partitionDetections
语法
描述
一个分区一组检测被定义为一个部门检测为非空的互斥检测细胞。使用多个距离阈值,您可以使用该函数分离检测到不同的检测细胞和得到所有可能的分区使用distance-partitioning或density-based空间聚类的应用程序与噪音(DBSCAN)。此外,你可以选择的距离度量,通过指定的距离或欧氏距离“距离”名称-值对的论点。
距离分区
距离分区是默认的分区算法partitionDetections。在距离分区,检测集群由探测的距离至少有一个集群中的其他检测小于阈值的距离。换句话说,两个检测属于同一检测集群如果他们距离小于阈值的距离。要使用distance-partitioning,您可以指定“算法”名称-值参数为“Distance-Partitioning”或者干脆不指定“算法”论点。
分区= partitionDetections (检测,allThresholds)
(此外返回索引向量分区,indexDP)= partitionDetections (检测,allThresholds)indexDP代表所有阈值之间的对应关系和由此产生的分区。
DBSCAN分区
使用DBSCAN分区,指定“算法”参数为“DBSCAN”。
分区= partitionDetections (检测,ε,minNumPoints、“算法”、“DBSCAN”)ε集群和最小数量的分minNumPoints的DBSCAN算法。
(此外返回索引向量分区,indexDB)= partitionDetections (检测,ε,minNumPoints、“算法”、“DBSCAN”)indexDB代表阈值之间的对应关系ε以及由此产生的分区。
指定的距离度量
使用“距离”名称-值参数,您可以指定使用的距离度量分区。
___= partitionDetections (___“距离”,另外指定的距离度量距离)“Mahalanobis”或“欧几里得”。使用这种语法的输入或输出参数在以前的语法。
例子
从对象生成分区检测使用距离分区
生成二维检测使用objectDetection。
rng (2018);%的可重复的结果检测=细胞(10,1);为i = 1:元素个数(检测)id =兰迪([1 5]);检测{我}= objectDetection (0, [id, id] + 0.1 * randn (2,1));检测我{}。米easurementNoise = 0.01*eye(2);结束
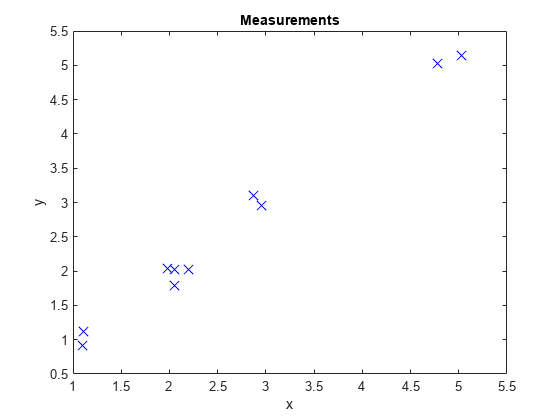
提取和显示生成的位置测量。
d =[检测{}):;测量= [d.Measurement];图()图(测量(1:),测量(2:)“x”,“MarkerSize”10“MarkerEdgeColor”,“b”)标题(“测量”)包含(“x”)ylabel (“y”)
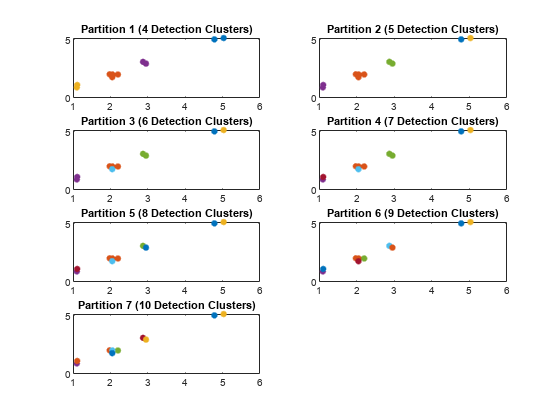
从检测生成分区使用距离分区和分区的数量。
分区= partitionDetections(检测);numPartitions =大小(分区,2);
可视化的分区。每一种颜色代表一个检测集群。
图()为i = 1: numPartitions numCells = max(分区(:,i));次要情节(4、装天花板(numPartitions / 4) i);为k = 1: numCells id =分区(:,i) = = k;情节(测量(id),测量(id),“。”,“MarkerSize”15);持有在;结束标题([“分区”num2str(我),“(”num2str (k),“检测集群)”]);结束
从对象生成分区使用DBSCAN检测
生成二维检测使用objectDetection。
rng (2018);%的可重复的结果检测=细胞(10,1);为i = 1:元素个数(检测)id =兰迪([1 5]);检测{我}= objectDetection (0, [id, id] + 0.1 * randn (2,1));检测我{}。米easurementNoise = 0.01*eye(2);结束
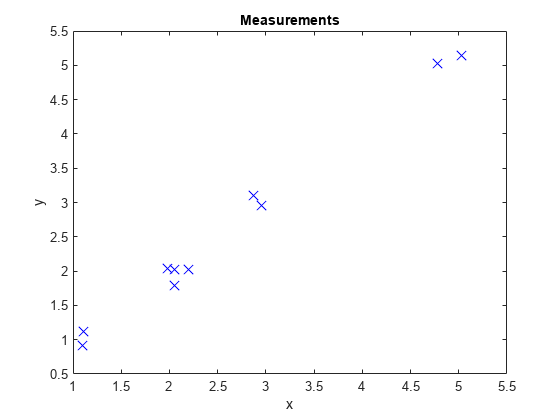
提取和显示生成的位置测量。
d =[检测{}):;测量= [d.Measurement];图()图(测量(1:),测量(2:)“x”,“MarkerSize”10“MarkerEdgeColor”,“b”)标题(“测量”)包含(“x”)ylabel (“y”)
从检测生成分区使用DBSCAN和计算分区的数量。
(分区,索引)= partitionDetections(检测,(1.6;2),2,“算法”,“DBSCAN”);numPartitions =大小(分区,2);
可视化的分区。每一种颜色代表一个检测集群。
图()为i = 1: numPartitions numCells = max(分区(:,i));次要情节(装天花板(numPartitions / 2), i);为k = 1: numCells id =分区(:,i) = = k;情节(测量(id),测量(id),“。”,“MarkerSize”15);持有在;结束标题([“分区”num2str(我),“(”num2str (k),“检测集群)”]);结束
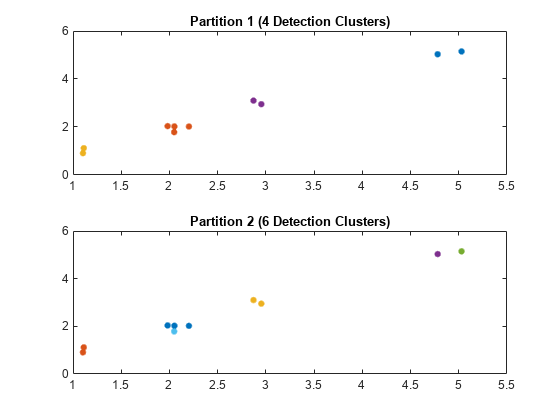
索引值的第一个分区对应一个ε值2第二个分区对应一个ε值1.6。
指数
指数=1 x2 uint32行向量2 1
输入参数
输出参数
引用
[1]Granstrom,卡尔,基督教Lundquist和Omut Orguner。“扩展目标跟踪使用高斯混合博士过滤器。”IEEE航空航天和电子系统48岁的没有。4(2012年10月):3268 - 86。https://doi.org/10.1109/TAES.2012.6324703。
[2]酯,马丁汉斯-彼得•Kriegel, Jorg桑德,徐小韦。“Density-Based发现算法在大型空间数据库集群的噪音。”第二届国际研讨会论文集知识发现和数据挖掘,226 - 31所示。KDD ' 96。俄勒冈州的波特兰:AAAI出版社,1996年。
扩展功能
版本历史
介绍了R2019a