培训自动停车剂的PPO代理gydF4y2Ba
这个例子演示了一个用于自动搜索和停车任务的混合控制器的设计。该混合控制器使用模型预测控制(MPC)在停车场中遵循参考路径,并使用训练过的强化学习(RL)代理执行停车机动。gydF4y2Ba
本示例中的自动停车算法执行一系列机动,同时感应和避免狭小空间中的障碍物。它在自适应MPC控制器和RL代理之间切换以完成停车操纵。MPC控制器沿着参考路径以恒定速度移动车辆,而算法搜索空停车位。当发现点时,RL代理接管并执行备用停车的操作。在控制器上可获得包括空斑和停放车辆的地点的环境(停车场)的先验知识。gydF4y2Ba
停车场gydF4y2Ba
停车场由此表示gydF4y2Ba停车场gydF4y2Ba类,它存储关于ego车辆、空停车位和静态障碍物(停放的汽车)的信息。每个停车位都有一个独特的索引号和一个指示灯,绿色(空闲)或红色(占用)。停放的车辆用黑色表示。gydF4y2Ba
创建A.gydF4y2Ba停车场gydF4y2Ba物体在位置7处有一个自由点。gydF4y2Ba
freeSpotIdx = 7;地图=停车场(freeSpotIdx);gydF4y2Ba
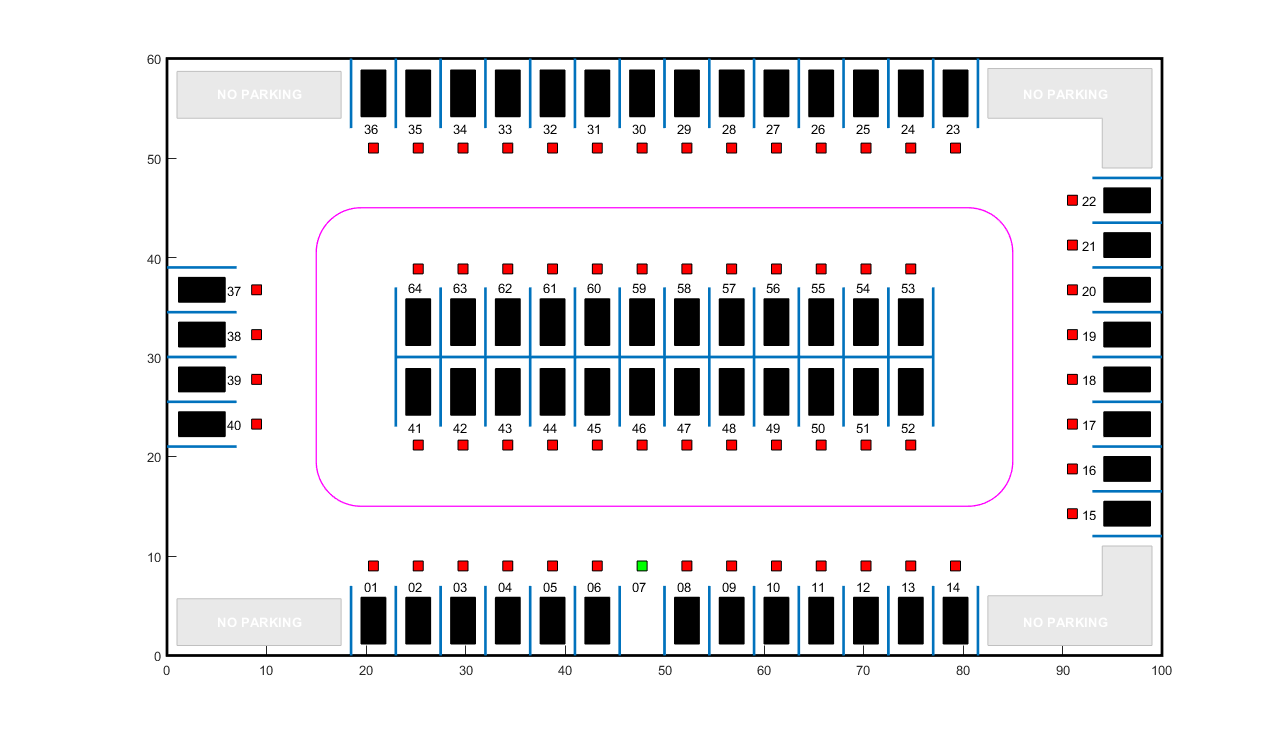
指定初始姿势gydF4y2Ba 为自我车辆。当车辆导航停车场时,基于第一个可用的自由点确定目标姿势。gydF4y2Ba
egoInitialpose = [20,15,0];gydF4y2Ba
使用该计算车辆的目标姿势gydF4y2BacreateTargetpose.gydF4y2Ba功能。目标姿势对应于位置gydF4y2BafreeSpotIdxgydF4y2Ba.gydF4y2Ba
Egotargetospose = CreateTargetPosit(地图,FreeSpotidx)gydF4y2Ba
egoTargetPose =gydF4y2Ba1×3gydF4y2Ba47.7500 4.9000 -1.5708gydF4y2Ba
传感器模块gydF4y2Ba
停车算法使用相机和LIDAR传感器来收集来自环境的信息。gydF4y2Ba
相机gydF4y2Ba
安装在自我车辆上的摄像机的视野由下图中的区域中的区域表示。相机有一个视野gydF4y2Ba 有界限gydF4y2Ba 和最大测量深度gydF4y2Ba 10米。gydF4y2Ba
当EGO车辆向前移动时,相机模块会发现落在视野中的停车位,并确定点是否自由或占用。为简单起见,使用点位置和当前车辆姿势之间的几何关系来实现该动作。停车位在相机范围内gydF4y2Ba 和gydF4y2Ba ,在哪里gydF4y2Ba 到停车位的距离是多少gydF4y2Ba 是停车位的角度。gydF4y2Ba
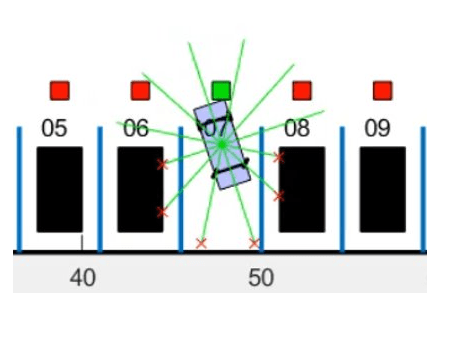
激光雷达gydF4y2Ba
钢筋学习代理使用LIDAR传感器读数来确定自助车辆到环境中的其他车辆的附近。该示例中的LIDAR传感器也使用几何关系进行建模。沿着12线段测量LiDAR距离,从自助式车辆的中心径向出现。当激光雷达线与障碍物相交时,它返回障碍物与车辆的距离。沿任何线段的最大可测量的LIDAR距离为6米。gydF4y2Ba
自动泊车代客模式gydF4y2Ba
包括控制器,自助式车辆,传感器和停车场的停车剂代客模型是在Simulink®中实现的。金宝appgydF4y2Ba
加载自动停车代客参数。gydF4y2Ba
autoparkingvaletparams.gydF4y2Ba
打开Simulin金宝appk模型。gydF4y2Ba
mdl =gydF4y2Ba'rlautoparkingvalet'gydF4y2Ba;Open_System(MDL)gydF4y2Ba
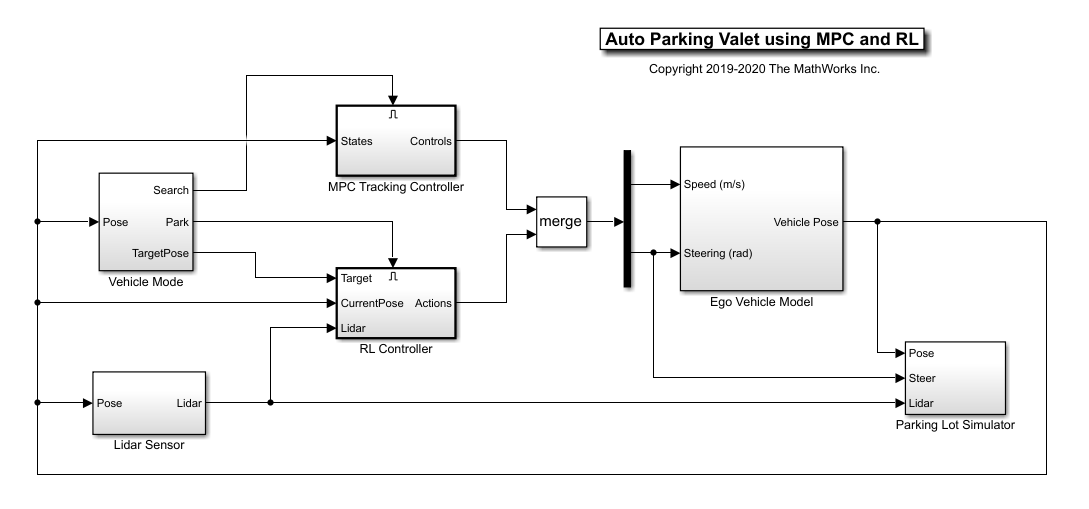
该模型中的自我车辆动态由具有两个输入的单轨自行车模型表示:车速gydF4y2Ba (m / s)和转向角gydF4y2Ba (弧度)。MPC和RL控制器被放置在启用的子系统块内,该信号由表示车辆是否必须搜索空点或执行停车操纵的信号激活。使能信号由车辆模式子系统内的相机算法确定。最初,车辆是gydF4y2Ba搜索gydF4y2Ba模式和MPC控制器跟踪参考路径。找到一个免费点,gydF4y2Ba公园gydF4y2Bamode被激活时,RL agent执行停车动作。gydF4y2Ba
自适应模型预测控制器gydF4y2Ba
创建用于使用该参考轨迹跟踪的Adaptive MPC控制器对象gydF4y2Bacreatempcforparking.gydF4y2Ba脚本。有关Adaptive MPC的更多信息,请参阅gydF4y2Ba自适应政策委员会gydF4y2Ba(模型预测控制工具箱)gydF4y2Ba.gydF4y2Ba
creatempcforparking.gydF4y2Ba
强化学习环境gydF4y2Ba
用于训练RL代理的环境是在下图中以红色阴影的区域。由于停车场的对称性,在将适当的坐标转换应用于观察后,该地区内的训练足以适应其他地区。与整个停车场的训练相比,使用这种较小的训练区域显着减少了培训时间。gydF4y2Ba
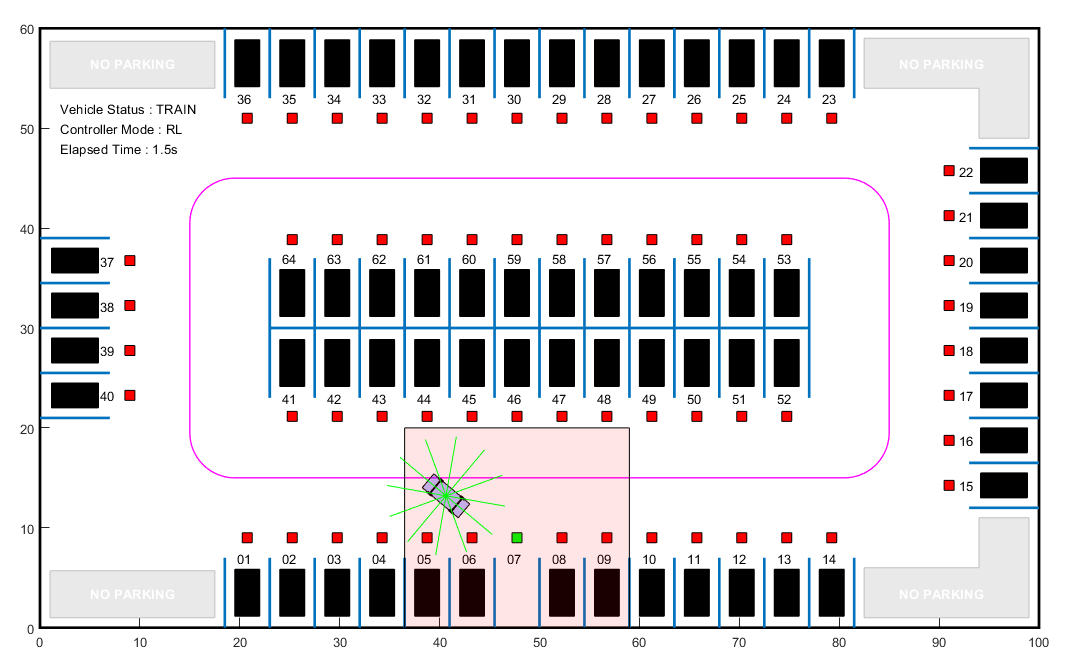
对于这个环境:gydF4y2Ba
训练区是22.5米×20米的空间,其水平中心处的目标斑点。gydF4y2Ba
观察结果是位置误差gydF4y2Ba 和gydF4y2Ba 自我车辆相对于目标姿势,正弦和余弦的真实标题角度gydF4y2Ba 和激光雷达传感器读数。gydF4y2Ba
车辆在停车时的速度是恒定的2米/秒。gydF4y2Ba
动作信号是离散的转向角度,范围在+/- 45度之间的步骤,15度。gydF4y2Ba
如果相对于目标位姿的误差在+/- 0.75米(位置)和+/-10度(方向)的指定公差范围内,则认为车辆已停好。gydF4y2Ba
如果自负的车辆超出了训练区域的界限,与障碍物相撞,或者成功地停车,这一集就结束了。gydF4y2Ba
奖励gydF4y2Ba 随时提供gydF4y2BatgydF4y2Ba是:gydF4y2Ba
在这里,gydF4y2Ba ,gydF4y2Ba ,和gydF4y2Ba 自我飞行器的位置和航向角与目标姿态有偏差吗gydF4y2Ba 是转向角度。gydF4y2Ba (0或1)表示车辆是否已停放和gydF4y2Ba (0或1)表示车辆是否在同一时间与障碍物相撞gydF4y2Ba .gydF4y2Ba
车辆姿态的坐标变换gydF4y2Ba 不同停车位位置的观察如下:gydF4y2Ba
1 - 14:不转换gydF4y2Ba
第15 - 22:gydF4y2Ba
23-36:gydF4y2Ba
37-40:gydF4y2Ba
41-52:gydF4y2Ba
53 - 64:gydF4y2Ba
为环境创建观察和动作规范。gydF4y2Ba
numObservations = 16;observationInfo = rlNumericSpec([numObservations 1]); / /注意observationInfo。Name =gydF4y2Ba'观察'gydF4y2Ba;steerMax =π/ 4;disstetesteerangles = -steerMax: deg2rad(15): steerMax;actionInfo = rlFiniteSetSpec (num2cell (discreteSteerAngles));actionInfo。Name =gydF4y2Ba“行动”gydF4y2Ba;数量= numel(ActionInfo.Elements);gydF4y2Ba
创建Simulink环金宝app境界面,指定RL代理程序块的路径。gydF4y2Ba
blk = [mdlgydF4y2Ba'/ RL控制器/ RL代理'gydF4y2Ba];env = rl金宝appsimulinkenv(mdl,blk,观察indfo,afticeinfo);gydF4y2Ba
指定培训的重置功能。当gydF4y2Baautoparkingvaletresetfcn.gydF4y2Ba功能将自我车辆的初始姿势重置为每一集开始时的随机值。gydF4y2Ba
env。ResetFcn = @autoParkingValetResetFcn;gydF4y2Ba
有关创建Simulink环境的更多信息,请参阅金宝appgydF4y2Barl金宝appSimulinkEnvgydF4y2Ba.gydF4y2Ba
创建代理gydF4y2Ba
本例中的RL代理是具有离散动作空间的近端策略优化(PPO)代理。PPO代理依靠演员和评论家代表来学习最优策略。agent为演员和评论家维护基于深度神经网络的函数近似器。要了解有关PPO代理的更多信息,请参见gydF4y2Ba近端政策优化代理gydF4y2Ba.gydF4y2Ba
设置随机种子发生器以进行再现性。gydF4y2Ba
RNG(0)gydF4y2Ba
要创建批评批读表示,首先创建一个具有16个输入和一个输出的深度神经网络。批评网络的输出是特定观察的状态值函数。gydF4y2Ba
批评= [featureInputLayer(numobservations,gydF4y2Ba'正常化'gydF4y2Ba,gydF4y2Ba“没有”gydF4y2Ba,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'观察'gydF4y2Ba) fullyConnectedLayer (128,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'fc1'gydF4y2Ba) reluLayer (gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'relu1'gydF4y2Ba) fullyConnectedLayer (128,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'fc2'gydF4y2Ba) reluLayer (gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'relu2'gydF4y2Ba) fullyConnectedLayer (128,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'fc3'gydF4y2Ba) reluLayer (gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'relu3'gydF4y2Ba)全康连接层(1,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'fc4'gydF4y2Ba)];gydF4y2Ba
为PPO代理商创建批评者。有关更多信息,请参见gydF4y2BarlvalueerepresentationgydF4y2Ba和gydF4y2BarlRepresentationOptionsgydF4y2Ba.gydF4y2Ba
QuandOptions = rlrepresentationOptions(gydF4y2Ba“LearnRate”gydF4y2Ba,1e-3,gydF4y2Ba“GradientThreshold”gydF4y2Ba,1);评论家= rlvaluerepresentation(批评,观察invo,gydF4y2Ba......gydF4y2Ba'观察'gydF4y2Ba,{gydF4y2Ba'观察'gydF4y2Ba},批评);gydF4y2Ba
actor网络的输出是当车辆处于某个状态时采取每个可能的转向动作的概率。创建演员深神经网络。gydF4y2Ba
ActorNetWork = [FeatureInputLayer(NumObServations,gydF4y2Ba'正常化'gydF4y2Ba,gydF4y2Ba“没有”gydF4y2Ba,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'观察'gydF4y2Ba) fullyConnectedLayer (128,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'fc1'gydF4y2Ba) reluLayer (gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'relu1'gydF4y2Ba) fullyConnectedLayer (128,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'fc2'gydF4y2Ba) reluLayer (gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'relu2'gydF4y2Ba)全连接列(数量,gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba“出”gydF4y2Ba) softmaxLayer (gydF4y2Ba“名字”gydF4y2Ba,gydF4y2Ba'actionprob'gydF4y2Ba)];gydF4y2Ba
为PPO代理创建一个随机参与者表示。有关更多信息,请参见gydF4y2BarlstochastorrepresentationgydF4y2Ba.gydF4y2Ba
ACTOROPTIONS = RLREPRESENTATIONOPTIONS(gydF4y2Ba“LearnRate”gydF4y2Ba,2e-4,gydF4y2Ba“GradientThreshold”gydF4y2Ba,1);Actor = rlstochasticRorrepresentation(Actornetwork,观察Info,ActionInfo,gydF4y2Ba......gydF4y2Ba'观察'gydF4y2Ba,{gydF4y2Ba'观察'gydF4y2Ba},ActorOptions);gydF4y2Ba
指定代理选项并创建PPO代理。有关PPO代理选项的详细信息,请参阅gydF4y2BarlPPOAgentOptionsgydF4y2Ba.gydF4y2Ba
代理= rlppoagentoptions(gydF4y2Ba......gydF4y2Ba'sampletime'gydF4y2Ba,ts,gydF4y2Ba......gydF4y2Ba'经验热诚'gydF4y2Ba, 200,gydF4y2Ba......gydF4y2Ba'ClipFactor'gydF4y2Ba, 0.2,gydF4y2Ba......gydF4y2Ba“EntropyLossWeight”gydF4y2Ba,0.01,gydF4y2Ba......gydF4y2Ba'minibatchsize'gydF4y2Ba,64,gydF4y2Ba......gydF4y2Ba'numechoch'gydF4y2Ba,3,gydF4y2Ba......gydF4y2Ba'vieildereextimatemethod'gydF4y2Ba,gydF4y2Ba“gae”gydF4y2Ba,gydF4y2Ba......gydF4y2Ba“GAEFactor”gydF4y2Ba, 0.95,gydF4y2Ba......gydF4y2Ba“DiscountFactor”gydF4y2Ba,0.998);代理= rlppoagent(演员,批评者,代理商);gydF4y2Ba
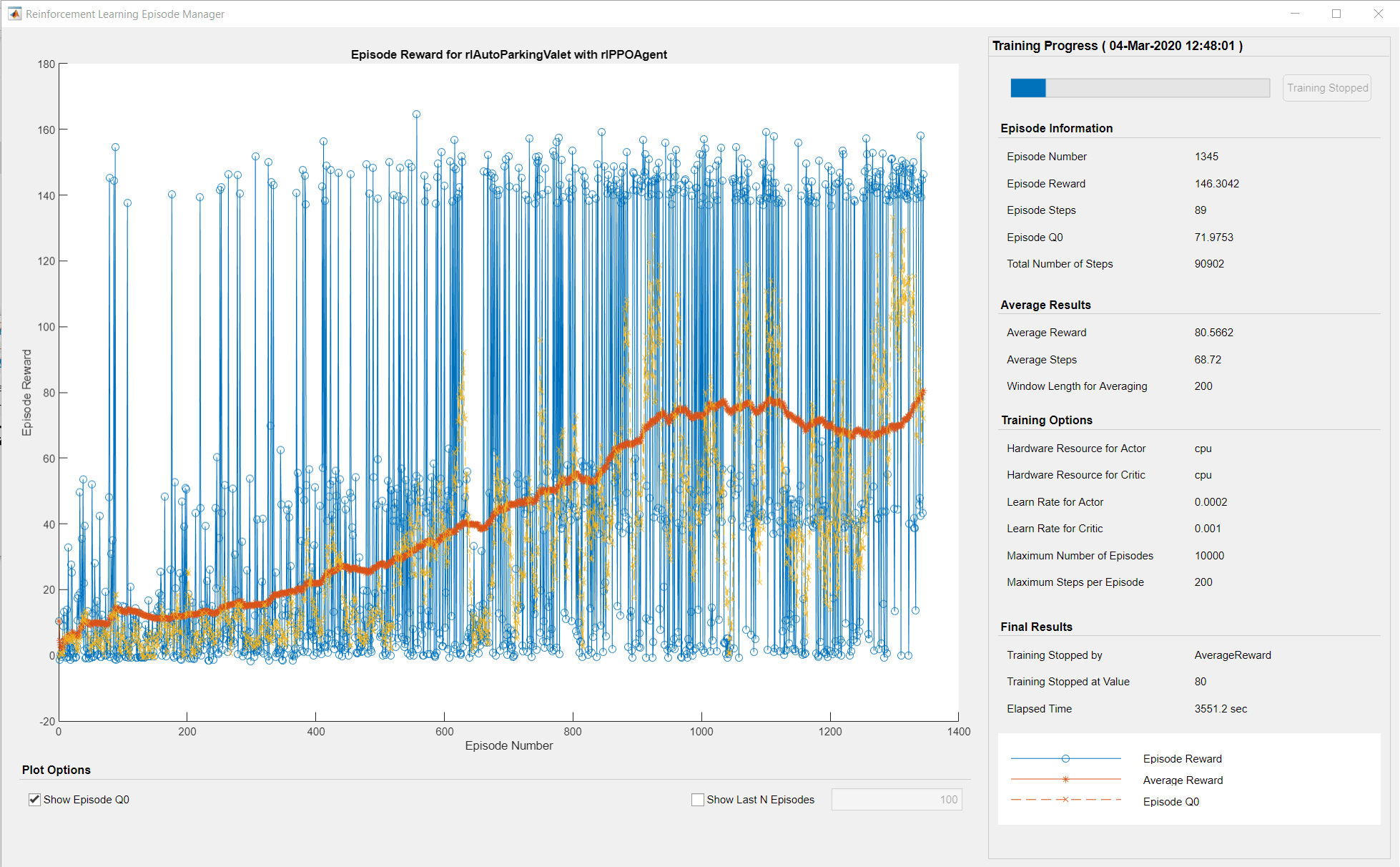
在训练过程中,agent收集经验,直到达到200步的经验视界或事件结束,然后从64个经验小批量进行三个阶段的训练。目标函数剪辑系数为0.2可提高训练稳定性,折扣系数为0.998可鼓励长期奖励。用GAE因子为0.95的广义优势估计方法减少了评价输出中的方差。gydF4y2Ba
火车代理gydF4y2Ba
对于本例,您对代理进行最多10000集的训练,每集最多持续200个时间步骤。当达到最大集数或平均奖励超过100集时,训练结束。gydF4y2Ba
指定用于培训的选项gydF4y2BarltringOptions.gydF4y2Ba对象。gydF4y2Ba
trainOpts = rlTrainingOptions (gydF4y2Ba......gydF4y2Ba'maxepisodes'gydF4y2Ba, 10000,gydF4y2Ba......gydF4y2Ba'maxstepperepisode'gydF4y2Ba, 200,gydF4y2Ba......gydF4y2Ba“ScoreAveragingWindowLength”gydF4y2Ba, 200,gydF4y2Ba......gydF4y2Ba“阴谋”gydF4y2Ba,gydF4y2Ba'培训 - 进步'gydF4y2Ba,gydF4y2Ba......gydF4y2Ba“StopTrainingCriteria”gydF4y2Ba,gydF4y2Ba'AverageReward'gydF4y2Ba,gydF4y2Ba......gydF4y2Ba'stoptriningvalue'gydF4y2Ba,80);gydF4y2Ba
使用该代理商培训gydF4y2Ba火车gydF4y2Ba功能。培训此代理是一个计算密集型进程,需要几分钟才能完成。要在运行此示例的同时节省时间,请通过设置加载预制代理gydF4y2BadoTraininggydF4y2Ba到目前为止gydF4y2Ba假gydF4y2Ba.训练代理人,套装gydF4y2BadoTraininggydF4y2Ba到目前为止gydF4y2Ba真实gydF4y2Ba.gydF4y2Ba
dotraining = false;gydF4y2Ba如果gydF4y2BadoTraining trainingStats = train(agent,env,trainOpts);gydF4y2Ba其他的gydF4y2Ba负载(gydF4y2Ba'rlautoparkingvaletagent.mat'gydF4y2Ba,gydF4y2Ba'代理'gydF4y2Ba);gydF4y2Ba结束gydF4y2Ba
模拟代理人gydF4y2Ba
模拟模型将车辆停放在免费停车位。要模拟不同位置的车辆停车,请在以下代码中更改可用点位置。gydF4y2Ba
freeSpotIdx = 7;gydF4y2Ba%免费点位置gydF4y2Basim (mdl);gydF4y2Ba
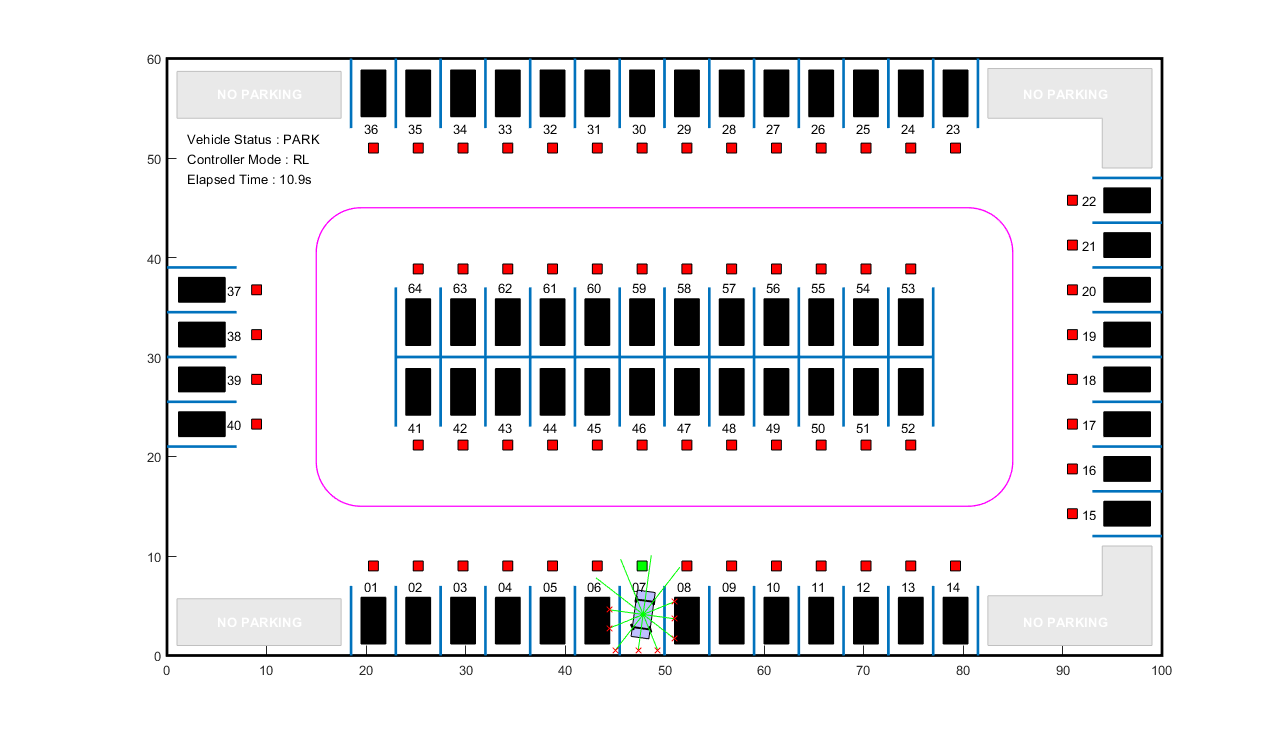
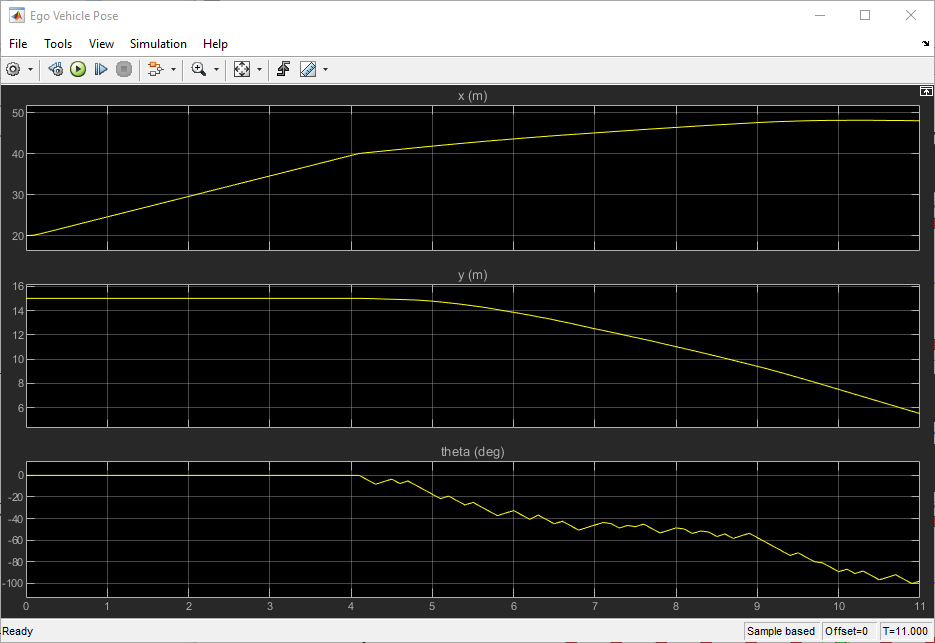
车辆达到目标位姿在指定的误差公差+/- 0.75米(位置)和+/-10度(方向)。gydF4y2Ba
要查看自我车辆位置和方向,打开自我车辆姿势范围。gydF4y2Ba
另请参阅gydF4y2Ba
相关主题gydF4y2Ba
选择一个网站gydF4y2Ba
选择一个网站,以便在可用的地方进行翻译的内容,并查看本地活动和优惠。根据您的位置,我们建议您选择:gydF4y2Ba.gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba您还可以从以下列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- América拉丁gydF4y2Ba(Español)gydF4y2Ba
- 加拿大gydF4y2Ba(英文)gydF4y2Ba
- 美国gydF4y2Ba(英文)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英文)gydF4y2Ba
- 丹麦gydF4y2Ba(英文)gydF4y2Ba
- 德意志gydF4y2Ba(德意志)gydF4y2Ba
- 西班牙gydF4y2Ba(Español)gydF4y2Ba
- 芬兰gydF4y2Ba(英文)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英文)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英文)gydF4y2Ba
- 荷兰gydF4y2Ba(英文)gydF4y2Ba
- 挪威gydF4y2Ba(英文)gydF4y2Ba
- 奥地利gydF4y2Ba(德意志)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英文)gydF4y2Ba
- 瑞典gydF4y2Ba(英文)gydF4y2Ba
- 瑞士gydF4y2Ba
- 英国gydF4y2Ba(英文)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英文)gydF4y2Ba
- 印度gydF4y2Ba(英文)gydF4y2Ba
- 新西兰gydF4y2Ba(英文)gydF4y2Ba
- 中国人gydF4y2Ba
- 日本语gydF4y2Ba(日本语)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
