时间序列回归I:线性模型
本例介绍了多元线性回归模型背后的基本假设。它是关于时间序列回归的一系列示例中的第一个,为所有后续示例提供了基础。
多重线性模型
时间序列过程通常用多元线性回归(MLR)表格的模型:
在哪里 是观察到的反应和 包括可观察预测器的同期值的列。的偏回归系数 表示单个预测因子对中值变化的边际贡献 当所有其他预测器都保持不变时。
这个词 是预测值和观测值之间差异的总括 .这些差异是由于流程波动(在 )、测量误差(变更 )和模型的不规范(例如,忽略了预测器或之间的非线性关系 和 ).它们也来自于基础数据生成过程(DGP)的内在随机性,这也是模型试图表示的。人们通常认为 是由不可观测的创新过程具有平稳协方差
对于任意长度的时间间隔 .在进一步的基本假设下 , ,它们的关系,可靠的估计 由普通最小二乘法(OLS)获得。
与其他社会科学一样,经济数据通常是通过被动观察收集的,而不是借助控制实验。理论上相关的预测可能需要被实际可用的替代指标所取代。反过来,经济观察可能具有有限的频率、低变异性和很强的相互依赖性。
这些数据的缺陷导致了OLS估计的可靠性和用于模型说明的标准统计技术方面的一些问题。系数估计可能对数据测量误差敏感,使显著性检验不可靠。多个预测因子的同时变化可能会产生相互作用,而这种相互作用很难区分为单独的影响。观察到的反应变化可能与预测因子的变化相关,但不是由预测因子的变化引起的。
在可用数据的上下文中评估模型假设是规范分析的目标。当一个模型的可靠性变得可疑时,实际的解决方案可能是有限的,但是彻底的分析可以帮助确定任何问题的来源和程度。金宝搏官方网站
这是讨论指定和诊断MLR模型的基本技术的一系列示例中的第一个。该系列还提供了一些通用策略,以解决在处理经济时间序列数据时出现的具体问题。
经典的假设
经典线性模型(CLM)假设允许OLS生成估计 与理想的属性[3].基本假设是,MLR模型和所选择的预测器正确地指定了潜在DGP的线性关系。其他CLM假设包括:
是满秩(预测因子之间没有共线性)。
是不相关的 对所有 (预测因子的严格外显性)。
不是自相关的( 是对角)。
是同构的(图中的对角线条目) 都是 ).
假设 为估计误差。的偏见估计量的 和均方误差(MSE) .MSE是估计量方差和偏差平方的和,因此它整洁地总结了估计量不准确的两个重要来源。它不应与回归MSE相混淆,MSE涉及模型残差,它是依赖于样本的。
所有的估计器在最小化MSE的能力上都是有限的,MSE永远不能小于Cramer-Rao下界[1].这个界是通过极大似然估计(MLE)渐近地实现的(即随着样本容量的增大)。然而,在有限样本中,特别是在经济学中遇到的相对较小的样本中,其他估计量可能在相对效率,即所达到的MSE。
在CLM假设下,高斯-马尔可夫定理表示OLS估计量 是蓝色:
B美国东部时间(最小方差)
L线性(数据的线性函数)
Unbiased ( )
E中系数的刺激器 .
在线性估计中,最佳加总为最小均方误差。线性很重要,因为线性向量空间的理论可以应用于估计量的分析(例如,参见[5]).
如果创新 通常是分布式的, 也是正态分布。在这种情况下,是可靠的 和 可以对系数估计进行检验,以评估预测器的显著性,并可以使用标准公式构造置信区间来描述估计器的方差。正常也允许 为了达到Cramér-Rao下限(它变为非常高效。),估计值与最大似然估计值相同。
不论 ,中心极限定理保证 将在大样本中近似正态分布,因此与模型规范相关的标准推理技术渐近有效。然而,如前所述,经济数据的样本通常相对较小,不能依靠中心极限定理得出正态分布的估计。
静态计量经济模型代表了只对当前事件作出反应的系统。静态MLR模型假设构成列的预测器 与回应是同步的吗 .对于这些模型来说,CLM假设的评估相对简单。
相比之下动态模型使用滞后预测来整合随时间变化的反馈。CLM假设中没有明确排除具有滞后或超前的预测因子。事实上,落后外生预测 ,不受创新的影响 ,本身并不影响OLS估计的高斯-马尔可夫最优性。如果预测因素包括近似滞后 , , , ...,however, as economic models often do, then predictor interdependencies are likely to be introduced, violating the CLM assumption of no collinearity, and producing associated problems for OLS estimation. This issue is discussed in the example时间序列回归II:共线性和估计量方差.
当预测内生,由响应的滞后值决定 (自回归模型),通过预测因子和创新之间的递归交互,违反了严格外部性的CLM假设。在这种情况下,会出现其他的、通常更为严重的OLS估计问题。这个问题在示例中进行了讨论时间序列回归VIII:滞后变量和估计偏差.
违反CLM假设 (nonspherical创新)在例子中进行了讨论时间序列回归VI:残留诊断.
违反CLM假设并不一定会使OLS估计结果无效。然而,重要的是要记住,个别侵权行为的影响或多或少会产生后果,这取决于它们是否与其他侵权行为相结合。规范分析试图识别所有违规行为,评估对模型估计的影响,并在建模目标的背景下提出可能的补救措施。
时间序列数据
考虑一个信用违约率的简单MLR模型。该文件Data_CreditDefaults.mat包含1984年至2004年投资级公司债券违约的历史数据,以及四个潜在预测因素的数据:
负载Data_CreditDefaults
X0 =数据(:,1:4);初始预测器集(矩阵)X0Tbl = DataTable (:, 1:4);%初始预测器集(表格数组)predNames0 =系列(1:4);%初始预测器集名称T0 =大小(X0, 1);%样本量y0 =数据(:,5);%响应数据respName0=系列{5};%响应数据名称
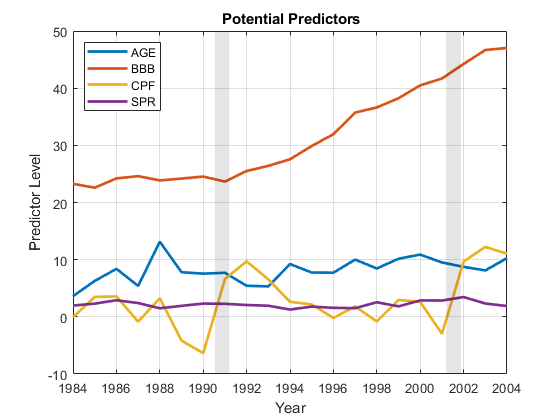
潜在的预测者,测量了一年T,有:
年龄投资级债券发行人在3年前首次获得评级的百分比。这些相对较新的发行人在首次发行的资本支出后(通常是在大约3年后)具有较高的违约经验概率。
BBB标准普尔信用评级为最低投资级BBB的投资级债券发行人的百分比。这个百分比代表了另一个风险因素。
论坛根据通胀因素调整后的公司利润变化预测。该预测是衡量整体经济健康状况的指标,被视为更大商业周期的指标。
SPR公司债券收益率与可比政府债券收益率之差。价差是衡量当前问题风险的另一个指标。
这是多年来的反应T+1,是:
IGD投资级公司债券违约率
如中所述[2]和[4],预测器是从其他序列构造的代理。建模目标是生成一个动态预测模型,响应提前一年(相当于预测滞后一年)。
我们首先检查数据,将日期转换为datetime向量,以便实用程序函数recessionplot可以覆盖显示商业周期相关下跌的波段:
将日期转换为日期时间矢量:dt = datetime (string(日期),“格式”,“yyyy”);% Plot潜在预测因子:图;情节(dt, X0,“线宽”2) recessionplot;包含(“年”) ylabel (的预测水平)传说(predNames0“位置”,“西北”)标题(“{\ bf潜力预测}”)轴心(“紧”)网格(“开”)
%绘图响应:图;持有(“开”);情节(dt, y0,“k”,“线宽”2);情节(dt, y0-detrend (y0),“m——”) (“关闭”);recessionplot;包含(“年”) ylabel (“响应级别”)传说(respName0“线性趋势”,“位置”,“西北”)标题(“{}\高炉反应”)轴心(“紧”);网格(“开”);
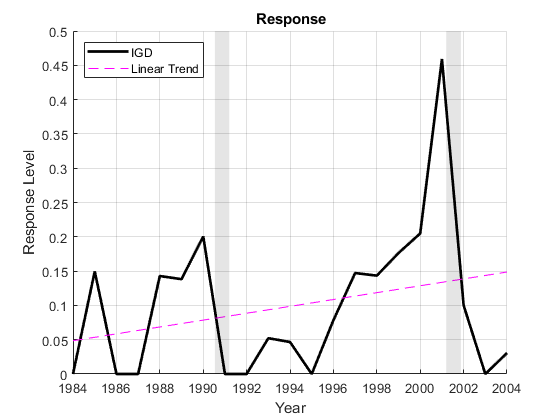
我们看到了BBB与其他预测指标的规模略有不同,并且随着时间的推移呈趋势。因为响应数据是年度的T+ 1,违约率的峰值实际上是在衰退之后出现的T= 2001。
模型分析
预测器和响应数据现在可以组装成一个MLR模型,OLS估计
使用MATLAB反斜杠(\)接线员:
将截距添加到模型:X0I=[一(T0,1),X0];%的矩阵X0ITbl=[表(一)(T0,1),“VariableNames”, {“常量”}), X0Tbl];%的表估计= X0I \ y0
估计=5×1-0.2274 0.0168 0.0043 -0.0149 0.0455
另外,也可以使用LinearModel对象函数,它提供诊断信息和许多方便的分析选项菲特姆用来估计
从数据。默认情况下,它会添加一个拦截。以表格数组的形式传入数据,其中包含变量名和最后一列的响应值,返回一个带有标准诊断统计数据的拟合模型:
M0=fitlm(数据表)
M0 =线性回归模型:IGD ~ 1 + AGE + BBB + CPF + SPREstimate SE tStat pValue _________ _________ _______ _________ (Intercept) -0.22741 0.098565 -2.3072 0.034747 AGE 0.016781 0.0091845 1.8271 0.086402 BBB 0.0042728 0.0026757 1.5969 0.12985 CPF -0.014888 0.0038077 -3.91 0.0012473 SPR 0.045488 0.033996 1.338 0.1996观测数:21,误差自由度:16均方根误差:0.0763 R-squared: 0.621, Adjusted R-squared: 0.526 F-statistic vs. constant model: 6.56, p-value = 0.00253
关于这个模型的可靠性还有许多问题要问。预测器是否是所有潜在预测器的一个很好的子集?系数估计准确吗?预测因素和反应之间的关系真的是线性的吗?模型预测可靠吗?简而言之,模型是否被很好地指定,OLS是否很好地将其与数据相吻合?
另一个LinearModel目标函数,方差分析,以表格数组的形式返回额外的拟合统计信息,这对于在更扩展的规范分析中比较嵌套模型很有用:
ANOVATable =方差分析(M0)
ANOVATable =5×5表SumSq DF MeanSq F pValue ________ __ _________ ______ _________ AGE 0.019457 1 0.019457 3.3382 0.086402 BBB 0.014863 1 0.014863 2.55 0.12985 CPF 0.089108 1 0.089108 15.288 0.0012473 SPR 0.010435 1 0.010435 1.7903 0.1996 Error 0.09326 16 0.0058287
总结
模型说明是计量经济分析的基本任务之一。基本工具是回归,从广义上讲是参数估计,用于评估一系列候选模型。然而,任何形式的回归都依赖于某些假设和某些技术,而这些假设和技术在实践中几乎从未得到充分证明lt、信息丰富、可靠的回归结果很少通过使用默认设置的单一标准程序获得。相反,它们需要经过深思熟虑的规范、分析和再规范周期,并根据实践经验、相关理论和对许多情况的认识,在这些情况下,考虑不周的统计事实证据可能混淆合理的结论。
探索性数据分析是此类分析的关键组成部分。实证计量经济学的基础是,好的模型只有通过与好的数据的相互作用才能产生。如果数据有限(这在计量经济学中经常发生),分析必须承认由此产生的歧义,并帮助确定一系列可供考虑的替代模型。装配最可靠的型号没有标准的程序。好的模型从数据中产生,并能适应新的信息。
本系列中的后续示例考虑了线性回归模型,这些模型由一小组潜在预测器构建,并校准为一小组数据。然而,所考虑的技术和MATLAB工具箱函数是典型规范分析的代表。更重要的是,从最初的数据分析,到试探性的模型建立和完善,最后到在实际舞台上的预测性能测试的工作流程也是相当典型的。在大多数经验主义的努力中,过程是关键。
参考文献
[1]克莱默,H。数理统计方法新泽西州普林斯顿:普林斯顿大学出版社,1946年。
[2]J. Helwege和P. Kleiman。《理解高收益债券的总违约率》纽约联邦储备银行当前的经济和金融问题. 1996年第2卷第6期,第1-6页。
[3]肯尼迪,P。计量经济学指南.第6版。纽约:约翰·威利父子,2008。
[4]G.吕弗勒和P. N.波许。基于Excel和VBA的信用风险建模.英格兰西苏塞克斯:威利金融,2007。
[5]斯特朗,G。线性代数及其应用第四版,加利福尼亚州太平洋格罗夫:布鲁克斯·科尔,2005年。
你也可以从以下列表中选择一个网站:
