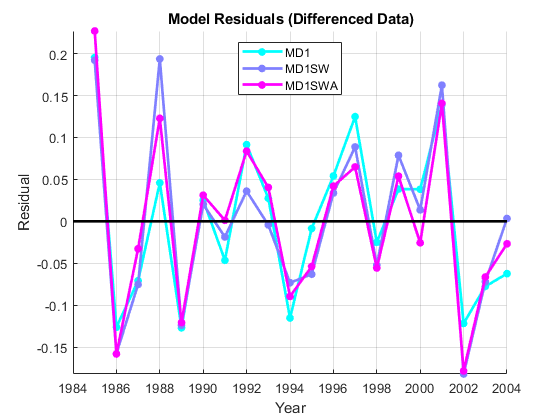
对于每个模型,剩余散射围绕零的平均值,因为它们应该没有明显的趋势或表明误操作的模式。残差的比例是几个数量级,比原始数据的比例(参见示例时间序列回归I:线性模型),这是模型已经捕获了数据生成过程(DGP)的重要部分的标志。似乎有一些持续存在的持续存在或负面偏离的自相关的证据,特别是在未经定罪的数据中。少量的异源性也是显而易见的,但是难以进行视觉评估,以将其与这种小样本中的随机变化分开。
自相关
在自相关的存在下,OLS估计仍然是无偏的,但它们不再在无偏估计之间具有最小差异。这是小型样本中的一个重要问题,其中置信区间将相对较大。复杂问题,自相关,甚至渐近地引入标准方差估计的偏差。由于经济数据中的自相关可能是正的,因此反映了类似的随机因素,并且从一个时间段延伸到下一个时间段,方差估计趋于向下偏向T.-过度乐观的准确性检验。结果是区间估计和假设检验变得不可靠。更保守的显著性水平T.- 建议。估计的鲁棒性取决于影响当前观察的自相关的程度或持久性。
这自动变动函数没有输出参数,产生残差的自动化图,并在剩余自相关结构上快速视觉占据:
图AutoCorR(Res0)标题(“{\bf M0剩余自相关}”)
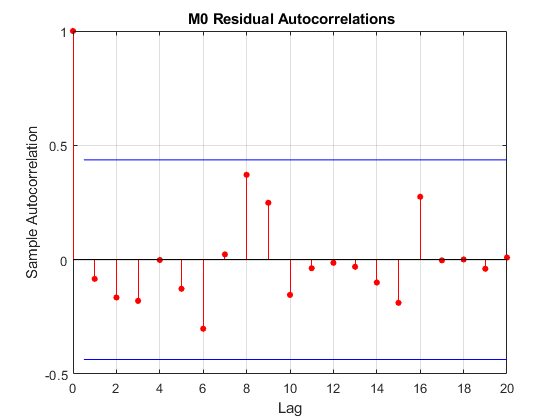
没有蓝线给出的白噪声的Bartlett双标准频带之外没有自相关的证据。
杜宾-沃森统计[3]是计量经济分析中最常报告的自相关度量。原因之一是它易于计算。对于M0.模型:
衍射0=diff(res0);SSE0=res0'*res0;DW0=(衍射0'*衍射0)/SSE0%Durnin-Watson统计
dw0 = 2.1474.
在静止的假设下,通常分布式创新,统计数据约为
哪里
是一阶(单滞后)自相关估计自动变动:
rho0=自动相关(res0,'numlags',1);滞后的%样本自相关,0,1dw0normal = 2 *(1-rho0(2))
dw0normal = 2.1676
附近的统计数据不提供一级自相关的证据。合适的P.- 统计价值是由...计算的DWTest.方法LinearModel班级:
[pValueDW0,DW0]=dwtest(M0)
pValueDW0=0.8943
dw0 = 2.1474.
这P.-Value对于无一级自相关的NULL远高于标准的5%临界值。
传统上,经济学家传统上依靠经验法则,即Durbin-Watson统计量低于约1.5,是怀疑正面自相关的理由。这种临时关键值忽略了对样本大小的依赖性,但由于忽略自相关的严重后果,这是一种保守的指导。
Durbin-Watson测试虽然传统上很受欢迎,但有很多缺点。除了静止,正常分布式创新的假设之外,它可以检测一阶自相关的能力,它对其他模型误操作非常敏感。也就是说,它对未设计测试的许多替代品是强大的。在存在滞后的响应变量时,它也无效(请参阅示例时间序列回归VIII:滞后变量和估计偏差)。
容格盒子问:-测试[5]由函数实施LBQTEST.,测试“总体”或“Portmanteau”缺乏自相关。它认为滞后于指定的订单L.等等是一阶Durbin-Watson测试的自然延伸。以下测试M0.自相关的残差L.=5、10和15:
[HLBQ0,PVALUELBQ0] = LBQTEST(RES0,'滞后',[5,10,15])
HLBQ0 =1 x3逻辑阵列0 0 0
pValueLBQ0 =1×3.0.8175 0.1814 0.2890
在默认的5%重要性级别,测试无法拒绝每个扩展滞后结构中没有自相关的NULL。结果类似于MD1.模型,但要高得多P.-Values表示拒绝空缺的证据
[HLBQD1,PvaluelBQD1] = LBQTEST(RESD1,'滞后',[5,10,15])
hLBQD1=1 x3逻辑阵列0 0 0
pvaluelbqd1 =1×3.0.9349 0.7287 0.9466
这问:- 最低的缺点也有其缺点。如果L.太小,测试不会检测到更高阶的自相关。如果它太大,则测试将失去功率,因为可以通过在其他滞后的无关紧要的相关性在任何滞后进行显着相关性。此外,该测试对于除自相关之外的串行依赖项是强大的。
另一个缺点问:- 测试是测试使用的默认的Chi-Square分布是渐近的,并且可以在小样本中产生不可靠的结果。对于ARMA(P.那问:)开发测试的模型,如果通过估计系数的数量减少了自由度的数量,则获得更准确的分布,P.+问:。但这限制了测试的值L.比...更棒P.+问:,因为自由度必须是积极的。可以对一般回归模型进行类似的调整,但是LBQTEST.默认情况下不这样做。
另一个测试“总体”缺乏自相关是一个运行测试由函数实施runstest.,确定残差的符号是否系统地从零系统偏离。测试寻找长期相同的标志(正自动相关)或交替标志(否定自相关):
[hrt0,pvaluert0] = runstest(Res0)
hrt0 = 0.
pValueRT0=0.2878
测试未能拒绝残留的残差中的无随机性M0.模型。
自相关残差可能是一个重要规格错误的符号,其中省略了,自相关的变量已成为创新过程的隐式组成部分。缺少这些变量可能的任何理论建议,典型的补救措施是在预测器中包括响应变量的滞后值,滞后于自相关的顺序。然而,将这种动态依赖性引入模型,是静态MLR规范的重要偏离。动态模型出现了相对于CLM假设的一组新的考虑因素,并在该示例中考虑时间序列回归VIII:滞后变量和估计偏差。
异方差
异方差发生时,预测和创新过程的方差,在总体上,在响应中产生一个条件方差。这种现象通常与横断面数据有关,在横断面数据中,测量误差的系统性变化可能发生在观测数据之间。在时间序列数据中,异方差通常是模型预测器和被忽略变量之间相互作用的结果,这也是基本错误说明的另一个标志。在存在异方差的情况下,OLS估计显示出与自相关估计几乎相同的问题;它们是无偏的,但在无偏估计量之间不再有最小方差,估计量方差的标准公式变得有偏。然而,蒙特卡罗研究表明,对区间估计的影响通常是相当小的[1]。除非异源性是发音,否则标准误差的变形小,并且显着的测试在很大程度上不受影响。随着大多数经济数据,与自相关的影响相比,异源性的影响将是微小的。
恩格尔的拱门测试[4],由此实施主角函数,是一个用于识别残差异方差的检验的例子。它评估了一系列残差的零假设
不表现出条件异方差(ARCH效应),与ARCH(L.) 模型
描述至少一个非零的系列 为了 。这里 是一个独立的创新过程。ARCH过程中的残差是相依的,但不相关,因此该测试是针对没有自相关的异方差。
将测试应用于M0.残留系列与滞后L.= 5,10和15给出:
[harch0,parch0] = archtest(Res0,'滞后',[5,10,15])
哈奇=1 x3逻辑阵列0 0 0
parch0 =1×3.0.4200 0.3575 0.9797
该测试未发现残差中存在异方差的证据MD1.模型的证据更弱:
[hARCHD1,pARCHD1]=archtest(resD1,'滞后',[5,10,15])
hARCHD1=1 x3逻辑阵列0 0 0
parchd1 =1×3.0.5535 0.4405 0.9921
分配
Gauss-Markov定理不需要创新过程通常分布的假设,但是必须使用标准技术构建置信区间,以及T.和F提供预测显著性准确评估的测试。该假设在小样本情况下尤其重要,因为在小样本情况下,无法依赖中心极限定理来提供近似正态分布的估计值,而与创新点的分布无关。
通常对正常假设的理由是创新是固有的随机性的总和加上回归中省略的所有变量。中央限位定理说,随着省略变量的数量增加,该和将接近正常性。然而,这一结论取决于省略的变量彼此独立,并且在实践中通常不合理。因此,对于小样本,无论均恢复和异源性的结果如何,检查正常性假设是准确规范的重要组成部分。
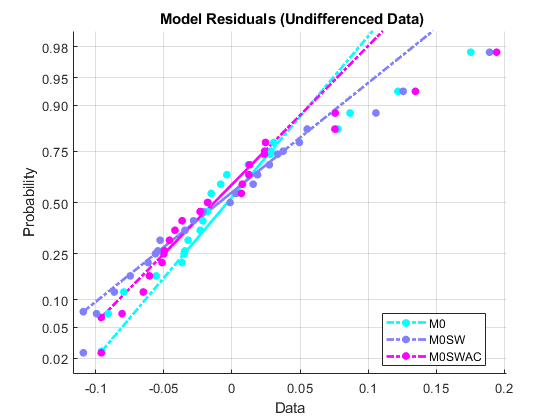
残差序列的正态概率图给出了快速评估:
图HNPLOT0 = NOMPLOT(MODEM0RES);传奇({'m0'那'm0sw'那'm0swac'},'地点'那'最好的事物')头衔('{\ BF模型残差(无论数据)}')设置(hNPlot0'标记'那'。')设置(hnplot0([1 4 7]),“颜色”,地图(1,:))设置(HNPlot0([2 5 8]),“颜色”,映射(2,:)集(hNPlot0([3 6 9]),“颜色”地图(3)):集(hNPlot0,“线宽”,2)设置(hnplot0,'Markersize',20)
图hNPlotD1 = normplot(modelD1Res);传奇({'md1'那“MD1SW”那'md1swa'},'地点'那'最好的事物')头衔('{\ bf模型残差(差异数据)}')设置(hnplotd1,'标记'那'。')SET(HNPLOTD1([1 4 7]),“颜色”,地图(1,:))设置(HNPlotd1([2 5 8]),“颜色”,地图(2,:))设置(HNPlotd1([3 6 9]),“颜色”,映射(3,:)集(hNPlotD1,“线宽”,2)SET(HNPLOTD1,'Markersize',20)

曲线图显示了经验概率与残值的关系。实线连接数据中的第25个和第75个百分位,然后用虚线延伸。垂直刻度是非线性的,刻度线之间的距离等于正常分位数之间的距离。如果数据落在直线附近,则正态性假设是合理的。在这里,我们看到残差较大的数据明显偏离正态性(同样,尤其是在无差异数据中),这表明分布可能是偏斜的。很明显,删除了示例中考虑的最具影响力的观察结果时间序列回归III:有影响力的观察,将改善残留的正常性。
通过适当的测试来确认任何视觉分析都是一个好主意。对于分布假设有很多统计测试,但是Lilliefors测试由莉莉亚特功能,是专为小型样本设计的正常性测试:
[hnorm0,pnorm0] = lillizest(Res0)
hNorm0 = 1
pnorm0 = 0.0484
在默认的5%的重要性水平下,测试拒绝了正常性M0.系列,但几乎没有。测试发现没有理由拒绝正常性MD1.数据:
s=警告(“关”那'统计:Lillieft:Outofrangephigh');%关闭小的统计警告[hNormD1,pNormD1]=lillietest(resD1)
hnormd1 = 0.
PnorMD1 = 0.5000.
警告%恢复警告状态
统计数据位于标记值表的边缘莉莉亚特,最大的P.-值已报告。
非通量的常见补救措施是将Box-Cox转换应用于响应变量[2]。与主要用于产生线性度并促进趋势移除的预测器的日志和功率变换不同,盒COX转换旨在产生残留物中的正常性。它们通常具有规则化残差方差的有益副作用。
集体,Box-Cox转换形成一个参数化家庭日志和标准化的电力转换为特殊情况。使用参数的转换
替换响应变量
有变量:
为了 对于 ,转换由其限制值,log( )。
这Boxcox.金融工具箱中的功能查找参数
最大化残差的正常伐木。将功能应用于IGD数据输入y0.,有必要对零违约率进行干扰,使其变为正的:
alpha = 0.01;y0(y0 == 0)= alpha;%y0bc = boxcox(y0);金融工具箱%y0BC = [-3.5159 -1.6942 -3.5159 -3.5159 -1.7306 -1.7565 -1.4580 -3.5159 -3.5159 -2.4760 -2.5537 -3.5159 -2.1858 -1.7071 -1.7277 -1.5625 -1.4405 -0.7422 -2.0047 -3.5159 -2.8346];
变换对的值是敏感的α,这增加了分析的水平并发症。但是,LipleieFors测试证实,转变具有所需的效果:
M0BC=fitlm(X0,y0BC);res0BC=M0BC.Residuals.Raw;[hNorm0BC,pNorm0BC]=lillietest(res0BC)
hnorm0bc = 0.
PnorM0BC = 0.4523
警告%恢复警告状态
由于在原始残差序列中非正态性的证据是轻微的,我们不追求对Box-Cox变换的微调。
总结
残差分析的基本目的是检查CLM假设并寻找模型错误说明的证据。残差中的模式表明有机会重新说明,以获得更准确的OLS系数估计、更强的解释力和更好的预测性能的模型。
不同的模型可以表现出类似的残余特性。如果是,则可能需要在预测阶段保留和进一步评估替代模型。从预测角度来看,如果模型成功地代表了数据中的所有系统信息,那么残差应该是白噪声。也就是说,如果创新是白噪声,而模型模仿DGP,则一步预测错误应该是白噪声。模型残留是这些样本预测错误的采样措施。预测性能在该示例中讨论时间序列回归七:预测。
与非白人创新有关的OLS估计问题,加上重新指定许多经济模型的选择有限,导致考虑更稳健异源性和自相关(HAC)方差估计,如Hansen-White和Newey-West估计,它们消除了渐近(虽然不是小样本)偏差广义最小二乘(GLS),也用于估计这些情况下的系数。GLS的设计目的是给予较大残差的有影响的观测值更低的权重。GLS估计器是BLUE(参见示例)时间序列回归I:线性模型),并等价于新息为正态时的最大似然估计(MLE)时间序列回归X:广义最小二乘和HAC估计。
参考文献
[1]博恩施泰特,g.w.和t.m.卡特。“回归分析中的稳健性”。在社会学方法论,H. L. Costner,编辑,第118-146页。旧金山:Jossey-Bass,1971。
[2]博克斯、G.E.P.和D.R.Cox.“转换分析”。皇家统计社会杂志.B辑,第26卷,1964年,第211-252页。
[3]Durbin,J.和G.S. Watson。“测试以最小二乘回归的串行相关性。”Biometrika1950年第37卷,第409-428页。
[4]埃格尔,罗伯特。F.“自归条件异源性,估计英国通胀差异。”计量经济学50(1982年7月):987-1007。https://doi.org/10.2307/1912773。
[5]Ljung,G.和G. E. P. Box。“关于时间序列模型缺乏适合的措施。”Biometrika1978年第66卷,第67-72页。
您还可以从以下列表中选择一个网站:
