时间序列回归III:有影响的观察
这个例子展示了如何在时间序列数据中检测有影响的观测,并适应它们对多元线性回归模型的影响。这是关于时间序列回归的一系列例子中的第三个,在前面的例子中有介绍。
介绍
当考虑影响OLS估计的经验限制时,Belsley等人。[1]建议先处理共线。下一步是寻找有影响力的观察,其存在,个人或团体,对回归结果有可衡量的影响。我们将“有影响力的观察”的基本度量概念与“离群值”的更主观的概念区分开来,“离群值”可能包括任何不遵循预期模式的数据。
我们首先从前面的示例中加载相关数据时间序列回归Ⅱ:共线性和估计方差,并继续分析此处介绍的信用违约模型:
负载Data_TSReg2dt = datetime (dateNums“ConvertFrom”,“datenum”,“格式”,“yyyy”);
有影响的观察
有影响力的观察以两种截然不同的方式产生。首先,它们可能是测量或记录误差的结果。在这种情况下,它们只是坏数据,不利于模型估计。另一方面,它们可能反映了创新过程的真实分布,表现出模型无法解释的异方差、偏度或细峰度。这种观测可能包含异常的样本信息,但这对准确的模型估计是必不可少的。仅看数据很难确定有影响的观察的类型。最好的线索通常可以在产生残差序列的数据模型交互中找到。我们将在示例中进一步研究这些问题时间序列回归VI:残留诊断.
预处理有影响的观测有三个部分:识别、影响评估和适应。在计量经济学环境中,识别和影响评估通常基于回归统计。适应(如果有)通常是在删除数据之间进行选择,这需要对DGP作出假设,或实施适当稳健的估计程序,有可能掩盖异常但可能重要的信息。
时间序列数据与横断面数据的不同之处在于,删除观测值会在样本的时间基础上留下“漏洞”。输入替代值的标准方法,如平滑,违反了CLM的严格外部性假设。如果时间序列数据显示出序列相关性,就像它们在经济环境中经常做的那样,删除观察值将改变估计的自相关性。通过残差分析诊断偏离模型规范的能力受到了损害。因此,建模过程必须在诊断和重新规范之间循环,直到可接受的系数估计产生可接受的残差系列。
删除诊断
这个函数菲特姆计算许多标准回归统计量,用于衡量个别观察的影响。这些都是基于一个接一个的序列行删除联合观察的预测器和响应值。计算每个删除-1数据集的回归统计数据,并与完整数据集的统计数据进行比较。
系数估计值的显著变化
删除后的观察是主要关注的。拟合模型特性Diagnostics.dfBetas通过对个体系数方差的估计来衡量这些差异,以便进行比较:
dfBetas=M0.Diagnostics.dfBetas;数字保持在情节(dt, dfBetas(:, 2:结束),“线宽”图(dt,dfBetas(:,1),“k”,“线宽”,2)保持从图例([0,“拦截”],“位置”,“最好的”)包含(“观察删除”) ylabel (“系数估算中的比例变化”)标题(“{\bf Delete-1系数估计值变化}”)轴心紧网格在

删除对中组件对的影响 在变化的二维散点图矩阵中显示:
图gplotmatrix (dfBetas ,[],[],[],“o”2 []...“变量”, (“常量”predNames0]);标题(“{\bf Delete-1系数估计值变化}”)

有了足够的数据,这些散射趋于近似椭圆形[2].通过键入,可以用相应删除的观测值的名称来标记离点gname (dt)在命令提示符处,然后单击图中的一个点。
或者,库克距离,发现于诊断。CooksDistance拟合模型的属性是这些图的一个常见汇总统计,等高线形成以等高线为中心的椭圆
(即,dfBeta = 0).在多个情节中,远离中心的点有很大的库克距离,表明一个有影响力的观察:
cookD=M0.Diagnostics.CooksDistance;图;绘图(dt,cookD,“米”,“线宽”2) recessionplot;包含(“观察”);ylabel (“库克的距离”);标题({\男朋友做饭”年代距离}); 轴心(“紧”);网格(“开”);

如果 估计的系数向量是 从观测数据中删除,那么库克的距离也就是欧氏距离
和
因此,库克距离可以直接衡量观察结果对拟合响应值的影响。
一个相关的影响度量是利用,它使用法线方程来编写
哪里
是帽子矩阵,仅从预测数据计算。的对角元素
是杠杆值,给出了观察到的资产的组成比例
为相应的估算做出贡献
.杠杆值,可在诊断。利用拟合模型的属性,强调不同的影响源:
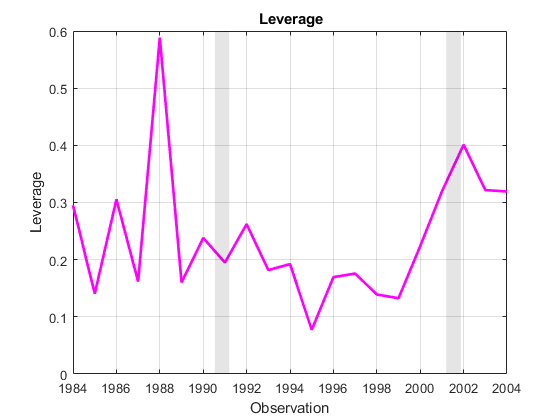
杠杆= M0.Diagnostics.Leverage;图;情节(dt,杠杆,“米”,“线宽”2) recessionplot;包含(“观察”);ylabel (“杠杆”);标题(“{\高炉利用}”); 轴心(“紧”);网格(“开”);
另一个衡量影响力的常用标准是Mahalanobis距离,这只是杠杆的放大版。马氏距离X0可以使用d=马哈尔(X0,X0),在这种情况下,杠杆值为h = d / (T0-1) + (1 / T0).
的其他统计信息可以创建附加的诊断图诊断学拟合模型的属性,或使用plotDiagnostics作用
经济意义
在删除数据之前,应对各种措施所确定的有影响的点赋予某种经济意义。库克距离与总体反应的变化相关,在2001年急剧上升。仅与预测数据相关的杠杆率在1988年就出现了急剧上升。同样值得注意的是,在杠杆率突然增加和一段时期的高违约率之后,预测者BBB1991年后,债券价格向上弯曲,低等级债券的比例开始呈现趋势(见示例中的预测图)时间序列回归I:线性模型.)
我们可以从当时的经济史中找到一些线索。2001年是美国经济衰退的时期(上图第二纵带),部分原因是由于互联网投机泡沫的破裂和商业投资的减少。同年还发生了9 / 11恐怖袭击,给债券市场带来了严重冲击。不确定性,而不是可量化的风险,成为当年剩余时间投资决策的特征。另一方面,20世纪80年代见证了债券市场性质的长期变化。被称为“垃圾债券”的新发行的高收益债券被用来为许多企业结构调整项目融资。这部分债券市场在1989年崩溃。在经历了1990-1991年的经济衰退(上图第一条纵线)和油价冲击之后,高收益债券市场再次开始增长,并趋于成熟。
删除数据的决定最终取决于模型的目的。如果目的主要是解释性的,那么删除准确记录的数据是不合适的。然而,如果目的是预测,那么必须询问删除点是否会创建一个更“典型”的过去的预样例,以及更“典型”的未来的预样例。例如,2001年数据的历史背景可能导致这样的结论:它歪曲了历史模式,不应让它影响预测模型。同样,1980年代的历史可能会得出这样的结论,即债券市场发生了结构性变化,在新制度的预测中,应忽略1991年以前的数据。
作为参考,我们创建了两个修正的数据集:
2001年%删除:d1=(dt~='2001');% 1删除日期d1=dt(d1);Xd1=X0(d1,:);yd1=y0(d1);删除1991年之前的日期:日差= (datesd1 >='1991');%删除很多datesdm = datesd1 (dm);:一棵树= Xd1 (dm);ydm = yd1 (dm);
总结
删除对模型估计的影响总结如下。表格数组提供了一种方便的格式,用于比较模型间的回归统计数据:
Md1 = fitlm (Xd1 yd1);Mdm = fitlm(一棵树,ydm);%模型均方误差:为了表(M0 =。MSE,...Md1。MSE,...Mdm。MSE,...“变化无常”, {“原件”,“Delete01”,“Post90”},...“RowNames”, {“MSE”})
为了=1×3表原始Delete01 Post90 _________ _________ _________ MSE 0.0058287 0.0032071 0.0023762
%系数估计:系数=表(M0.系数.估算,...Md1.1.系数估计,...Mdm.Coefficients.Estimate,...“变化无常”, {“原件”,“Delete01”,“Post90”},...“RowNames”, (“常量”, predNames0])
系数=5×3表原始删除01 Post90 uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu
%系数标准误差:stderr =表(M0.Coefficients.SE,...Md1.SE,...Mdm.SE,...“变化无常”, {“原件”,“Delete01”,“Post90”},...“RowNames”, (“常量”, predNames0])
斯特德=5×3表原Delete01 Post90 _________ _________ _________ Const 0.098565 0.077746 0.086073 AGE 0.0091845 0.0068129 0.013024 BBB 0.0026757 0.0020942 0.0030328 CPF 0.0038077 0.0031273 0.0041749 SPR 0.033996 0.025849 0.027367
MSE随着2001年删除该点而提高,然后又随着1991年之前数据的删除而提高。2001年删除该点也会收紧系数估计的标准误差。然而,删除1991年之前的所有数据会严重减少样本量,以及一些估计的标准误差比使用原始数据时更大。
参考文献
[1]贝尔斯利,检察官,库和r。e。威尔士。回归诊断.纽约:John Wiley & Sons, Inc., 1980。
[2]韦斯伯格,S。应用线性回归新泽西州霍博肯:约翰·威利父子公司,2005年。
你也可以从以下列表中选择一个网站:
