主要内容
clusterdata.
从数据构建聚类
描述
例子
从样本数据中找到有限数量的聚类
使用两种不同的方法查找并在随机生成的数据集中可视化三个集群:
指定值的值
截止输入参数。指定值的值
'maxclust'名称-值对的论点。
创建由三个标准均匀分布的随机生成的数据组成的示例数据集。
RNG('默认');重复性的%X =[画廊(“uniformdata”,[10 3],12);......画廊(“uniformdata”3 [10] 13) + 1.2;......画廊(“uniformdata”,[10 3],14)+2.5];y = [α(10,1); 2 *(10,1)); 3 *(10,1))];%的实际类
创建数据的散点图。
散射3(x(:,1),x(:,2),x(:,3),100,y,“填充”) 标题('三个集群中的随机生成的数据);
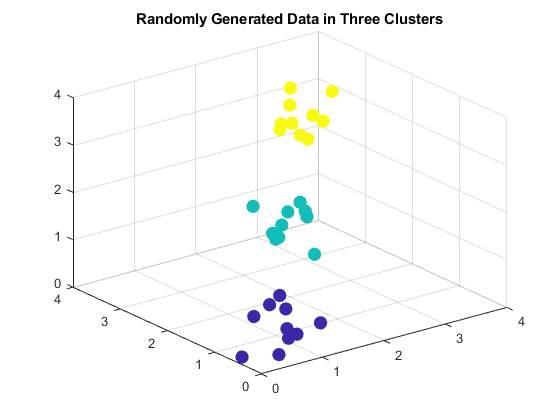
通过指定值3,在数据中找到最多三个群集截止输入参数。
t1 = clusterdata(x,3);
因为截止大于2,clusterdata.解释截止作为最大群集数。
用生成的群集分配绘制数据。
scatter3 (X (: 1) X (:, 2), X(:, 3), 100年,T1,“填充”) 标题('聚类结果');

通过指定值3来找到最多三个集群'maxclust'名称-值对的论点。
t2 = clusterdata(x,“Maxclust”3);
用生成的群集分配绘制数据。
scatter3 (X (: 1) X (:, 2), X(:, 3), 100年,T2,“填充”) 标题('聚类结果');
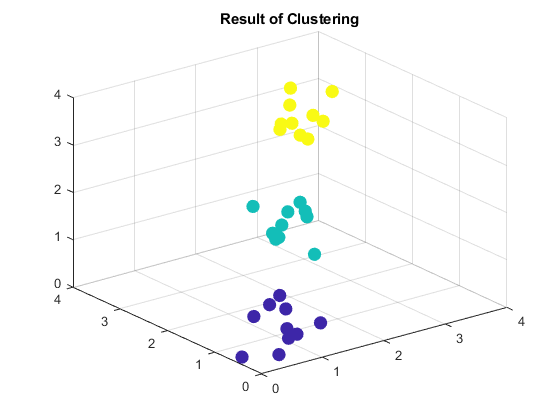
使用两种方法,clusterdata.识别数据中的三个不同群集。
创建和群集分层树
创建分层群集树并在一步中查找群集。使用3-D散点图可视化簇。
创建一个由标准均匀分布生成的样本数据的20,000 × 3矩阵。
RNG('默认');重复性的%x =兰特(20000,3);
方法创建的分层集群树中最多可以找到四个集群ward联动方法。指定“SaveMemory”作为“上”在不计算距离矩阵的情况下构造簇。否则,如果您的机器没有足够的内存以保持距离矩阵,则可以收到内存up-Memory错误。
t = clusterdata(x,'连锁',“病房”,“SaveMemory”,“上”,“Maxclust”4);
绘制数据以不同颜色显示的每个群集。
散射3(x(:,1),x(:,2),x(:,3),10,t)

clusterdata.识别数据中的四个群集。
输入参数
输出参数
提示
算法
在R2006A之前介绍
您还可以从以下列表中选择一个网站:
