oobPermutedPredictorImportance
预测对袋外预测测量观测的置换的重要性估计,用于分类树的随机森林
描述
偶尔= OobperMutedPredictorimportance(Mdl)Mdl.Mdl必须是一个ClassificationBaggedensemble.模型对象。
输入参数
输出参数
例子
估计预测因子的重要性
加载census1994数据集。考虑一项预测人员薪水类别的模型,鉴于其年龄,工人阶级,教育水平,武术,种族,性别,资本收益和损失以及每周工作时间的数量。
负载census1994x = AdultData(:,{'年龄','工作组',“education_num”,“marital_status”,'种族',......'性别',“capital_gain”,“capital_loss”,'每周几小时','薪水'});
您可以使用整个数据集培训50个分类树的随机森林。
Mdl = fitcensemble (X,'薪水','方法','包','numlearnicalnycle', 50);
fitcensemble.使用默认模板树对象Templatetree()作为一个弱学习者'方法'是'包'.在此示例中,为了再现性,请指定'可重复',真实创建树模板对象时,然后将对象用作弱的学习者。
RNG('默认')重复性的%t = templateTree ('可重复',真的);%用于随机预测器选择的重现性Mdl = fitcensemble (X,'薪水','方法','包','numlearnicalnycle', 50岁,“学习者”t);
Mdl是A.ClassificationBaggedensemble.模型。
通过排列出包外的观察来估计预测器的重要性。使用条形图比较估计值。
小鬼= oobPermutedPredictorImportance (Mdl);图;酒吧(imp);标题(“out - bag perised Predictor Importance Estimates”);ylabel(“估计”);包含(“预测”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
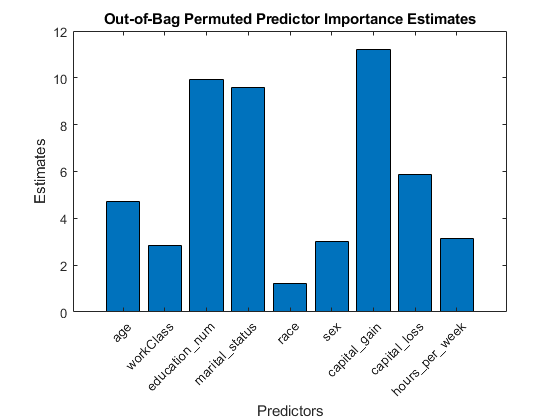
偶尔是预测器重要性估计的1 × 9向量。较大的值表示对预测有较大影响的预测器。在这种情况下,婚姻状况是最重要的预测因素,其次是capital_gain.
使用并行计算的预测器重要性的无偏估计
加载census1994数据集。考虑一项预测人员薪水类别的模型,鉴于其年龄,工人阶级,教育水平,武术,种族,性别,资本收益和损失以及每周工作时间的数量。
负载census1994x = AdultData(:,{'年龄','工作组',“education_num”,“marital_status”,'种族',......'性别',“capital_gain”,“capital_loss”,'每周几小时','薪水'});
显示使用的类别中表示的类别数概括.
摘要(x)
变量:年龄:32561×1双重值:Min 17中位数37 Max 90 Workclass:32561×1分类价值:联邦 - GOV 960 Loct-Gov 2093从未工作过7私人22696 Self-Emp-Inc 1116自我Emp-Inc 1116自我Emp-Not-INC 2541 State-Gov 1298没有支付14 Nummissing 1836教育:32561×1双价值:Min 1中位数10 Max 16 Marital_Status:32561×1分类价值:离婚4443已婚 - 自夸23结婚 - Civ-Spouse 14976已婚 -年代pouse-absent 418 Never-married 10683 Separated 1025 Widowed 993 race: 32561×1 categorical Values: Amer-Indian-Eskimo 311 Asian-Pac-Islander 1039 Black 3124 Other 271 White 27816 sex: 32561×1 categorical Values: Female 10771 Male 21790 capital_gain: 32561×1 double Values: Min 0 Median 0 Max 99999 capital_loss: 32561×1 double Values: Min 0 Median 0 Max 4356 hours_per_week: 32561×1 double Values: Min 1 Median 40 Max 99 salary: 32561×1 categorical Values: <=50K 24720 >50K 7841
由于分类变量中的几个类别与连续变量中的级别相比,标准推车,预测器分裂算法更喜欢在分类变量上拆分连续预测器。
使用整个数据集列车50种分类树的随机森林。为了种植无偏的树木,请指定用于分裂预测器的曲率测试的使用。由于数据中存在缺少值,因此指定代理分割的使用。要重现随机预测器选择,请使用随机数发生器的种子rng并指定'可重复',真实.
RNG('默认')重复性的%t = templateTree (“PredictorSelection”,“弯曲”,'代理',“上”,......'可重复',真的);随机预测器选择的再现性的%Mdl = fitcensemble (X,'薪水','方法','包','numlearnicalnycle', 50岁,......“学习者”t);
通过排列出包外的观察来估计预测器的重要性。并行执行计算。
选项= statset(“UseParallel”,真的);Imp = OobperMutedPredictorimportance(MDL,'选项',选项);
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。
使用条形图比较估计值。
图酒吧(IMP)标题(“out - bag perised Predictor Importance Estimates”) ylabel (“估计”)xlabel(“预测”)H = GCA;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;

在这种情况下,capital_gain是最重要的预测因素,其次是martial_status.将这些结果与结果进行比较估计预测因子的重要性.
更多关于
提示
在使用随机森林时使用fitcensemble.:
标准CART倾向于选择包含许多不同值(如连续变量)的分离预测因子,而不是包含很少不同值(如分类变量)的分离预测因子[3].如果预测器数据集是异构的,或者如果存在与其他变量相对较少的不同值的预测器,则考虑指定曲率或交互测试。
使用标准CART生长的树木对预测变量相互作用不敏感。此外,与交互测试的应用相比,在存在许多无关的预测因子时,这种树不太可能识别出重要的变量。因此,为了解释预测变量之间的交互作用,并在存在许多不相关变量的情况下识别重要变量,指定交互作用检验[2].
如果培训数据包括许多预测因子并且您想要分析预测的重要性,则指定
'numvariablestosample'的Templatetree.功能“所有”对于合奏的树学习者。否则,软件可能无法选择一些预测器,低估了他们的重要性。
有关更多详细信息,请参阅Templatetree.和选择分割预测器选择技术.
参考
[1] Breiman,L.,J.Friedman,R. Olshen和C. Stone。分类与回归树.佛罗里达州博卡拉顿:CRC出版社,1984。
[2] LOH,W.Y.“具有无偏的变量选择和相互作用检测的回归树。”STATISTICA SINICA., 2002年第12卷,第361-386页。
Loh w.y y and Y.S. Shih分类树的分裂选择方法STATISTICA SINICA.,卷。7,1997,第815-840页。
扩展能力
你也可以从以下列表中选择一个网站:
