主要内容
回归的TreecoderConfigurer.
回归二进制决策树模型的编码器配置程序
描述
一个回归的TreecoderConfigurer.对象是用于回归的二叉决策树模型的编码器配置器(回归植物要么Compactregressiontree.)。
编码器配置器提供了方便的特性来配置代码生成选项、生成C/ c++代码以及更新生成代码中的模型参数。
配置代码生成选项,并通过使用对象属性为树模型参数指定编码器属性。
为此生成C / C ++代码
预测和更新使用回归树模型的功能Generatecode..生成C / C ++代码需要马铃薯®编码器™.更新生成的C/ c++代码中的模型参数,而不需要重新生成代码。当您使用新数据或设置重新训练树模型时,该特性减少了重新生成、重新部署和重新验证C/ c++代码所需的工作。在更新模型参数之前,请使用
验证updateInpuls.验证和提取要更新的模型参数。
此流程图显示使用编码器配置程序的代码生成工作流程。
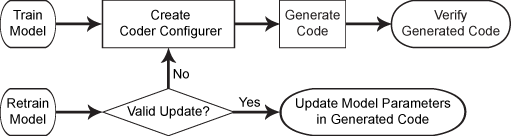
有关回归树模型的代码生成使用说明和限制,请参阅Compactregressiontree.,预测, 和更新.
创造
通过使用培训回归树模型菲特里,使用使用创建模型的编码器配置器Learnercoderconfigurer.属性的编码器属性预测和更新论点。然后,使用Generatecode.根据指定的编码器属性生成C/ c++代码。
性质
对象功能
Generatecode. |
使用编码器配置器生成C/ c++代码 |
generateFiles |
产生马铃薯使用编码器配置器生成代码的文件 |
验证updateInpuls. |
验证和提取机器学习模型参数更新 |
例子
更多关于
介绍了R2019b
您还可以从以下列表中选择一个网站:
