时间序列回归V:预测选择gydF4y2Ba
这个例子展示了如何选择一套简洁的预测与多元线性回归模型的统计显著性高。这是第五在一系列时间序列回归的例子,表示在之前的例子。gydF4y2Ba
介绍gydF4y2Ba
什么是“最好的”预测的多元线性回归模型(高)?没有回答这个问题的理论基础,模型可能,至少在最初阶段,包括一个混合的“潜在”预测,降低质量的OLS估计和混淆识别重要的影响。gydF4y2Ba
理想情况下,一组预测将有以下特点:gydF4y2Ba
每一个预测导致的变化响应(必要性和吝啬)gydF4y2Ba
没有额外的预测导致的变化响应(充足)gydF4y2Ba
没有额外的显著预测因子变化的系数估计(稳定)gydF4y2Ba
的现实经济模型,然而,使它具有挑战性的找到这样一组。首先,有省略的必然性,重要预测因子,导致模型与偏见和低效的系数估计。在本系列的其他例子讨论相关的挑战,如预测之间的相关性,预测和省略变量之间的相关性,有限样本变异,非典型数据,等等,所有这些构成问题纯粹统计选择“最好”的预测。gydF4y2Ba
自动选择技术使用统计学意义,尽管它的缺点,作为替代理论意义。这些技术通常选择一个“最佳”的预测通过最小化预测误差的一些措施。优化约束是用来表示要求或排除预测,或设置的大小最终模型。gydF4y2Ba
在前面的例子gydF4y2Ba时间序列回归四:伪回归gydF4y2Ba,这是暗示某些转换的预测可能是有益的生产更准确的预测模型。选择预测gydF4y2Ba之前gydF4y2Ba转换的优点是保留原来的单位,这可能是重要的识别有意义且具有统计学意义的一个子集。通常,选择和转换技术一起使用,建模实现一个简单的目标,但仍然准确,响应的预测模型。gydF4y2Ba
检查选择技术,我们首先从前面的示例加载相关数据gydF4y2Ba时间序列回归四:伪回归gydF4y2Ba:gydF4y2Ba
负载gydF4y2BaData_TSReg4gydF4y2Ba
供参考,我们显示模型完整的预测水平和差异:gydF4y2Ba
M0gydF4y2Ba
M0 =线性回归模型:IGD ~ 1 +年龄+ BBB +公积金+ SPR估计系数:估计SE tStat pValue替_________ _____(拦截)-0.22741 0.098565 -2.3072 0.034747 BBB年龄0.016781 0.0091845 1.8271 0.086402 0.0042728 0.0026757 1.5969 0.12985论坛-0.014888 0.045488 0.033996 1.338 0.1996 0.0038077 -3.91 0.0012473 SPR的观测数量:21日误差自由度:16根均方误差:0.0763平方:0.621,调整平方:0.526 f统计量与常数模型:6.56,p = 0.00253gydF4y2Ba
MD1gydF4y2Ba
MD1 =线性回归模型:D1IGD ~ 1 +年龄+ D1BBB + D1CPF + D1SPR估计系数:估计SE tStat pValue替________ _____岁(拦截)-0.089492 0.10843 -0.82535 0.4221 0.015193 0.012574 1.2083 0.24564 D1BBB D1SPR D1CPF 0.25909 -0.023538 0.020066 -1.173 -0.015707 0.0046294 -3.393 0.0040152 -0.03663 0.04017 -0.91187 0.37626的观测数量:20日误差自由度:15根均方误差:0.106平方:0.49,调整平方:0.354 f统计量与常数模型:3.61,p = 0.0298gydF4y2Ba
逐步回归gydF4y2Ba
许多预测方法选择使用gydF4y2BatgydF4y2Ba估计系数的统计,gydF4y2BaFgydF4y2Ba统计组的系数,测量统计学意义。使用这些数据时,我们必须记住,省略预测与无关紧要的个人贡献可以隐藏一个重要的共同贡献。同时,gydF4y2BatgydF4y2Ba和gydF4y2BaFgydF4y2Ba统计数据可以可靠的存在共线性或趋势变量。因此,数据问题应该解决之前预测的选择。gydF4y2Ba
逐步回归gydF4y2Ba是一个系统化的程序添加和删除高预测基于gydF4y2BaFgydF4y2Ba统计数据。这个过程始于一个初始子集的潜在因素,包括任何理论上认为是重要的。在每一步,gydF4y2BapgydF4y2Ba价值的gydF4y2BaFgydF4y2Ba统计(即a的平方gydF4y2BatgydF4y2Ba统计一个相同的gydF4y2BapgydF4y2Ba计算值)比较有和没有的一个潜在的预测模型。如果预测当前没有在模型中,零假设是,它将有一个零系数如果添加到模型中。如果有足够的证据拒绝零假设,预测是添加到模型中。相反,如果预测目前模型中,零假设是,它有一个零系数。如果没有足够的证据拒绝零假设,预测从模型中删除。在任何步骤,过程可能会删除已经添加或添加的预测预测,已被移除。gydF4y2Ba
逐步回归收益如下:gydF4y2Ba
初始模型。gydF4y2Ba
如果任何预测模型gydF4y2BapgydF4y2Ba公差值不到一个入口(也就是说,如果它是不可能会零系数如果添加到模型),添加一个最小的gydF4y2BapgydF4y2Ba值和重复这个步骤;否则,进入步骤3。gydF4y2Ba
如果任何预测模型gydF4y2BapgydF4y2Ba值大于退出公差(也就是说,如果它是不太可能的假设零系数可以被拒绝),去掉最大的gydF4y2BapgydF4y2Ba值到步骤2;否则,结束。gydF4y2Ba
根据初始模型和预测的顺序,移动的过程可能会建立不同的模型相同的一组潜在的预测因子。程序终止时没有一个一步改善模型。没有保证,然而,不同初始模型和不同序列的步骤并不会导致一个更好的选择。从这个意义上讲,分段模型的局部最优,但可能不是全局最优。这个过程仍然是有效避免潜在的预测评估所有可能的子集,在实践中,经常产生有用的结果。gydF4y2Ba
这个函数gydF4y2BastepwiselmgydF4y2Ba(相当于静态方法gydF4y2BaLinearModel.stepwisegydF4y2Ba)自动进行逐步回归。默认情况下,它包括一个常数模型中,从一个空的预测因子,并使用入口/出口上公差gydF4y2BaFgydF4y2Ba统计gydF4y2BapgydF4y2Ba值的0.05/0.10。以下适用于gydF4y2BastepwiselmgydF4y2Ba原始的潜在的预测因子,设定一个上限的gydF4y2Ba线性gydF4y2Ba模型,限制了程序不包括平方或交互条款当寻找最低的模型的均方根误差(RMSE):gydF4y2Ba
M0SW = stepwiselm(数据表,gydF4y2Ba“上”gydF4y2Ba,gydF4y2Ba“线性”gydF4y2Ba)gydF4y2Ba
1。添加论坛,FStat = 6.22, pValue = 0.022017 - 2。添加BBB, FStat = 10.4286, pValue = 0.00465235gydF4y2Ba
M0SW =线性回归模型:IGD ~ 1 + BBB +论坛估计系数:估计SE tStat pValue替_________ __________ BBB(拦截)-0.087741 0.071106 -1.234 0.23309 0.0074389 -0.016187 0.0039682 -4.0792 0.00070413 0.0023035 3.2293 0.0046523 CPF的观测数量:21日误差自由度:18根均方误差:0.0808平方:0.523,调整平方:0.47 f统计量与常数模型:9.87,p = 0.00128gydF4y2Ba
显示在终端显示了积极的预测。的gydF4y2BaFgydF4y2Ba测试选择两个预测最优联合意义,gydF4y2BaBBBgydF4y2Ba和gydF4y2Ba论坛gydF4y2Ba。这些都不是最重要的预测因子gydF4y2BatgydF4y2Ba统计数据,gydF4y2Ba年龄gydF4y2Ba和gydF4y2Ba论坛gydF4y2Ba完整的模型gydF4y2BaM0gydF4y2Ba。0.0808,降低模型的RMSE RMSE可比的gydF4y2BaM0gydF4y2Ba0.0763点。轻微的增加是吝啬的价格。gydF4y2Ba
相比之下,我们应用过程的全套差预测(gydF4y2Ba年龄gydF4y2Baundifferenced)gydF4y2BaMD1gydF4y2Ba:gydF4y2Ba
MD1SW = stepwiselm (D1X0 D1y0,gydF4y2Ba“上”gydF4y2Ba,gydF4y2Ba“线性”gydF4y2Ba,gydF4y2Ba“VarNames”gydF4y2Ba(predNamesD1 respNameD1])gydF4y2Ba
1。添加D1CPF, FStat = 9.7999, pValue = 0.0057805gydF4y2Ba
MD1SW =线性回归模型:D1IGD ~ 1 + D1CPF估计系数:估计SE tStat pValue替_________ _____(拦截)D1CPF 0.69649 0.0097348 0.024559 0.39638 -0.014783 0.0047222 -3.1305 0.0057805的观测数量:20日误差自由度:18根均方误差:0.109平方:0.353,调整平方:0.317 f统计量与常数模型:9.8,p = 0.00578gydF4y2Ba
减少模型的RMSE, 0.109,再次是可比的gydF4y2BaMD1gydF4y2Ba0.106点。逐步过程削减了单个预测模型,gydF4y2BaD1CPFgydF4y2Ba,小得多gydF4y2BapgydF4y2Ba价值。gydF4y2Ba
RMSE,当然,并不是预测性能的保证,尤其是小样本。因为有一个理论依据包括信用违约的老化效应的模型gydF4y2Ba[5]gydF4y2Ba,我们可能需要力量gydF4y2Ba年龄gydF4y2Ba到模型中。这是在通过修复完成gydF4y2BaD1IGD ~年龄gydF4y2Ba作为初始模型和下界在所有模型认为:gydF4y2Ba
MD1SWA = stepwiselm (D1X0 D1y0,gydF4y2Ba“D1IGD ~年龄”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“低”gydF4y2Ba,gydF4y2Ba“D1IGD ~年龄”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“上”gydF4y2Ba,gydF4y2Ba“线性”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“VarNames”gydF4y2Ba(predNamesD1 respNameD1])gydF4y2Ba
1。添加D1CPF, FStat = 10.9238, pValue = 0.00418364gydF4y2Ba
MD1SWA =线性回归模型:D1IGD ~ 1 +年龄+ D1CPF估计系数:估计SE tStat pValue替_________ _____岁(拦截)-0.11967 0.10834 -1.1047 0.2847 0.015463 0.012617 1.2255 0.23708 D1CPF -0.015523 0.0046967 -3.3051 0.0041836的观测数量:20日误差自由度:17根均方误差:0.108平方:0.405,调整平方:0.335 f统计量与常数模型:5.79,p = 0.0121gydF4y2Ba
RMSE略有减少,突出本地搜索的性质。出于这个原因,建议多个逐步搜索,向前向后从一个空的初始模型,从一个完整的初始模型,在理论上解决任何重要的预测因子。局部最小值的比较,理论的背景下,产生了最可靠的结果。gydF4y2Ba
逐步回归过程可以更详细地检查了使用功能gydF4y2Ba逐步gydF4y2Ba在每一步,它允许交互,这个函数gydF4y2BaExample_StepwiseTracegydF4y2Ba,它显示系数估计整个选拔过程的历史。gydF4y2Ba
信息标准gydF4y2Ba
逐步回归比较嵌套模型,使用gydF4y2BaFgydF4y2Ba相当于似然比测试的测试。比较模型,没有扩展或限制对方,gydF4y2Ba信息标准gydF4y2Ba(IC)是经常使用。有几种常见的品种,但所有试图平衡衡量样本符合惩罚系数增加的数量模型。Akaike信息准则(AIC)和贝叶斯信息准则(BIC)计算的gydF4y2BaModelCriteriongydF4y2Ba的方法gydF4y2BaLinearModelgydF4y2Ba类。我们比较措施使用全套的预测水平和差异:gydF4y2Ba
AIC0 = M0.ModelCriterion.AICgydF4y2Ba
AIC0 = -44.1593gydF4y2Ba
BIC0 = M0.ModelCriterion.BICgydF4y2Ba
BIC0 = -38.9367gydF4y2Ba
AICD1 = MD1.ModelCriterion.AICgydF4y2Ba
AICD1 = -28.7196gydF4y2Ba
BICD1 = MD1.ModelCriterion.BICgydF4y2Ba
BICD1 = -23.7410gydF4y2Ba
因为两个模型估计相同数量的系数,AIC和BIC有利gydF4y2BaM0gydF4y2Ba,RMSE低。gydF4y2Ba
我们可能还想比较gydF4y2BaMD1gydF4y2Ba最好的减少了逐步回归模型发现,gydF4y2BaMD1SWAgydF4y2Ba:gydF4y2Ba
AICD1SWA = MD1SWA.ModelCriterion.AICgydF4y2Ba
AICD1SWA = -29.6239gydF4y2Ba
BICD1SWA = MD1SWA.ModelCriterion.BICgydF4y2Ba
BICD1SWA = -26.6367gydF4y2Ba
两个措施是减少由于更少的系数估计,但是这个模式仍然没有弥补RMSE相对增加gydF4y2BaM0gydF4y2Ba从差分改正,导致伪回归。gydF4y2Ba
交叉验证gydF4y2Ba
另一个常见的模式比较技术gydF4y2Ba交叉验证gydF4y2Ba。像信息标准,交叉验证可以用来比较嵌套模型,并惩罚模型过度拟合。所不同的是,交叉验证评估模型的上下文中样本外预测性能,而不是样本。gydF4y2Ba
在标准的交叉验证,数据随机分割成一个gydF4y2Ba训练集gydF4y2Ba和一个gydF4y2Ba测试集gydF4y2Ba。用训练集模型系数估计,然后用来预测响应值在测试集。随机打乱,训练集和测试集和过程反复进行。预测误差小,平均而言,在所有的测试集,显示良好的预测性能的预测模型。没有需要调整系数的数量,在信息的标准,因为不同的数据用于拟合和估计。过度拟合预测性能变得明显。gydF4y2Ba
交叉验证是一个泛化的“分裂样”或“伸出”技术,在只有一个子集用于估计预测误差。统计证据表明,交叉验证是一个更好的过程对于小数据集gydF4y2Ba[2]gydF4y2Ba。渐近,最小化线性模型的交叉验证错误相当于AIC和BIC最小化gydF4y2Ba[6]gydF4y2Ba,gydF4y2Ba[7]gydF4y2Ba。gydF4y2Ba
对于时间序列数据,过程有一些并发症。时间序列数据一般不独立,所以随机训练集来自任何地方的时基可以与随机测试集。在这种情况下交叉验证可以表现不正常gydF4y2Ba[3]gydF4y2Ba。一种解决方案是为一个测试gydF4y2Ba 这样的观察时间gydF4y2Ba 不相关的观察时间吗gydF4y2Ba 为gydF4y2Ba (见示例gydF4y2Ba时间序列回归VI:残留的诊断gydF4y2Ba),然后选择有足够的训练集和测试集分离。另一个解决方案是使用足够的许多测试集,是由随机抽样冲毁的相关性影响。这个过程可以重复使用测试集的大小不同,可以评估和结果的敏感性。gydF4y2Ba
交叉验证是由标准gydF4y2BacrossvalgydF4y2Ba函数。默认情况下,数据是随机划分为10个次级样本,每一个都是使用一次作为测试集(10倍交叉验证)。然后计算平均均方误差测试。以下比较gydF4y2BaM0gydF4y2Ba来gydF4y2BaMD1SWAgydF4y2Ba。因为数据~ 20观察undifferenced数据(一个),默认的测试集的大小2:gydF4y2Ba
yFit = @ (XTrain yTrain XTest) (XTest *回归(yTrain XTrain));cvMSE0 = crossval (gydF4y2BaMSE的gydF4y2Ba,X0, y0,gydF4y2Ba“predfun”gydF4y2Ba,yFit);cvRMSE0 =√cvMSE0gydF4y2Ba
cvRMSE0 = 0.0954gydF4y2Ba
cvMSED1SWA = crossval (gydF4y2BaMSE的gydF4y2BaD1X0 (: 1 [3]), D1y0,gydF4y2Ba“predfun”gydF4y2Ba,yFit);cvRMSED1SWA =√cvMSED1SWAgydF4y2Ba
cvRMSED1SWA = 0.1409gydF4y2Ba
rms略高于那些发现以前,0.0763和0.108,分别支持完整的,原始的预测因子。gydF4y2Ba
套索gydF4y2Ba
最后,我们考虑到绝对最小收缩和选择算子,或gydF4y2Ba套索gydF4y2Ba[4]gydF4y2Ba,gydF4y2Ba[8]gydF4y2Ba。拉索是一种正则化技术类似于岭回归(在这个例子中讨论gydF4y2Ba时间序列回归二世:共线性和估计方差gydF4y2Ba),但是有一个重要的区别是它有助于预测选择。考虑以下,相当于岭估计的公式:gydF4y2Ba
在哪里gydF4y2Ba 错误(残余)回归平方和。从本质上讲,岭估计量最小化gydF4y2Ba 虽然惩罚对于大型系数gydF4y2Ba 。作为岭参数gydF4y2Ba 增加,惩罚收缩系数估计对0为了减少近共线生产的大方差预测。gydF4y2Ba
套索估计也有类似的公式:gydF4y2Ba
点球的变化看起来微不足道,但它影响了估计量的重要方面。像岭估计量,gydF4y2Ba 是偏向零(蓝色)放弃“U”。然而,不同于岭估计量gydF4y2Ba 不是线性响应值gydF4y2Ba (蓝色)放弃“L”。这从根本上改变了估计过程的性质。新的几何允许系数估计为有限值的减少为零gydF4y2Ba ,有效地选择预测的一个子集。gydF4y2Ba
套索的实现gydF4y2Ba套索gydF4y2Ba函数。默认情况下,gydF4y2Ba套索gydF4y2Ba估计的回归参数的范围gydF4y2Ba
,计算每个值的均方误差。我们设置gydF4y2Ba“简历”gydF4y2Ba10计算为了10倍交叉验证。这个函数gydF4y2BalassoPlotgydF4y2Ba显示的系数估计的痕迹:gydF4y2Ba
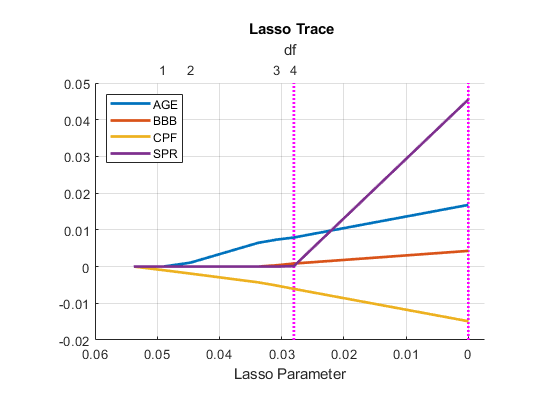
[lassoBetas, lassoInfo] =套索(X0, y0,gydF4y2Ba“简历”gydF4y2Ba10);[hax, hfig] = lassoPlot (lassoBetas lassoInfo,gydF4y2Ba“PlotType”gydF4y2Ba,gydF4y2Ba“λ”gydF4y2Ba);hax。XGrid =gydF4y2Ba“上”gydF4y2Ba;hax。YGrid =gydF4y2Ba“上”gydF4y2Ba;hax。GridLineStyle =gydF4y2Ba“- - -”gydF4y2Ba;hax.Title。字符串=gydF4y2Ba{}\ bf套索跟踪的gydF4y2Ba;hax.XLabel。字符串=gydF4y2Ba“拉索参数”gydF4y2Ba;hlplot = hax.Children;hms = hlplot (6);htraces = hlplot (4: 1:1);集(hlplot,gydF4y2Ba“线宽”gydF4y2Ba2)组(hmsgydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“米”gydF4y2Ba)传说(htraces predNames0,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“西北”gydF4y2Ba)gydF4y2Ba
hfig。HandleVisibility =gydF4y2Ba“上”gydF4y2Ba;gydF4y2Ba
更大的值gydF4y2Ba 出现在左边,右边的OLS估计,扭转方向的一个典型的山脊痕迹。的自由度模型(非零系数估计)的数量增加从左到右,顶部的阴谋。冲垂直线显示gydF4y2Ba 值和最小均方误差(右边)和最小均方误差+ 1标准错误(左边)。在这种情况下,最小值出现的OLS估计,gydF4y2Ba ,至于岭回归。one-standard-error值通常是用来指导选择一个较小的模型具有良好的健康gydF4y2Ba[1]gydF4y2Ba。gydF4y2Ba
情节表明gydF4y2Ba年龄gydF4y2Ba和gydF4y2Ba论坛gydF4y2Ba作为最初的预测可能的子集。我们执行另一个与这些预测被迫逐步回归模型:gydF4y2Ba
M0SWAC = stepwiselm (X0, y0,gydF4y2Ba“IGD ~年龄+论坛”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“低”gydF4y2Ba,gydF4y2Ba“IGD ~年龄+论坛”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“上”gydF4y2Ba,gydF4y2Ba“线性”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba“VarNames”gydF4y2Ba(predNames0 respName0])gydF4y2Ba
1。添加BBB, FStat = 4.9583, pValue = 0.039774gydF4y2Ba
M0SWAC =线性回归模型:IGD ~ 1 +年龄+ BBB +论坛估计系数:估计SE tStat pValue替_________ _____岁(拦截)-0.14474 0.078556 -1.8424 0.082921 0.013621 0.0090796 1.5001 0.15192 BBB论坛-0.015299 0.0038825 -3.9405 0.039774 0.0056359 0.002531 2.2267 0.0010548的观测数量:21日误差自由度:17根均方误差:0.0781平方:0.579,调整平方:0.504 f统计量与常数模型:7.79,p = 0.00174gydF4y2Ba
回归也移动gydF4y2BaBBBgydF4y2Ba到模型,生成的RMSE值为0.0808时发现以下早些时候通过逐步回归从一个空的初始模型,gydF4y2BaM0SWgydF4y2Ba,选择gydF4y2BaBBBgydF4y2Ba和gydF4y2Ba论坛gydF4y2Ba一个人。gydF4y2Ba
因为包括gydF4y2BaBBBgydF4y2Ba增加数量的估计系数,我们使用AIC和BIC 2-predictor模型比较更加节俭gydF4y2BaM0ACgydF4y2Ba发现的套索3-predictor扩展模型gydF4y2BaM0SWACgydF4y2Ba:gydF4y2Ba
M0AC = fitlm(数据表(:,(1 3 5)))gydF4y2Ba
M0AC =线性回归模型:IGD ~ 1 +年龄+论坛估计系数:估计SE tStat pValue替________ _____岁(拦截)-0.056025 0.074779 -0.74921 0.46341 0.023221 0.0088255 2.6311 0.016951论坛-0.011699 0.0038988 -3.0008 0.0076727的观测数量:21日误差自由度:18根均方误差:0.0863平方:0.456,调整平方:0.395 f统计量与常数模型:7.54,p = 0.00418gydF4y2Ba
AIC0AC = M0AC.ModelCriterion.AICgydF4y2Ba
AIC0AC = -40.5574gydF4y2Ba
BIC0AC = M0AC.ModelCriterion.BICgydF4y2Ba
BIC0AC = -37.4238gydF4y2Ba
AIC0SWAC = M0SWAC.ModelCriterion.AICgydF4y2Ba
AIC0SWAC = -43.9319gydF4y2Ba
BIC0SWAC = M0SWAC.ModelCriterion.BICgydF4y2Ba
BIC0SWAC = -39.7538gydF4y2Ba
较低的RMSE足以弥补额外的预测,和两个标准选择3-predictor模型在2-predictor模型。gydF4y2Ba
对比模型gydF4y2Ba
这里所描述的程序建议的简化模型与统计特征与模型与原始的全套,或差,预测。我们总结一下结果:gydF4y2Ba
M0gydF4y2Ba与原来的预测模型,gydF4y2Ba年龄gydF4y2Ba,gydF4y2BaBBBgydF4y2Ba,gydF4y2Ba论坛gydF4y2Ba,gydF4y2BaSPRgydF4y2Ba。gydF4y2Ba
M0SWgydF4y2Ba子模型的gydF4y2BaM0gydF4y2Ba通过逐步回归发现,从一个空模型。它包括gydF4y2BaBBBgydF4y2Ba和gydF4y2Ba论坛gydF4y2Ba。gydF4y2Ba
M0SWACgydF4y2Ba子模型的gydF4y2BaM0gydF4y2Ba通过逐步回归发现,从一个部队的模型gydF4y2Ba年龄gydF4y2Ba和gydF4y2Ba论坛gydF4y2Ba。建议由套索。它包括gydF4y2Ba年龄gydF4y2Ba,gydF4y2BaBBBgydF4y2Ba,gydF4y2Ba论坛gydF4y2Ba。gydF4y2Ba
MD1gydF4y2Ba与原来的预测模型gydF4y2Ba年龄gydF4y2Ba和差的预测gydF4y2BaD1BBBgydF4y2Ba,gydF4y2BaD1CPFgydF4y2Ba,gydF4y2BaD1SPRgydF4y2Ba。提出了集成和平稳性测试的例子gydF4y2Ba时间序列回归四:伪回归gydF4y2Ba。gydF4y2Ba
MD1SWgydF4y2Ba子模型的gydF4y2BaMD1gydF4y2Ba通过逐步回归发现,从一个空模型。它包括gydF4y2BaD1CPFgydF4y2Ba。gydF4y2Ba
MD1SWAgydF4y2Ba子模型的gydF4y2BaMD1gydF4y2Ba通过逐步回归发现,从一个部队的模型gydF4y2Ba年龄gydF4y2Ba。提出的理论。它包括gydF4y2Ba年龄gydF4y2Ba和gydF4y2BaD1CPFgydF4y2Ba。gydF4y2Ba
%计算丢失的信息:gydF4y2BaAIC0SW = M0SW.ModelCriterion.AIC;BIC0SW = M0SW.ModelCriterion.BIC;AICD1SW = MD1SW.ModelCriterion.AIC;BICD1SW = MD1SW.ModelCriterion.BIC;gydF4y2Ba%创建模型比较表:gydF4y2BaRMSE = [M0.RMSE; M0SW.RMSE; M0SWAC.RMSE MD1.RMSE; MD1SW.RMSE; MD1SWA.RMSE);AIC = [AIC0; AIC0SW; AIC0SWAC AICD1; AICD1SW; AICD1SWA);BIC = [BIC0; BIC0SW; BIC0SWAC BICD1; BICD1SW; BICD1SWA);模型=表(RMSE、AIC、BICgydF4y2Ba…gydF4y2Ba“RowNames”gydF4y2Ba,{gydF4y2Ba“M0”gydF4y2Ba,gydF4y2Ba“M0SW”gydF4y2Ba,gydF4y2Ba“M0SWAC”gydF4y2Ba,gydF4y2Ba“MD1”gydF4y2Ba,gydF4y2Ba“MD1SW”gydF4y2Ba,gydF4y2Ba“MD1SWA”gydF4y2Ba})gydF4y2Ba
模型=gydF4y2Ba6×3表gydF4y2BaRMSE AIC BIC ________ ____ ____ M0 M0SW 0.076346 -44.159 -38.937 0.080768 -43.321 -40.188 M0SWAC MD1 0.078101 -43.932 -39.754 0.10613 -28.72 -23.741 MD1SW MD1SWA 0.10771 -29.624 -26.637 0.10921 -29.931 -27.939gydF4y2Ba
模型涉及原undifferenced数据得到标志(较低的均方根和ICs)通常高于模型使用差数据,但是伪回归的可能性,导致考虑差数据首先,必须记住。在每个模型类别,结果喜忧参半。原模型与最预测(gydF4y2BaM0gydF4y2Ba,gydF4y2BaMD1gydF4y2Ba最低的rms)范畴,但有降低模型aic(较低gydF4y2BaM0SWACgydF4y2Ba,gydF4y2BaMD1SWgydF4y2Ba,gydF4y2BaMD1SWAgydF4y2BaBICs)和低(gydF4y2BaM0SWgydF4y2Ba,gydF4y2BaM0SWACgydF4y2Ba,gydF4y2BaMD1SWgydF4y2Ba,gydF4y2BaMD1SWAgydF4y2Ba)。这不是不寻常的信息标准建议小模型,或为不同的信息标准不同意(gydF4y2BaM0SWgydF4y2Ba,gydF4y2BaM0SWACgydF4y2Ba)。也有很多原始的和差的组合预测,我们没有包括在我们的分析中。从业者必须决定多少吝啬就够了,更大的上下文中建模的目标。gydF4y2Ba
总结gydF4y2Ba
这个例子比较数量的预测选择技术的一个实际的经济预测模型。许多这样的技术已经开发实验数据收集的情况下会导致大量的潜在的预测因子,和统计技术是唯一实用的排序方法。与更多的有限的数据选择情况,纯粹的统计技术可以导致一系列的潜在模型拟合优度的类似措施。理论考虑,像往常一样,必须在经济模式的选择起到至关重要的作用,而统计数据是用来选择在代理竞争相关的经济因素。gydF4y2Ba
引用gydF4y2Ba
[1]gydF4y2BaBrieman, L。,J. H. Friedman, R. A. Olshen, and C. J. Stone.分类和回归树gydF4y2Ba。博卡拉顿FL:查普曼&大厅/ CRC, 1984。gydF4y2Ba
[2]gydF4y2BaGoutte C。“注意免费午餐和交叉验证。”gydF4y2Ba神经计算gydF4y2Ba。9卷,1997年,页1211 - 1215。gydF4y2Ba
[3]gydF4y2Ba哈特,j . D。“内核回归与时间序列估计错误。”gydF4y2Ba英国皇家统计学会杂志》上gydF4y2Ba。系列B卷。53岁,1991年,页173 - 187。gydF4y2Ba
[4]gydF4y2BaHastie, T。,R. Tibshirani, and J. Friedman.统计学习的元素gydF4y2Ba。纽约:施普林格,2008年。gydF4y2Ba
[5]gydF4y2Ba琼森,j·G。,M. Fridson. "Forecasting Default Rates on High Yield Bonds."《固定收益gydF4y2Ba。1号卷。6日,1996年,页69 - 77。gydF4y2Ba
[6]gydF4y2Ba邵,J。“一个线性模型选择的渐近理论。”gydF4y2BaStatistica中央研究院gydF4y2Ba。7卷,1997年,页221 - 264。gydF4y2Ba
[7]gydF4y2Ba石头,M。“选择的一个渐近等价模型的交叉验证和Akaike的标准。”gydF4y2Ba英国皇家统计学会杂志》上gydF4y2Ba。系列B, 39卷,1977年,页44-47。gydF4y2Ba
[8]gydF4y2BaTibshirani, R。“回归收缩和通过套索选择。”gydF4y2Ba皇家统计学会杂志》上。gydF4y2Ba58卷,1996年,页267 - 288。gydF4y2Ba
你也可以从下面的列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
