ClassificeLcoderConfigurer.
用于高维数据的线性二进制分类的编码器配置器
描述
一个ClassificeLcoderConfigurer.对象是线性分类模型的编码器配置程序(ClassificationLinear)用于高维数据的二进制分类。
编码器配置器提供了方便的特性来配置代码生成选项、生成C/ c++代码以及更新生成代码中的模型参数。
配置代码生成选项,并使用对象属性指定线性模型参数的编码器属性。
为此生成C / C ++代码
预测和更新利用线性函数的分类模型Generatecode..生成C / C ++代码需要马铃薯®编码器™.更新生成的C / C ++代码中的模型参数,而无需重新生成代码。此功能可减少重新生成,重新部署和求解C / C ++代码所需的努力,当您使用新数据或设置重新启动线性模型时。在更新模型参数之前,使用
validatedUpdateInputs验证并提取要更新的模型参数。
此流程图显示使用编码器配置程序的代码生成工作流程。
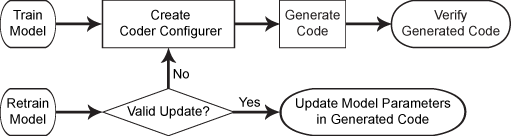
有关线性分类模型的代码生成使用说明和限制,请参阅ClassificationLinear,预测,更新.
创建
通过使用训练得到线性分类模型FitClinear.,使用使用创建模型的编码器配置器Learnercoderconfigurer.属性的编码器属性预测和更新参数。然后,用Generatecode.根据指定的编码器属性生成C/ c++代码。
特性
预测争论
本节中列出的属性指定了编码器属性预测生成的代码中的函数参数。
X- - - - - -预测数据的编码属性
LearnerCoderInput对象
Coder属性的预测器数据传递到生成的C/ c++代码预测线性分类模型的功能,指定为aLearnerCoderInput对象。
控件创建编码器配置器时Learnercoderconfigurer函数的输入参数X属性的默认值LearnerCoderInput编码器属性:
SizeVector—默认值为输入的数组大小X.如果
价值属性的ObservationsIn财产ClassificeLcoderConfigurer.是“行”,那么这SizeVector值是[n p], 在哪里n对应于观测次数和p对应于预测器的数量。如果
价值属性的ObservationsIn财产ClassificeLcoderConfigurer.是“列”,那么这SizeVector值是[p n].
改变…的元素
SizeVector(例如,改变[n p]到[p n]),修改价值属性的ObservationsIn财产ClassificeLcoderConfigurer.相应的行动。您不能修改SizeVector直接价值。VariableDimensions- 默认值是[0 0],表示数组大小是固定的,如SizeVector.您可以将此值设置为
[1 0]如果SizeVector值是[n p]或者[0 1]如果它是[p n],表示数组具有可变大小的行和固定大小的列。例如,[1 0]的第一个值SizeVector(n)是行数的上限,以及第二个值SizeVector(p)为列数。数据类型- 这个值是单或双倍的.默认数据类型取决于输入的数据类型X.可调谐性—必须为真正的,这意味着预测在生成的C/ c++代码中总是包含预测器数据作为输入。
您可以使用点表示法修改编码器属性。例如,要生成C / C ++代码,可接受具有三个预测变量的100个观察(以列)的预测数据(在列中),请指定这些编码器属性X对于编码器配置程序配置程序:
configurer.x.sizevector = [100 3];configur.x.datatype =.“双”;configurer.X.VariableDimensions = [0 0];
[0 0]表示的第一个和第二个维度X(观测数和预测变量数分别)有固定的大小。
要允许生成的C/ c++代码接受多达100个观测值的预测数据,请指定这些编码器属性X:
configurer.x.sizevector = [100 3];configur.x.datatype =.“双”;configurer.X.VariableDimensions = [1 0];
[1 0]表示第一维度X(观察的数量)有一个可变的大小和第二个维度X(预测变量的数量)有一个固定的大小。在本例中,指定的观察数(100)成为生成的C/ c++代码中允许的最大观察数。若要允许任意数量的观察,请指定范围为INF..
ObservationsIn- - - - - -预测器数据观察维度的编码器属性
inumeratedInput.对象
预测数据观测维数的编码器属性('观察'的名称-值对参数预测),指定为一个inumeratedInput.对象。
控件创建编码器配置器时Learnercoderconfigurer功能,函数'观察'参数的名称-值对参数确定inumeratedInput.编码器属性:
价值- 默认值是您在创建编码器配置时使用的预测器数据观察维度,指定为“行”或“列”.如果您未指定'观察'创建编码器配置程序时,默认值是“行”.选择选项—always“内置”.此属性是只读的。BuiltInOptions-单元格数组“行”和“列”.此属性是只读的。iSononstant.—必须为真正的.可调谐性- - - - - -默认值是假如果您指定'观察','行'创建编码器配置程序时,以及真正的如果您指定'观察','列'.如果你设置了可调谐性到假,软件集价值到“行”.如果指定其他属性值可调谐性是假,软件集可调谐性到真正的.
NumOutputs- - - - - -输出数量预测
1(默认)|2
的生成的C/ c++代码中返回的输出参数的数量预测线性分类模型的函数,指定为1或2。
的输出参数预测是标签(预测类标签)和分数(分类得分),按此顺序。预测在生成的C / C ++代码中返回第一个代码n输出的预测函数,n是NumOutputs价值。
创建编码器配置程序后配置程序,您可以使用点表示法指定输出的数量。
配置。NumOutputs= 2;
的NumOutputs财产相当于“-nargout”编译器选项的codegen(MATLAB编码器).此选项指定代码生成的入口函数中的输出参数的数量。的目标函数Generatecode.生成两个入口点函数预测.M.和update.m为了预测和更新并为这两个入口点函数生成C/ c++代码。的指定值NumOutputs属性对应于入口点函数中的输出参数数预测.M..
数据类型:双倍的
更新争论
本节中列出的属性指定了编码器属性更新生成的代码中的函数参数。的更新函数接受训练过的模型和新的模型参数作为输入参数,并返回包含新参数的模型的更新版本。要启用更新生成代码中的参数,您需要在生成代码之前指定参数的编码器属性。使用一个LearnerCoderInput对象指定每个参数的编码器属性。默认属性值基于输入参数中的模型参数Mdl的Learnercoderconfigurer.
β- - - - - -线性预测器系数的编码器属性
LearnerCoderInput对象
线性预测系数的编码器属性(β的线性分类模型),指定为LearnerCoderInput对象。
属性的默认属性值LearnerCoderInput对象基于输入参数Mdl的Learnercoderconfigurer:
SizeVector—必须为[P 1], 在哪里p预测器的数量在吗Mdl.VariableDimensions—必须为[0 0],表示数组大小如规定固定SizeVector.数据类型- 这个值是'单身的'或“双”.默认数据类型与用于训练的训练数据的数据类型一致Mdl.可调谐性—必须为真正的.
偏见- - - - - -偏置术语的编码器属性
LearnerCoderInput对象
偏差项的编码器属性(偏见的线性分类模型),指定为LearnerCoderInput对象。
属性的默认属性值LearnerCoderInput对象基于输入参数Mdl的Learnercoderconfigurer:
SizeVector—必须为[1].VariableDimensions—必须为[0 0],表示数组大小如规定固定SizeVector.数据类型- 这个值是'单身的'或“双”.默认数据类型与用于训练的训练数据的数据类型一致Mdl.可调谐性—必须为真正的.
成本- - - - - -错误分类成本的编码属性
LearnerCoderInput对象
错误分类成本的编码者属性(成本的线性分类模型),指定为LearnerCoderInput对象。
属性的默认属性值LearnerCoderInput对象基于输入参数Mdl的Learnercoderconfigurer:
SizeVector—必须为[2].VariableDimensions—必须为[0 0],表示数组大小如规定固定SizeVector.数据类型- 这个值是'单身的'或“双”.默认数据类型与用于训练的训练数据的数据类型一致Mdl.可调谐性- 默认值是真正的.
之前- - - - - -先验概率的编码器属性
LearnerCoderInput对象
概率的编码器属性(之前的线性分类模型),指定为LearnerCoderInput对象。
属性的默认属性值LearnerCoderInput对象基于输入参数Mdl的Learnercoderconfigurer:
SizeVector—必须为[1 2].VariableDimensions—必须为[0 0],表示数组大小如规定固定SizeVector.数据类型- 这个值是'单身的'或“双”.默认数据类型与用于训练的训练数据的数据类型一致Mdl.可调谐性- 默认值是真正的.
其他配置选项
OutputFileName- - - - - -生成的C / C ++代码的文件名
'ClassificationLinearModel'(默认)|字符向量
生成的C/ c++代码的文件名,指定为字符向量。
的目标函数Generatecode.的ClassificeLcoderConfigurer.使用此文件名生成C/ c++代码。
文件名不能包含空格,因为在某些操作系统配置中,空格可能导致代码生成失败。此外,名称必须是有效的MATLAB函数名。
创建编码器配置程序后配置程序,您可以使用点表示法指定文件名。
配置。OutputFileName ='mymodel';
数据类型:char
详细的- - - - - -冗长的水平
真正的(逻辑1)(默认)|假(逻辑0)
详细级别,指定为真正的(逻辑1)或假(逻辑0)。详细级别控制命令行中通知消息的显示。
| 价值 | 描述 |
|---|---|
真正的(逻辑1) |
当您对参数的编码器属性的更改导致其他相关参数的更改发生更改时,软件显示通知消息。 |
假(逻辑0) |
该软件不显示通知消息。 |
要在生成的代码中启用更新计算机学习模型参数,您需要在生成代码之前配置参数的编码器属性。参数的编码器属性彼此依赖,因此软件将依赖项存储为配置约束。如果通过使用编码器配置器修改参数的编码器属性,并且修改需要随后改变其他从属参数来满足配置约束,则软件改变了从属参数的编码器属性。冗长级别确定软件是否显示出用于这些后续更改的通知消息。
创建编码器配置程序后配置程序,您可以使用点表示法修改详细级别。
configur.verbose = false;
数据类型:逻辑
代码生成自定义的选项
要自定义代码生成工作流程,请使用generateFiles函数和下面三个属性codegen(MATLAB编码器),而不是使用Generatecode.函数。
生成两个入门点函数文件(预测.M.和update.m),使用generateFiles函数,您可以根据代码生成工作流修改这些文件。例如,可以修改预测.M.文件以包含数据预处理,或者可以将这些入口点函数添加到另一个代码生成项目中。然后,您可以通过使用codegen(MATLAB编码器)函数和codegen适合于修改的入口点函数或代码生成项目的参数。使用本节中描述的三个属性作为起点来设置codegen参数。
CodeGenerationArguments- - - - - -codegen争论
单元阵列
此属性是只读的。
codegen(MATLAB编码器)参数,指定为单元格数组。
此属性使您能够自定义代码生成工作流。使用Generatecode.函数,如果您不需要自定义您的工作流。
而不是使用Generatecode.使用编码器配置器配置程序,您可以生成C / C ++代码,如下所示:
generateFiles(配置器)cgArgs = configuration . codegenerationarguments;codegen (cgArgs {}):
cgArgs因此之前调用codegen.
如果修改其他属性配置程序,软件更新CodeGenerationArguments相应的财产。
数据类型:细胞
PredictInputs- - - - - -的可调参数列表预测
单元阵列
此属性是只读的。
入口点函数的可调输入参数列表预测.M.对于代码生成,指定为单元数组。单元阵列包含另一个包括的单元阵列编码器.primitiveType.(MATLAB编码器)对象和编码器。常数(MATLAB编码器)对象。
如果修改编码器属性预测争论然后,软件相应地更新相应的对象。如果您指定了可调谐性属性假,然后软件从中删除相应的对象PredictInputs列表。
单元格数组PredictInputs相当于配置。CodeGenerationArguments {6}对于编码器配置程序配置程序.
数据类型:细胞
UpdateInputs- - - - - -的可调参数列表更新
结构的单元格数组,包括编码器.primitiveType.对象
此属性是只读的。
入口点函数的可调输入参数列表update.m对于代码生成,指定为包含的结构的单元格数组编码器.primitiveType.(MATLAB编码器)对象。每一个编码器.primitiveType.对象包括可调谐计算机学习模型参数的编码器属性。
如果使用编码器配置程序属性修改模型参数的编码器属性(更新争论属性),然后软件更新相应的编码器.primitiveType.相应的对象。如果您指定了可调谐性机器学习模型参数的属性为假,则软件删除相应的编码器.primitiveType.对象来自UpdateInputs列表。
结构在UpdateInputs相当于配置。CodeGenerationArguments {3}对于编码器配置程序配置程序.
数据类型:细胞
对象的功能
Generatecode. |
使用编码器配置器生成C/ c++代码 |
generateFiles |
生成马铃薯使用编码器配置器生成代码的文件 |
validatedUpdateInputs |
验证并提取机器学习模型参数进行更新 |
例子
使用编码器配置器生成代码
火车机器学习模型,然后为此生成代码预测和更新使用编码器配置器来函数模型。
加载电离层数据集,并培训二进制线性分类模型。通过转置的预测矩阵Xnew到FitClinear.,并使用'观察'的列的名称-值对参数指定Xnew对应观察。
负载电离层Xnew = X ';Mdl = fitclinear (Xnew Y'观察',“列”);
Mdl是A.ClassificationLinear对象。
为此创建一个编码器配置程序ClassificationLinear模型通过使用Learnercoderconfigurer.指定预测器数据Xnew,并使用'观察'名称 - 值对参数指定观察维度Xnew.的Learnercoderconfigurer函数使用这些输入参数配置相应的输入参数的编码器属性预测.
配置= learnerCoderConfigurer (Mdl Xnew,'观察',“列”)
配置= ClassificationLinearCoderConfigurer属性:更新输入:β:[1 x1 LearnerCoderInput]偏见:之前[1 x1 LearnerCoderInput]: [1 x1 LearnerCoderInput]成本:[1 x1 LearnerCoderInput]预测输入:X: [1 x1 LearnerCoderInput] ObservationsIn: [1 x1 EnumeratedInput]代码生成参数:NumOutputs: 1 OutputFileName:“ClassificationLinearModel”属性,方法
配置程序是A.ClassificeLcoderConfigurer.对象是一个编码器配置程序ClassificationLinear对象。
要生成C/ c++代码,您必须访问配置正确的C/ c++编译器。MATLAB编码器定位并使用一个受支持的、安装的编译器。金宝app您可以使用墨西哥人设置查看和更改默认编译器。有关详细信息,请参见改变默认的编译器.
为预测和更新线性分类模型的功能(Mdl).
generateCode(配置)
generateCode在输出文件夹中创建这些文件:米”、“预测。米”、“更新。米”、“ClassificationLinearModel。代码生成成功。
的Generatecode.函数完成这些操作:
生成生成代码所需的MATLAB文件,包括两个入口点函数
预测.M.和update.m为了预测和更新函数Mdl,分别。创建名为MEX函数
ClassificationLinearModel对于两个入口点函数。控件中创建MEX函数的代码
Codegen \ MEX \ ClassificationLEARMODEL文件夹。将MEX函数复制到当前文件夹。
显示的内容预测.M.,update.m,initialize.m文件,使用类型函数。
类型预测.M.
function varargout = predict(X,varargin) %#codegen % Autogenerated by MATLAB, 23-Feb-2021 19:17:19 [varargout{1:nargout}] = initialize('predict',X,varargin{:});结束
类型update.m
function update(varargin) %#codegen % Autogenerated by MATLAB, 23-Feb-2021 19:17:19 initialize('update',varargin{:});结束
类型initialize.m
函数[varargout] = initialize(命令,varargin)%#codegen%by matlab,23-feb-2021 19:17:19编码器.inline('始终')持久模型如果是isempty(模型)模型= loadlearnerforcoder('classificallymodel。垫');结束开关(命令)案例'更新'%更新结构字段:Beta%偏差%先前的%成本模型=更新(型号,varargin {:});案例'预测'%预测输入:x,观察x = varargin {1};如果nargin == 2 [varargout {1:nargout}] = predict(model,x);否则pvPairs = cell(1,nargin-2);对于i = 1:nargin-2 pvPair {1,i} = varargin {i + 1};结束[varargout {1:nargout}] = predict(model,x,pvpaess {:});结束结束
生成代码中线性分类模型的更新参数
使用部分数据集培训线性分类模型,并为模型创建编码器配置器。使用编码器配置器的属性来指定线性模型参数的编码器属性。使用编码器配置器的对象函数来生成C代码,该C代码预测新的预测器数据的标签。然后使用整个数据集重新培训模型,并在未重新生成代码的情况下更新生成代码中的参数。
火车模型
加载电离层数据集。该数据集有34个预测器和351个雷达返回的二进制响应,或坏(“b”)或好('G').用一半的观测数据训练一个二元线性分类模型。转换预测数据,并使用'观察'的列的名称-值对参数指定XTrain对应观察。
负载电离层RNG('默认')重复性的%n =长度(Y);c = cvpartition (Y,'坚持', 0.5);idxTrain =培训(c, 1);XTrain = X (idxTrain:) ';YTrain = Y (idxTrain);Mdl = fitclinear (XTrain YTrain,'观察',“列”);
Mdl是A.ClassificationLinear对象。
创建编码器配置程序
为此创建一个编码器配置程序ClassificationLinear模型通过使用Learnercoderconfigurer.指定预测器数据XTrain,并使用'观察'名称 - 值对参数指定观察维度XTrain.的Learnercoderconfigurer函数使用这些输入参数配置相应的输入参数的编码器属性预测.另外,将输出的数量设置为2,以便生成的代码返回预测的标签和分数。
configurer = LearnerCoderConfigurer(MDL,XTrain,'观察',“列”,“NumOutputs”2);
配置程序是A.ClassificeLcoderConfigurer.对象是一个编码器配置程序ClassificationLinear对象。
指定参数的编码器属性
指定线性分类模型参数的编码器属性,以便您可以在重新训练模型后更新生成代码中的参数。此示例指定要传递给生成代码的预测器数据的编码器属性。
属性的编码器属性X的属性配置程序这样生成的代码就可以接受任意数量的观察。修改SizeVector和VariableDimensions属性。的SizeVector属性指定预测器数据大小的上限,以及VariableDimensions属性指定预测器数据的每个维度是具有可变大小还是固定大小。
configuration . x . sizevector = [34 Inf];configurer.X.VariableDimensions
ans =1 x2逻辑阵列0 1
第一个维度的大小是预测变量的数量。对于机器学习模型,这个值必须是固定的。由于预测器数据包含34个预测器,因此SizeVector属性必须是34和值的值VariableDimensions属性必须0.
第二个维度的大小是观察的次数。的值SizeVector属性来INF.导致软件修改VariableDimensions属性来1.换句话说,大小的上限是INF.大小是可变的,这意味着预测器数据可以具有任何数量的观察。如果您不知道生成代码时的观察次数,则此规范很方便。
尺寸的顺序SizeVector和VariableDimensions的编码属性ObservationsIn.
配置。ObservationsIn
ANS = eNumerateDupput与属性:value:'列'SelectedOption:'内置'构建选项:{'行'列'} iSononstant:1可调性:1
当价值属性的ObservationsIn属性是“列”,第一个维度SizeVector和VariableDimensions的属性X对应于预测数,第二个维度对应于观测数。当价值属性ObservationsIn是“行”,切换尺寸的顺序。
生成代码
要生成C/ c++代码,您必须访问配置正确的C/ c++编译器。MATLAB编码器定位并使用一个受支持的、安装的编译器。金宝app您可以使用墨西哥人设置查看和更改默认编译器。有关详细信息,请参见改变默认的编译器.
为预测和更新线性分类模型的功能(Mdl).
generateCode(配置)
generateCode在输出文件夹中创建这些文件:米”、“预测。米”、“更新。米”、“ClassificationLinearModel。代码生成成功。
的Generatecode.函数完成这些操作:
生成生成代码所需的MATLAB文件,包括两个入口点函数
预测.M.和update.m为了预测和更新函数Mdl,分别。创建名为MEX函数
ClassificationLinearModel对于两个入口点函数。控件中创建MEX函数的代码
Codegen \ MEX \ ClassificationLEARMODEL文件夹。将MEX函数复制到当前文件夹。
验证生成的代码
通过一些预测数据来验证是否预测的函数Mdl和预测函数中返回相同的标签。要在具有多个入口点的MEX函数中调用一个入门点函数,请将函数名称指定为第一个输入参数。
(标签,分数)=预测(Mdl XTrain,'观察',“列”);[label_mex, score_mex] = ClassificationLinearModel (“预测”XTrain,'观察',“列”);
相比标签和label_mex通过使用isequal.
isequal(标签,label_mex)
ans =逻辑1
isequal返回逻辑1(真正的),如果所有输入相等。比较证实了预测的函数Mdl和预测函数中返回相同的标签。
相比分数和score_mex.
马克斯(abs (score-score_mex), [],“所有”)
ans = 0.
一般来说,score_mex可能包括舍入差异与分数.在本例中,比较证实了这一点分数和score_mex是平等的。
培训模型和生成代码中的更新参数
使用整个数据集重新训练模型。
retrainedMdl = fitclinear (X, Y)'观察',“列”);
使用提取要更新的参数validatedUpdateInputs.该函数检测修改后的模型参数retrainedMdl并验证修改后的参数值是否满足参数的编码器属性。
params = validatedUpdateInputs(配置、retrainedMdl);
更新生成代码中的参数。
分类learmodel('更新',params)
验证生成的代码
的输出比较预测的函数retrainedMdl和预测函数。
[标签,分数] =预测(检索MDL,X','观察',“列”);[label_mex, score_mex] = ClassificationLinearModel (“预测”,X','观察',“列”);isequal(标签,label_mex)
ans =逻辑1
马克斯(abs (score-score_mex), [],“所有”)
ans = 0.
对比证实了标签和label_mex等于,得分值相等。
更多关于
LearnerCoderInput目的
编码器配置器使用一个LearnerCoderInput对象指定编码器属性预测和更新输入参数。
一个LearnerCoderInput对象具有以下属性以指定生成的代码中的输入参数数组的属性。
| 属性名称 | 描述 |
|---|---|
SizeVector |
对应的数组大小 数组大小的上界,如果对应 |
VariableDimensions |
指示阵列的每个维度是否具有可变大小或固定大小的指示器,指定为
|
数据类型 |
数组的数据类型 |
可调谐性 |
指示是否的指示符 如果指定其他属性值 |
在创建编码器配置器之后,您可以使用点表示法修改编码器属性。例如,指定偏差项的数据类型偏见编码器配置器的配置程序:
configurer.bias.datatype =.'单身的';
详细的) 作为真正的(默认),然后软件在修改机器学习模型参数的编码器属性时显示通知消息,并且修改改变了其他相关参数的编码器属性。
inumeratedInput.目的
编码器配置程序使用inumeratedInput.对象指定编码器属性预测具有有限组可用值的输入参数。
一个inumeratedInput.对象具有以下属性以指定生成的代码中的输入参数数组的属性。
| 属性名称 | 描述 |
|---|---|
价值 |
的价值
默认值 |
选择选项 |
所选选项的状态,指定为
此属性是只读的。 |
BuiltInOptions |
对应的可用字符向量的列表 此属性是只读的。 |
iSononstant. |
指示符,指定数组值是否为编译时常量( 如果将此值设置为 |
可调谐性 |
指示是否的指示符 如果指定其他属性值 |
在创建编码器配置器之后,您可以使用点表示法修改编码器属性。例如,指定的编码器属性ObservationsIn编码器配置器的配置程序:
configurer.observations.value =.“列”;
matlab命令
你点击一个链接对应于这个MATLAB命令:
在MATLAB命令窗口中输入它来运行命令。Web浏览器不支持MATLAB命令。金宝app
你也可以从以下列表中选择一个网站:
如何获得最佳网站性能
选择中国网站(中文或英文)以获得最佳网站性能。其他MathWorks国家站点没有针对您所在位置的访问进行优化。
