数值等测试
通过使用GPU加速和循环(PIL)模拟,从组件生成的模型组件和生产代码之间的数字等效。
使用GPU加速模拟,您可以在开发计算机上测试源代码。使用PIL模拟,您可以通过在实际目标硬件上运行目标代码来测试打算部署到目标硬件上的已编译的目标代码。要确定模型组件和生成的代码在数值上是否等效,请将GPU加速和PIL结果与正常模式结果进行比较。
PIL的目标连接配置
在运行PIL模拟之前,必须配置目标连接。目标连接配置使PIL模拟能够:
构建目标应用程序。
下载、启动和停止目标上的应用程序。
金宝app支持Simulink之间的通信金宝app®和目标。
以产生用于硬件平台,例如NVIDIA的目标的连接配置®驱动和Jetson,安装MATLAB®编码器™金宝app支持包的NVIDIA Jetson®和NVIDIA DRIVE™平台。
笔记
开始在R2021a中,GPU编码器™支持包的金宝appNVIDIA GPU被命名为Matlab编码器金宝app支持NVIDIA Jetson和Nvidia Drive Platforms的支持包。要在R2021A中使用此金宝app支持包,您必须拥有Matlab编码器产品。
目标板要求
NVIDIA驱动器或杰特森嵌入式平台。
以太网交叉电缆连接目标板和主机PC(如果您无法将目标板连接到本地网络)。
nvidia cuda®工具包安装在电路板上。
对目标的编译器和库环境变量。有关编译器,库的受支持版本,以及它们的设置信息金宝app,请参阅安装和设置NVIDIA板的先决条件(MATLAB编码器支持包为金宝appNVIDIA Jetson和NVIDIA Drive Platforms)。
创建实时硬件连接对象
支持包软金宝app件使用TCP / IP上的SSH连接在构建和运行驱动器或Jetson平台上运行生成的CUDA代码时执行命令。将目标平台连接到与主机相同的网络,或者使用以太网交叉电缆将电路板直接连接到主机。有关如何设置和配置电路板,请参阅NVIDIA文档。
要与NVIDIA硬件进行通信,请通过使用“创建实时硬件连接对象”杰森(MATLAB编码器支持包为金宝appNVIDIA Jetson和NVIDIA Drive Platforms)或者驾驶(MATLAB编码器支持包为金宝appNVIDIA Jetson和NVIDIA Drive Platforms)功能。要使用该功能创建实时硬件连接对象,请提供目标板的主机名或IP地址,用户名和密码。例如,要为Jetson硬件创建实时对象:
hwobj =杰森(“192.168.1.15”、“ubuntu”、“ubuntu”);
该软件进行了硬件的检查,编译工具,库,IO服务器的安装,并收集关于目标外围信息。这些信息将显示在命令窗口。
检查CUDA在目标上的可用性…在目标系统路径中检查NVCC…检查CUDNN库在目标上的可用性…在Target上检查TensorRT库的可用性…现在已经完成了对先决条件库的检查。获取硬件细节……获取硬件细节现在已经完成。显示详细信息。主板名称:NVIDIA Jetson TX2 CUDA Version: 9.0 cuDNN Version: 7.0 TensorRT Version: 3.0可用摄像头:UVC Camera (046d:0809)可用gpu: NVIDIA Tegra X2
或者,为DRIVE硬件创建活动对象:
hwobj = drive('92 .168.1.16','nvidia','nvidia');
笔记
如果存在连接失败,则在MATLAB命令窗口上报告诊断错误消息。如果连接失败,则最可能的原因是IP地址或主机名不正确。
例如:Mandelbrot集合
描述
Mandelbrot Set是由值组成的复平面中的区域Z.0.由此等式定义的轨迹仍然有界限k→∞。
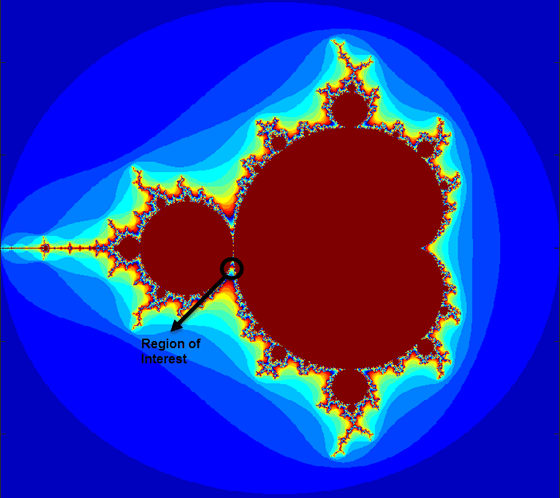
Mandelbrot集的整体几何结构如图所示。这种观点不具有分辨率只显示外边缘的细节丰富的结构设定的边界。在提高放大倍数,Mandelbrot集展示一个精心制作的边界,揭示逐渐变细的递归的细节。
算法
对于本教程,选择一组限制,指定在主心脏线和之间的谷中Mandelbrot集合的高度放大部分P / Q.灯泡其左。1000由-1000电网的实部(X)和虚部(y)是在这两个界限之间创建的。然后在每个网格位置迭代Mandelbrot算法。迭代次数为500时,图像将呈现为全分辨率。
最大= 500;gridsize = 1000;XLIM = [-0.748766713922161,-0.7487667077771757];ylim = [0.12364084894862,0.123640851045266];
本教程使用在CPU上运行的标准MATLAB命令来实现Mandelbrot集。这个计算被向量化,这样每个位置都是同时更新的。
GPU加速或PIL仿真与顶级模特
通过运行顶级模型PIL模拟试验生成的模型代码。通过这种方法:
您将测试从顶部模型生成的代码,该模型使用独立的代码接口。
您可以配置模型以加载测试向量或来自MATLAB工作空间的刺激输入。
您可以轻松切换正常,GPU加速和PIL模拟模式之间的顶级车型。
创建Mandelbrot Top Model
创建Simulin金宝appk模型并插入一个MATLAB函数街区来自用户定义函数图书馆。
双击MATLAB函数堵塞。将显示默认函数签名MATLAB函数块编辑器。
定义一个调用的函数
mandelbrot_count,它实现了Mandelbrot算法。函数头文件声明最大那xGrid,yGrid作为一个论点mandelbrot_count函数,数数作为返回值。函数count = mandelbrot_count(maxIrtations,xgrid,ygrid)曼德布洛特百分比计算z0 = xgrid + 1i * ygrid;count = =(大小(z0));将计算映射到GPUcoder.gpu.kernelfun;z = z0;为n = 0:maxIterations z = z。* z + z0;内部= abs(z)<= 2;count =内部计数+;结束数=日志(数);
打开块参数MATLAB函数堵塞。在这一点代码生成选项卡上,选择
可重用的功能为功能包装参数。如果功能包装参数设置为任何其他值,CUDA内核可能不会生成。
如该图所示连接这些块。保存模型
mandelbrot_top.slx。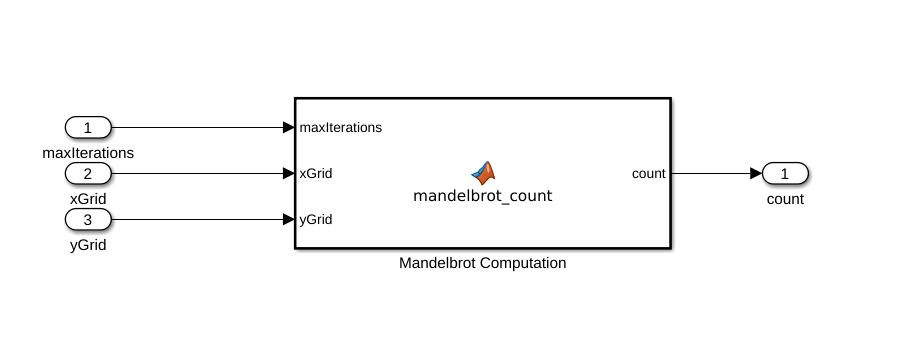

配置GPU加速的型号
要专注于数值等效测试,请关闭:
模型覆盖
代码覆盖范围
执行时间分析
模型='mandelbrot_top';close_system(型号,0);Open_System(Model)Set_Param(GCS,'recordcoverage'那“关闭”);coverageAckettings = get_param(型号,“CodeCoverageSettings”);coverageSettings。CoverageTool =“没有”;set_param(型号,“CodeCoverageSettings”, coverageSettings);set_param(型号,“CodeExecutionProfiling”那“关闭”);
配置输入的刺激数据。下面几行代码生成一个1000 × 1000的实际部件网格(X)和虚部(y)在规定的限制之间xlim和ylim。
gridsize = 1000;XLIM = [-0.748766713922161,-0.7487667077771757];ylim = [0.12364084894862,0.123640851045266];x = Linspace(XLIM(1),XLIM(2),网格化);y = linspace(ylim(1),ylim(2),gridsize);[xg,yg] = meshgrid(x,y);maxIrtations = timeeries(500,0);XGrid = TimeSeries(XG,0);ygrid = timeeries(yg,0);
配置模型中的日志记录选项。
set_param(型号,“LoadExternalInput”那“上”);set_param(型号,“ExternalInput”那'MaxIlerations,Xgrid,Ygrid');set_param(型号,'SignalLogging'那“上”);set_param(型号,“SignalLoggingName”那“logsOut”);set_param(型号,“SaveOutput”那“上”)
运行正常和PIL模拟
运行正常模式模拟。
set_param(型号,'simulationmode'那'普通的') set_param(模型,“GPUAcceleration”那“上”);sim_output = sim(型号,10);count_normal = sim_output.yout {1} .values.data(:,:1);
运行一个顶级模型PIL模拟。
set_param(型号,'simulationmode'那“Processor-in-the-Loop(公益诉讼))sim_output = sim(型号,10);count_pil = sim_output.yout {1} .values.data(:,:,1);
###目标设备没有本机的通信支持。金宝app检查连接配置注册... ###启动建立过程为:mandelbrot_top ###生成代码和工件为“特定模型”的文件夹结构###生成的代码到生成文件夹:/ MathWorks的/示例/ sil_pil / mandelbrot_top_ert_rtw ###生成的代码为“mandelbrot_top”是最新的,因为没有发现结构,参数或代码替换库的变化。###评估PostCodeGenCommand模型中指定的###使用工具链:为NVCC NVIDIA嵌入式处理器###“/mathworks/examples/sil_pil/mandelbrot_top_ert_rtw/mandelbrot_top.mk”是最新的###大厦“mandelbrot_top”:化妆-f mandelbrot_top.mk buildobj ###的构建过程的顺利完成为:mandelbrot_top制作摘要内置顶级车型的目标:示范行动重建原因=============================================================================mandelbrot_top Code compiled Compilation artifacts were out of date. 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 22.94s ### Target device has no native communication support. Checking connectivity configuration registrations... ### Connectivity configuration for component "mandelbrot_top": NVIDIA Jetson ### PIL execution is using Port 17725. PIL execution is using 30 Sec(s) for receive time-out. ### Preparing to start PIL simulation ... ### Using toolchain: NVCC for NVIDIA Embedded Processors ### '/mathworks/examples/sil_pil/mandelbrot_top_ert_rtw/pil/mandelbrot_top.mk' is up to date ### Building 'mandelbrot_top': make -f mandelbrot_top.mk all ### Starting application: 'mandelbrot_top_ert_rtw/pil/mandelbrot_top.elf' ### Launching application mandelbrot_top.elf... PIL execution terminated on target.
除非存在此模型的最新代码,否则生成并编译新代码。生成的代码作为计算机上的单独进程运行。
绘制和比较正常和PIL模拟的结果。观察结果是否匹配。
数字();子图(1,2,1)ImageC(x,y,count_normal);Colormap ([jet();flipud(jet());0 0 0]);标题(“Mandelbrot集正态模拟”);轴从;Subplot (1,2,2) imagesc(x, y, count_pil);Colormap ([jet();flipud(jet());0 0 0]);标题('mandelbrot set pil');轴从;

清理。
close_system(型号,0);如果ishandle(图一),关闭(图一),结束清除图。1simResults = {“count_sil”那'count_normal'那'模型'};保存([模型'_结果'],SimResults {:});清除(SimResults {:},“simResults”)
限制
使用GPU编码器,不支持用于循环(PIL)仿真的金宝app遥控器日志记录。
也可以看看
职能
bdClose.(金宝app模型)|close_system(金宝app模型)|get_param.(金宝app模型)|load_system(金宝app模型)|Open_System.(金宝app模型)|save_system(金宝app模型)|set_param(金宝app模型)|sim卡(金宝app模型)|slbuild(金宝app模型)
相关话题
你也可以从以下列表中选择一个网站:
