使用长短期内存网络对ECG信号进行分类
这个例子展示了如何使用深度学习和信号处理来分类PhysioNet 2017挑战中的心跳心电图(ECG)数据。具体来说,这个例子使用了长短期记忆网络和时频分析。
介绍
心电图记录了一个人在一段时间内的心脏电活动。医生用心电图来检测病人的心跳是否正常或不规则。
心房颤动(AFIB)是一种不规则的心跳,当心脏的上腔室,Atria,与下腔室,心室的心脏的上室发生搏动。
此示例使用来自PhysioIonet 2017挑战的ECG数据[1],[2],[3.],可用https://physionet.org/challenge/2017/.数据包括一组在300hz采样的心电信号,并由一组专家分为四个不同的类别:正常(N), AFib (a),其他节律(O)和噪声记录(~)。这个例子展示了如何使用深度学习自动化分类过程。该程序探索了一个二值分类器,可以区分正常心电信号显示的迹象AFib。
此示例使用长期短期内存(LSTM)网络,一种复发性神经网络(RNN)非常适合研究序列和时间序列数据。LSTM网络可以在序列的时间步长之间学习长期依赖性。LSTM层(lstmlayer.(深度学习工具箱))可以在向前方向上查看时间序列,而双向LSTM层(bilstmLayer(深度学习工具箱))可以从正反两个方向查看时间序列。本例使用双向LSTM层。
要加速培训过程,请在带GPU的计算机上运行此示例。如果您的机器具有GPU和并行计算工具箱™,则Matlab®自动使用GPU进行培训;否则,它使用CPU。
加载和检查数据
跑过reckphysionetdata.脚本从PhysioNet网站下载数据并生成mat文件(physionetdata.mat.)包含以适当格式的ECG信号。下载数据可能需要几分钟。
ReadPhysionetData负载physionetdata.
加载操作将两个变量添加到工作区中:信号和标签.信号是保存ECG信号的单元数组。标签是一个类别数组,包含信号的相应ground-truth标签。
信号(1:5)
ans =.5×1单元阵列{1×9000双} {1×9000双} {1×18000双} {1×9000双} {1×18000双倍}
标签(1:5)
ans =.5×1分类n n n a a
使用概括可以查看数据中包含多少个AFIB信号和正常信号。
摘要(标签)
一个738 n 5050
生成信号长度的直方图。大多数信号长度为9000个样品。
l = cellfun(@长度,信号);H =直方图(L);XTICKS(0:3000:18000);XTicklabels(0:3000:18000);标题('信号长度')包含(“长度”) ylabel ('数数')

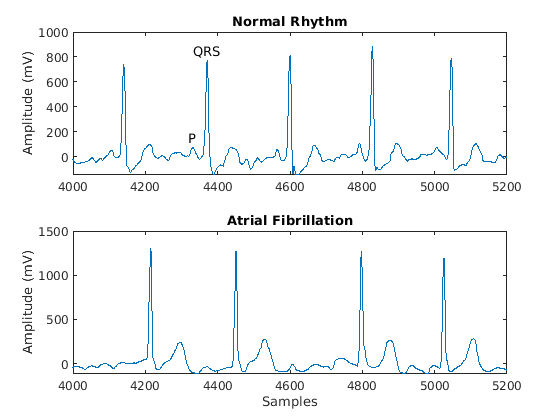
从每个类中可视化一个信号的段。AFIB心跳以不规则的间隔间隔开,而正常心跳定期发生。AFIB心跳信号也经常缺乏P波,在QRS复合物中脉冲在正常的心跳信号之前。正常信号的曲线显示P波和QRS复合物。
正常={1}信号;aFib ={4}信号;次要情节(2,1,1)情节(正常的)标题(“正常的节奏”) xlim((4000、5200))ylabel ('幅度(mv)')文本(4330、150、'P'那“HorizontalAlignment”那'中央')文本(4370、850、'qrs'那“HorizontalAlignment”那'中央')子图(2,1,2)绘图(AFIB)标题('心房颤动')XLIM([4000,5200])Xlabel(“样本”) ylabel ('幅度(mv)')
准备培训数据
在培训期间,Trainnetwork.函数将数据分割为小批。然后,该函数在相同的小批处理中填充或截断信号,以便它们都具有相同的长度。过多的填充或截断会对网络的性能产生负面影响,因为网络可能会根据添加或删除的信息错误地解释信号。
为避免过度填充或截断,请应用segmentSignals功能到ECG信号,因此它们是全部9000个样本。该功能忽略具有少于9000个样本的信号。如果信号有超过9000个样本,segmentSignals将其分割成尽可能多的9000个样本段,并忽略剩余的样本。例如,一个带有18500个样本的信号变成两个9000个样本的信号,其余的500个样本被忽略。
[信号,标签] = SEGMESSIGNALS(信号,标签);
查看前五个元素信号阵列以验证每个条目现在是9000个样本。
信号(1:5)
ans =.5×1单元阵列{1×9000双} {1×9000双} {1×9000双} {1×9000双} {1×9000双倍}
使用原始信号数据列车
要设计分类器,请使用前一节中生成的原始信号。将信号分割成训练集来训练分类器和测试集来测试分类器在新数据上的准确性。
使用概括功能表明,AFIB信号与正常信号的比率为718:4937,或大约1:7。
摘要(标签)
a718n4937
因为大约7/8的信号是Normal,分类器就会知道,只需将所有信号分类为Normal就可以获得很高的准确率。为了避免这种偏差,通过在数据集中复制AFib信号来增加AFib数据,使其有相同数量的Normal和AFib信号。这种重复,通常称为过采样,是一种用于深度学习的数据增强形式。
根据他们的班级分割信号。
AFIBX =信号(标签==“一个”);afiby =标签(标签==“一个”);normalX(标签= = =信号'n');normaly =标签(标签=='n');
下一步,使用dividerand将目标从每个班级划分为培训和测试集。
[trainIndA, ~, testIndA] = dividerand(718年,0.9,0.0,0.1);[trainIndN, ~, testIndN] = dividerand(4937年,0.9,0.0,0.1);XTrainA = afibX (trainIndA);YTrainA = afibY (trainIndA);XTrainN = normalX (trainIndN);YTrainN =饱和(trainIndN);XTestA = afibX (testIndA);YTestA = afibY (testIndA);XTestN = normalX (testIndN);YTestN =饱和(testIndN);
现在有646个AFIB信号和4443个正常信号进行训练。要在每个类中实现相同数量的信号,请使用前4438正常信号,然后使用repmat.重复前634个AFIB信号七次。
用于测试,有72个AFIB信号和494正常信号。使用前490个正常信号,然后使用repmat.将前70个AFib信号重复7次。默认情况下,神经网络在训练前随机打乱数据,确保相邻的信号不都有相同的标签。
XTrain = [Repmat(Xtraina(1:634),7,1);XTrainn(1:4438)];YTrain = [Repmat(Ytraina(1:634),7,1);YTrainn(1:4438)];xtest = [repmat(xtesta(1:70),7,1);XTESTN(1:490)];ytest = [Repmat(Ytesta(1:70),7,1);ytestn(1:490);];
现在,正常和AFIB信号之间的分布在训练集和测试集中均衡均衡。
摘要(Ytrain)
一个4438 n 4438
摘要(ytest)
490 n 490
定义LSTM网络架构
LSTM网络可以学习序列数据时间步长之间的长期依赖关系。本例使用双向LSTM层bilstmLayer,因为它从正反两个方向看序列。
因为每个输入信号都有一个维度,所以将输入大小指定为长度为1的序列。指定一个双向LSTM层,输出大小为100,输出序列的最后一个元素。该命令指示双向LSTM层将输入时间序列映射到100个特性中,然后为全连接层准备输出。最后,通过包含一个大小为2的完全连接层,然后是一个softmax层和一个分类层来指定两个类。
层= [...sequenceInputLayer(1)BilstMlayer(100,'OutputMode'那'最后的')全连接层(2)SoftMaxLayer ClassificationLayer]
图层= 5x1层阵列,带有图层:1''序列输入序列输入用1尺寸2''Bilstm Bilstm,具有100个隐藏单元3''完全连接的2完全连接的第4层''Softmax Softmax 5''分类输出CrossentRopyex
接下来指定分类器的训练选项。设置“MaxEpochs”到10以允许网络通过培训数据进行10。一种'minibatchsize'150指示网络一次查看150个训练信号。一个'italllearnrate'0.01有助于加快训练过程。指定一个“SequenceLength”将信号分成更小的部分,这样机器就不会因为一次查看太多数据而耗尽内存。设置”GradientThreshold'通过防止渐变太大来稳定培训过程。指定'plots'作为“训练进步”根据迭代的数量增加,生成显示培训进度图形的图表。放'verbose'来错误的要抑制与图中所示的数据对应的表输出。如果您想看到此表,请设置'verbose'来真正的.
这个例子使用了自适应矩估计(ADAM)求解器。ADAM在lstm之类的rnn上比默认的SGDM求解器表现得更好。
选择= trainingOptions ('亚当'那...“MaxEpochs”10...'minibatchsize', 150,...'italllearnrate', 0.01,...“SequenceLength”, 1000,...'gradientthreshold',1,...'executionenvironment'那“汽车”那...“阴谋”那“训练进步”那...'verbose'、假);
训练LSTM网络
使用指定的培训选项和图层架构列车LSTM网络Trainnetwork..因为训练集很大,培训过程可能需要几分钟。
net = trainnetwork(xtrain,ytrain,图层,选项);

训练进度图的顶部子图表示训练准确性,这是每个迷你批处理上的分类准确性。当培训成功进行时,该值通常会增加100%。底部子图显示训练丢失,这是每个迷你批处理上的跨熵丢失。当培训成功进行时,该值通常会降低零。
如果训练不收敛,则该图可能会在不在某个向上或向下方向上培训的值之间振荡。这种振荡意味着训练准确性没有改善,训练损失没有减少。这种情况可能发生在训练的开始,或者在训练准确性的一些初步提高之后,地块可能会有高原。在许多情况下,更改培训选项可以帮助网络实现融合。减少MiniBatchSize或减少InitialLearnRate可能导致更长的培训时间,但它可以帮助网络了解更好。
分类器的训练精度在50%到60%之间振荡,在10个时代结束时,它已经花了几分钟的时间来训练。
可视化培训和测试的准确性
计算培训准确性,这表示分类器对培训的信号的准确性。首先,分类培训数据。
XTrain trainPred =分类(净,“SequenceLength”,1000);
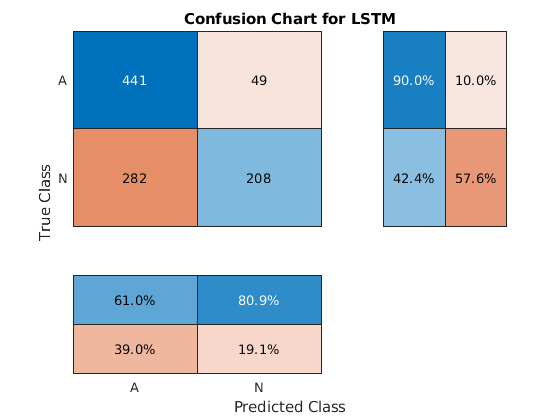
在分类问题中,混淆矩阵用于可视化对真实值的一组数据上的分类器的性能。目标类是信号的地面真值标签,输出类是网络被网络分配给信号的标签。轴标签代表类标签,AFIB(A)和正常(n)。
使用confusionchart命令计算测试数据预测的总体分类精度。指定'rowsmumary'作为'行标准化'显示行摘要中的真正阳性率和假阳性率。另外,指定“ColumnSummary”作为'列 - 归一化'显示列摘要中的肯定预测值和假发现速率。
lstmaccuracy = sum(trainpred == ytrain)/ numel(ytrain)* 100
LSTMAccuracy = 61.7283
图杂志(Ytrain,TrainPred,“ColumnSummary”那'列 - 归一化'那...'rowsmumary'那'行标准化'那'标题'那'LSTM的混乱图');

现在将测试数据分类为同一网络。
testpred =分类(net,xtest,“SequenceLength”,1000);
计算测试精度,并将分类性能可视化为混淆矩阵。
lstmaccuracy = sum(testpred == ytest)/ numel(ytest)* 100
lstmaccuracy = 66.2245.
Figure ConfusionChart(ytest,testpred,“ColumnSummary”那'列 - 归一化'那...'rowsmumary'那'行标准化'那'标题'那'LSTM的混乱图');
利用特征提取提高性能
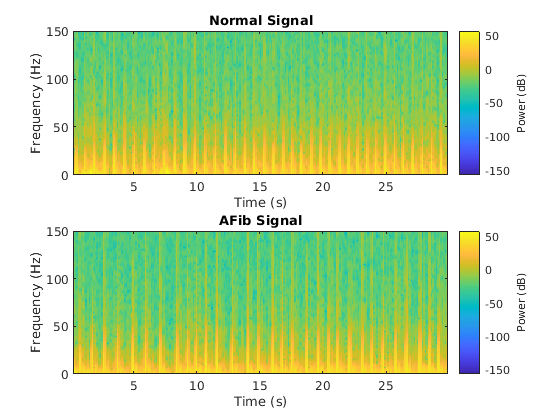
来自数据的特征提取可以帮助提高分类器的培训和测试精度。要确定提取的功能,此示例适应了一种计算时间频率图像(例如频谱图)的方法,并使用它们来训练卷积神经网络(CNNS)[4.],[5.]。
可视化每种信号的谱图。
fs = 300;图次要情节(2,1,1);pspectrum(正常,fs,的谱图那'timeresolution',0.5)标题('正常信号'次要情节(2,1,2);PSPectrum(AFIB,FS,的谱图那'timeresolution',0.5)标题('afib信号')
因为这个例子使用的是LSTM而不是CNN,所以将这种方法转换成适用于一维信号是很重要的。时频矩从谱图中提取信息。每个矩量都可以作为一维特征输入到LSTM中。
在时域中探索两个TF瞬间:
瞬时频率(
instfreq.)谱熵(
pentropy)
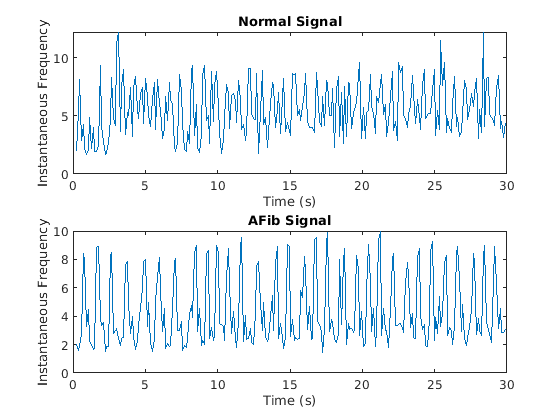
这instfreq.函数估计一个信号的时变频率作为功率谱的第一阶矩。该函数利用短时间傅里叶变换在时间窗上计算谱图。在本例中,该函数使用255个时间窗口。函数的时间输出对应于时间窗口的中心。
可视化每种信号的瞬时频率。
[instfreqa,ta] = instfreq(afib,fs);[instfreqn,tn] = instfreq(正常,fs);图次要情节(2,1,1);绘制(TN,Instfreqn)标题('正常信号')包含(“时间(s)”) ylabel ('瞬时频率'次要情节(2,1,2);instFreqA情节(tA)标题('afib信号')包含(“时间(s)”) ylabel ('瞬时频率')
使用Cellfun.申请instfreq.对训练和测试集中的每个单元函数。
instfreqtrain = cellfun(@(x)instfreq(x,fs)',xtrain,“UniformOutput”、假);instfreqtest = cellfun(@(x)instfreq(x,fs)',xtest,“UniformOutput”、假);
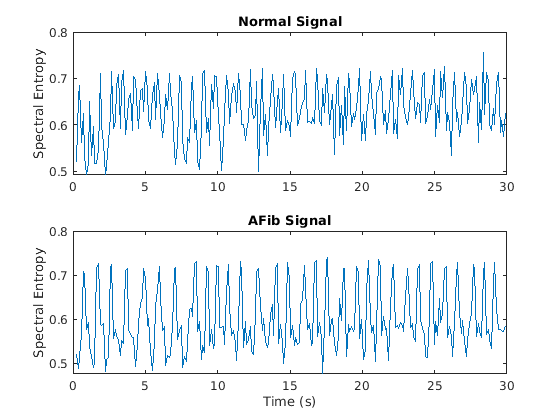
光谱熵措施如何尖刺平衡信号的光谱是多么的。具有尖光谱的信号,如正弦曲线的总和,具有低光谱熵。具有平坦光谱的信号,如白噪声,具有高光谱熵。这pentropy功能估计基于功率谱图的光谱熵。与瞬时频率估计箱一样,pentropy使用255窗口来计算频谱图。函数的时间输出对应于时间窗口的中心。
可视化每种信号的光谱熵。
[Pentropea,Ta2] = Pentropy(AFIB,FS);[Pentropyn,TN2] = Pentropy(正常,FS);图形子图(2,1,1)绘图(TN2,Pentropyn)标题('正常信号') ylabel ('光谱熵') subplot(2,1,2) plot(tA2,pentropyA) title(标题)'afib信号')包含(“时间(s)”) ylabel ('光谱熵')
使用Cellfun.申请pentropy对训练和测试集中的每个单元函数。
pentropytrain = cellfun(@(x)pentropy(x,fs)',xtrain,“UniformOutput”、假);pentropytest = cellfun(@(x)pentropy(x,fs)',xtest,“UniformOutput”、假);
连接特征,使新的训练集和测试集中的每个单元格都有两个维度,或者两个特征。
xtrain2 = cellfun(@(x,y)[x; y],instfreqtrain,pentropytrain,“UniformOutput”、假);XTest2 = cellfun (@ (x, y) (x, y), instfreqTest, pentropyTest,“UniformOutput”、假);
可视化新输入的格式。每个单元格不再包含一个9000样品长信号;现在它包含两个255样本长的功能。
XTrain2(1:5)
ans =.5×1单元阵列{2×255 double} {2×255 double} {2×255 double} {2×255 double} {2×255 double}
标准化数据
瞬时频率和谱熵的意义相差几乎一个数量级。此外,由于瞬时频率均值过高,LSTM无法有效学习。当网络适合于大均值和大范围值的数据时,大输入可能会减缓网络的学习和收敛[6.]。
意思是(instFreqN)
ANS = 5.5615.
意思(pentropyn)
ans = 0.6326.
使用培训集平均值和标准偏差来标准化培训和测试集。标准化或Z评分是一种流行的方式来提高培训期间的网络性能。
xv = [xtrain2 {:}];mu =平均值(xv,2);sg = std(xv,[],2);XTrainsd = XTrain2;xtrainsd = cellfun(@(x)(x-mu)./ sg,xtrainsd,“UniformOutput”、假);XTestSD = XTest2;XTestSD = cellfun (@ (x)(即xμ)。/ sg, XTestSD,“UniformOutput”、假);
给出了标准化瞬时频率和谱熵的平均值。
instfreqnsd = xtrainsd {1}(1,:);pentropynsd = xtrainsd {1}(2,:);意思(instfreqnsd)
ans = -0.3211.
意思是(pentropyNSD)
ans = -0.2416
修改LSTM网络架构
既然每个信号都有两个维度,就必须通过将输入序列大小指定为2来修改网络体系结构。指定一个双向LSTM层,输出大小为100,输出序列的最后一个元素。通过包含一个大小为2的完全连接层,然后是一个softmax层和一个分类层来指定两个类。
层= [...SequenceInputLayer(2)BilstMlayer(100,'OutputMode'那'最后的')全连接层(2)SoftMaxLayer ClassificationLayer]
Layer = 5x1 Layer array with layers: 1 " Sequence Input Sequence Input with 2 dimensions 2 " BiLSTM BiLSTM with 100 hidden units 3 " full Connected 2 full Connected Layer 4 " Softmax Softmax 5 " Classification Output cross - sentropyex . 1 " Sequence Input Sequence Input with 2 dimensions 2 " BiLSTM BiLSTM with 100 hidden units 3 " full Connected 2 full Connected Layer 4 " Softmax Softmax 5 " Classification Output cross - sentropyex . 1
指定培训选项。将epochs的最大数量设置为30,以允许网络通过培训数据进行30。
选择= trainingOptions ('亚当'那...“MaxEpochs”30岁的...'minibatchsize', 150,...'italllearnrate', 0.01,...'gradientthreshold',1,...'executionenvironment'那“汽车”那...“阴谋”那“训练进步”那...'verbose'、假);
用时频功能列车LSTM网络
使用指定的培训选项和图层架构列车LSTM网络Trainnetwork..
net2 = trainNetwork (XTrainSD、YTrain层,选择);
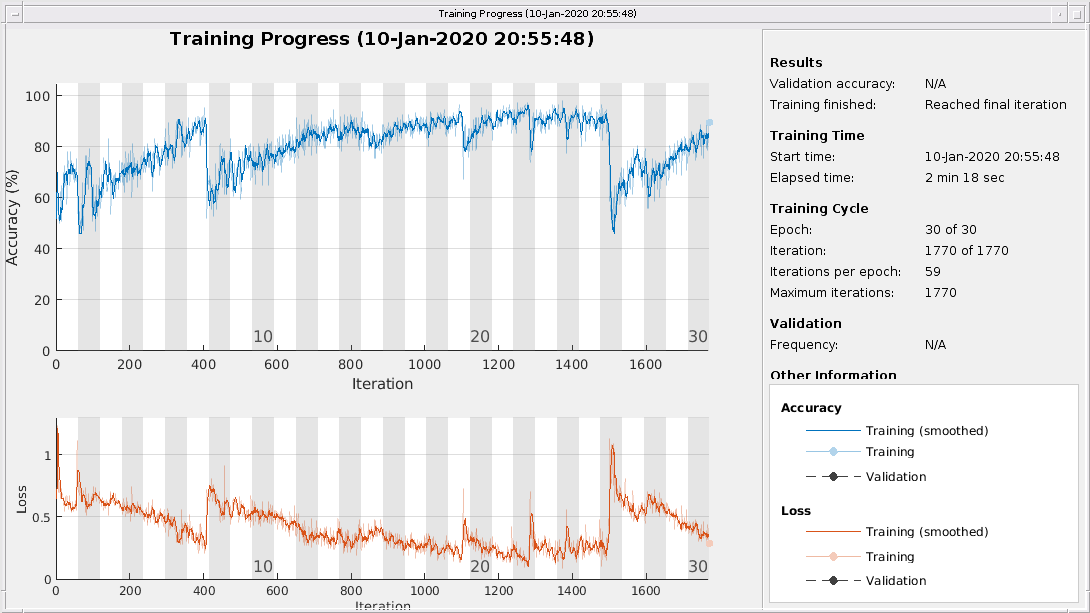
训练的准确性有了很大的提高。交叉熵损失趋向于0。此外,训练所需的时间减少,因为TF时刻比原始序列更短。
可视化培训和测试的准确性
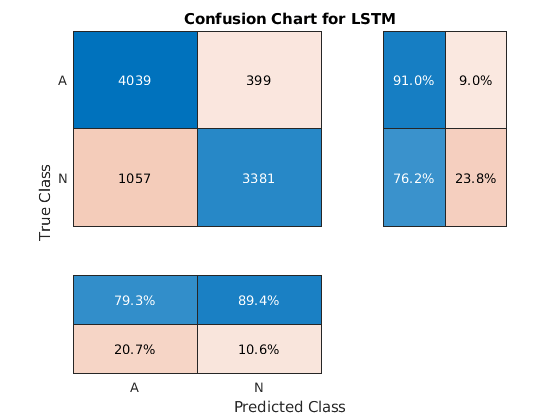
使用更新的LSTM网络对培训数据进行分类。可视化分类性能作为混淆矩阵。
trainpred2 =分类(net2,xtrainsd);lstmaccuracy = sum(trainpred2 == ytrain)/ numel(ytrain)* 100
lstmaccuracy = 83.5962.
图杂志(Ytrain,TrainPred2,“ColumnSummary”那'列 - 归一化'那...'rowsmumary'那'行标准化'那'标题'那'LSTM的混乱图');
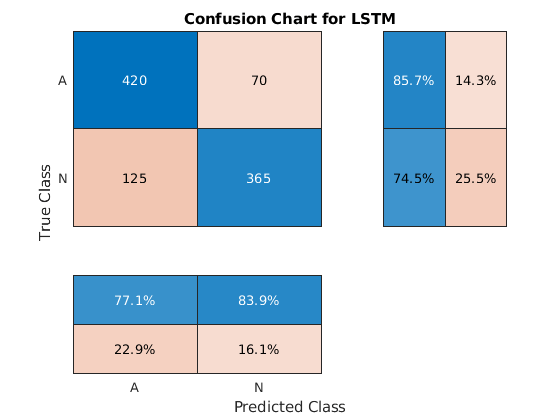
使用更新的网络对测试数据进行分类。绘制混淆矩阵来检查测试精度。
testpred2 =分类(net2,xtestsd);lstmaccuracy = sum(testpred2 == ytest)/ numel(ytest)* 100
lstmaccuracy = 80.1020
图困惑派(ytest,testpred2,“ColumnSummary”那'列 - 归一化'那...'rowsmumary'那'行标准化'那'标题'那'LSTM的混乱图');
结论
这个例子展示了如何利用LSTM网络构建一个分类器来检测心电信号中的房颤。该程序使用过采样来避免分类偏差,当一个人试图在主要由健康患者组成的人群中检测异常情况时发生。使用原始信号数据训练LSTM网络会导致较差的分类精度。利用两个时频矩特征对每个信号进行训练,显著提高了分类性能,减少了训练时间。
参考
[1]从短暂的单一主管心电图记录:2017年心脏病学挑战中的物理仪/计算。https://physionet.org/challenge/2017/
[2] Clifford,Gari,Chengyu Liu,Benjamin Moody,Li-Wei H. Lehman,Ikaro Silva,Qiao Li,Alistair Johnson和Roger G. Mark。“自动对自动对焦分类,从简短的单一主管心电图记录:2017年心脏病学挑战中的物理仪计算。”计算在心脏病学(雷恩:IEEE)。Vol. 44, 2017, pp. 1-4。
[3] Goldberger, A. L., L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. Ch. Ivanov, R. G. Mark, J. E. miietus, G. B. Moody, C.-K。彭和斯坦利。“PhysioBank、PhysioToolkit和PhysioNet:复杂生理信号新研究资源的组成部分”。循环.卷。101,23,33,2000年6月13日,PP。E215-E220。http://circ.ahajournals.org/content/101/23/e215.full.
[4] Pons,Jordi,Thomas Lidy和Xavier Serra。“用音乐动机的卷积神经网络试验”。第14届基于内容的多媒体索引讲习班(CBMI).2016年6月。
[5], D。“深度学习彻底改变了助听器,”IEEE频谱,第54卷,第3期,2017年3月,页32-37。doi: 10.1109 / MSPEC.2017.7864754。
[6] Brownlee,杰森。如何在Python中扩展长期短期记忆网络的数据.2017年7月7日。https://machinelearningmastery.com/how-to-scale-data-for-nong-short-term-memory-networks-in-python/。
也可以看看
职能
instfreq.|pentropy|bilstmLayer(深度学习工具箱)|lstmlayer.(深度学习工具箱)|trainingOptions(深度学习工具箱)|Trainnetwork.(深度学习工具箱)
相关的话题
- 长短期内存网络(深度学习工具箱)
你也可以从以下列表中选择一个网站:
