威彻斯
K.聚类则
语法
描述
idx= kemans(X那K.)X进入K.群集,并返回一个N1向量(idx)包含每个观测值的聚类索引X对应于点,列对应于变量。
默认情况下,威彻斯使用平方欧几里德距离度量和K.-means ++算法用于集群中心初始化。
例子
训练K.——聚类算法
集群的数据使用K.-表示集群,然后绘制集群区域。
加载Fisher的虹膜数据集。使用花瓣长度和宽度作为预测值。
负载fisheririsX =量(:,3:4);图;情节(X (: 1) X (:, 2),“k *’那“MarkerSize”5);标题'fisher'的虹膜数据';包含“花瓣长度(厘米)”;ylabel.“花瓣宽度(厘米)”;
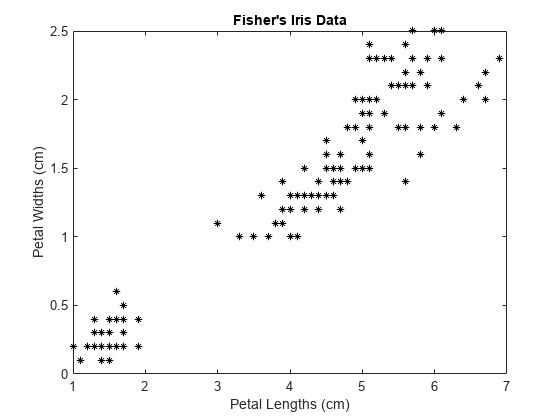
较大的聚类似乎分成了一个低方差区域和一个高方差区域。这可能表明较大的星团是两个重叠的星团。
对数据进行聚类。具体说明K.=3簇。
rng (1);重复性的%[idx C] = kmeans (X, 3);
idx中预测的聚类指数向量是否与观测值相对应X。C是包含最终质心位置的3×2矩阵。
用威彻斯计算每个质心到网格上各点的距离。为此,请传递质心(C)和网格上的点威彻斯并实现算法的一个迭代。
x1=min(X(:,1)):0.01:max(X(:,1));x2=min(X(:,2)):0.01:max(X(:,2));[x1G,x2G]=meshgrid(x1,x2);XGrid=[x1G(:),x2G(:)];%在绘图上定义精细栅格idx2Region = kmeans (XGrid 3“麦克斯特”,1,'开始',C);
警告:在1次迭代中收敛失败。
%将网格中的每个节点分配到最近的质心
威彻斯显示一个警告,说明算法没有收敛,这是您应该预料到的,因为软件只实现了一个迭代。
绘制集群区域。
图;gscatter (XGrid (: 1) XGrid (:, 2), idx2Region,...[0,0.75,0.75; 0.75,0.75; 0.75,0.75,0],'..');持有在…上;绘图(X(:,1),X(:,2),“k *’那“MarkerSize”5);标题'fisher'的虹膜数据';包含“花瓣长度(厘米)”;ylabel.“花瓣宽度(厘米)”; 传奇(“区域1”那“区域2”那“区域3”那'数据'那“位置”那‘东南’);持有关;

将数据划分为两个集群
随机生成样本数据。
rng默认的;重复性的%X = [randn(100 2) * 0.75 +(100 2)的;randn(100 2) * 0.5的(100 2)];图;情节(X (: 1) X (:, 2),'。'); 标题随机生成的数据的;

数据中似乎有两组。
将数据分组为两个群集,并选择最佳排列在五种初始化中。显示最终输出。
opts=statset(“显示”那“最后一次”);[idx C] = kmeans (X, 2,“距离”那“cityblock”那...“复制”,5,“选项”、选择);
复制1,3次迭代,距离总和=201.533。复制2,5次迭代,距离总和=201.533。复制3,3次迭代,距离总和=201.533。复制4,3次迭代,距离总和=201.533。复制5,2次迭代,距离总和=201.533。最佳距离总和=201.533
默认情况下,软件使用K.-意思是++。
绘制集群和集群质心。
图;曲线图(X(idx==1,1),X(idx==1,2),“r.”那“MarkerSize”, 12)在…上图(X(idx==2,1),X(idx==2,2),'b。'那“MarkerSize”12)情节(C (: 1), C (:, 2),“kx”那...“MarkerSize”15岁的“线宽”,3)传奇(“集群1”那《集群2》那'质心'那...“位置”那“西北”)头衔“集群分配和质心”持有关

您可以通过传递来确定集群的分离程度idx来轮廓。
使用并行计算的集群数据
群集大数据集可能需要时间,特别是如果使用在线更新(默认设置)。如果您有一个并行计算工具箱™许可证,请设置并行计算的选项,然后威彻斯并行地运行每个集群任务(或复制)。而且,如果复制> 1,然后并行计算降低收敛时间。
从高斯混合模型随机生成一个大数据集。
mu = bsxfun(@次,那些(20,30),(1:20)');%高斯混合均值rn30 = randn(30、30);σ= rn30 ' * rn30;%对称正定协方差mdl = Gmdistribution(mu,sigma);定义高斯混合分布rng (1);重复性的%x =随机(MDL,10000);
Mdl是一个30-dimensionalgm分布模型有20个组件。X是一个10000 x 30的数据矩阵,由Mdl。
指定并行计算的选项。
流= RandStream (“mlfg6331_64”);%随机数流选项= statset(“使用并行”,1,“UseSubstreams”,1,...“流”,溪流);
输入参数“mlfg6331_64”属于RandStream指定使用乘法滞后的Fibonacci生成器算法。选项是一个结构数组,其中包含指定用于控制估计的选项的字段。
使用K.-这意味着集群。指定有K.=数据中20个簇,增加迭代次数。通常,目标函数包含局部最小值。指定10个复制以帮助查找更低的本地最小值。
抽搐;%启动秒表计时器(sumd idx, C, D) = kmeans (X, 20,“选项”,选项,“麦克斯特”,10000,...“显示”那“最后一次”那“复制”,10);
启动并行池(parpool)使用“本地”配置文件…连接到6名工人。复制5次,72次迭代,总距离=7.73161e+06。复制1次,64次迭代,总距离=7.72988e+06。复制3次,68次迭代,总距离=7.72576e+06。复制4次,84次迭代,总距离=7.72696e+06。复制6次,82次迭代,至距离总和=7.73006e+06。重复7次,40次迭代,距离总和=7.73451e+06。重复2194次迭代,距离总和=7.72953e+06。重复9105次迭代,距离总和=7.72064e+06。重复10125次迭代,距离总和=7.72816e+06。重复8次,70次迭代,距离总和=7.72816e+06距离=7.73188e+06。最佳距离总和=7.72064e+06
toc%终止秒表计时器
运行时间为61.915955秒。
命令窗口表示六个工作人员可用。工作人员的数量可能会有所不同。命令窗口显示每个复制的迭代次数和终端目标函数值。输出参数包含复制9的结果,因为它具有最低的距离总和。
将新数据分配给现有集群并生成C/C++代码
威彻斯表演K.-意味着将数据划分为K.集群。将新数据集设置为群集后,可以使用创建包含现有数据和新数据的新群集威彻斯。这威彻斯函数支持C / C金宝app ++代码生成,因此您可以生成接受培训数据并返回群集结果的代码,然后将代码部署到设备。在此工作流程中,您必须通过培训数据,这可以具有相当大的尺寸。要将内存保存在设备上,您可以通过使用分离培训和预测威彻斯和PDIST2., 分别。
用威彻斯在MATLAB®中创建群集并使用PDIST2.在生成的代码中,将新数据分配给现有集群。对于代码生成,定义一个入口点函数,该函数接受簇质心位置和新数据集,并返回最近簇的索引。然后,为入口点函数生成代码。
生成C/ c++代码需要MATLAB®Coder™。
表演K.聚类则
使用三种分布生成训练数据集。
RNG(“默认”)重复性的%X = [randn(100 2) * 0.75 +(100 2)的;Randn(100,2)* 0.5-(100,2);Randn(100,2)* 0.75];
通过使用将培训数据分为三个集群威彻斯。
[idx C] = kmeans (X, 3);
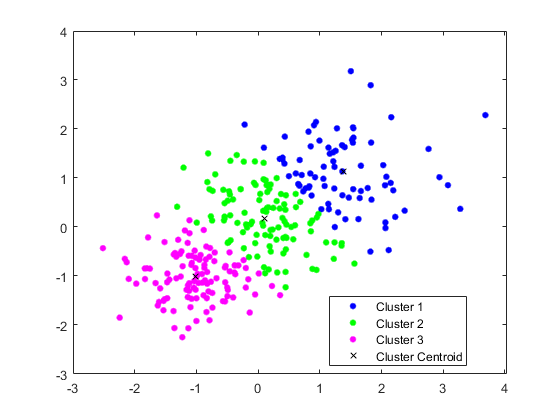
绘制集群和集群质心。
图g箭头(x(:,1),x(:,2),IDX,'BGM')举行在…上绘图(C(:,1),c(:,2),“kx”)传说(“集群1”那《集群2》那“集群3”那聚类质心的)
将新数据分配给现有群集
生成测试数据集。
Xtest=[randn(10,2)*0.75+一(10,2);randn(10,2)*0.5-一(10,2);randn(10,2)*0.75];
使用现有聚类对测试数据集进行分类。使用PDIST2.。
[~,idx_检验]=pdist2(C,Xtest,“欧几里得”那“最小”,1);
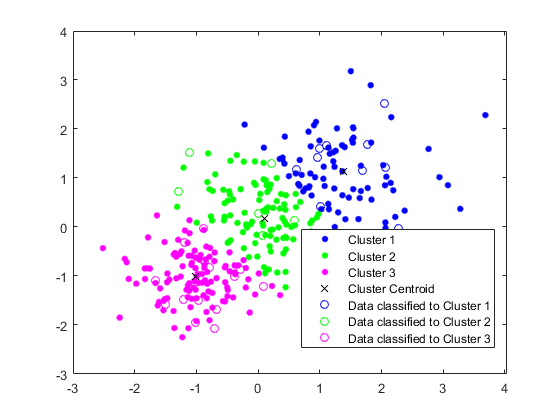
绘制测试数据并使用测试数据标记idx_test.利用gscatter。
gscatter(Xtest(:,1),Xtest(:,2),idx_测试,'BGM'那“哦”)传说(“集群1”那《集群2》那“集群3”那聚类质心的那...“数据分类为第一组”那“数据分类为第二组”那...“数据分类为第3组”)
生成代码
生成C代码,将新数据分配给现有的集群。请注意,生成C/ c++代码需要MATLAB®Coder™。
定义一个名为findnearestcentroid.接受质心位置和新数据,然后通过使用找到最近的集群PDIST2.。
添加% # codegen编译器指令(或Pragma)到函数签名后的入门点函数,表示您打算为Matlab算法生成代码。添加此指令指示MATLAB代码分析仪帮助您诊断和修复在代码生成期间会导致错误的违规。
类型findnearestcentroid.%显示findNearestCentroid.m的内容
函数idx=findNearestCentroid(C,X)%#codegen[~,idx]=pdist2(C,X,'euclidean','minimable',1);%找到最近的质心
注意:如果你点击这个页面右上角的按钮,并在MATLAB®中打开这个示例,那么MATLAB®将打开示例文件夹。这个文件夹包括入口点函数文件。
通过使用生成代码codegen(MATLAB编码器)。因为C和c++都是静态类型语言,所以必须在编译时确定入口点函数中所有变量的属性。的输入的数据类型和数组大小findnearestcentroid.,通过使用- args.选项有关详细信息,请参阅为代码生成指定可变大小参数。
codegenfindnearestcentroid.- args.{C, Xtest}
代码生成成功。
codegen生成MEX函数findNearestCentroid_mex具有平台依赖的扩展。
验证生成的代码。
myIndx = findNearestCentroid (C, Xtest);myIndex_mex = findNearestCentroid_mex (C, Xtest);verifyMEX = isequal (idx_test myIndx myIndex_mex)
验证ex =.逻辑1
是平等的返回逻辑1(真的),这意味着所有的输入都是相等的。比较证实了PDIST2.函数,findnearestcentroid.函数和MEX函数返回相同的索引。
您还可以使用GPU编码器生成优化的CUDA®代码™.
cfg = coder.gpuconfig('mex');codegen-配置CFG.findnearestcentroid.- args.{C, Xtest}
有关代码生成的详细信息,请参见通用代码生成工作流。有关GPU编码器的更多信息,请参见开始使用GPU编码器(GPU编码器)和金宝app支持功能(GPU编码器)。
输入参数
输出参数
更多关于
算法
威彻斯采用两阶段迭代算法最小化点到质心距离的和,求和K.集群。第一阶段使用批量更新,每次迭代包括将点全部重新分配到它们最近的簇心,然后重新计算簇心。这个阶段有时不收敛于局部最小解。也就是说,在数据的分区中,将任何一个点移动到不同的集群中,都会增加距离的总和。这对于小数据集来说更有可能。批处理阶段是快速的,但可能只近似于作为第二阶段起点的解决方案。
第二阶段使用在线更新如果执行此操作,则单独重新分配点,从而减少距离之和,并且在每个重新分配后重新计算群集质心。在此阶段的每次迭代都是由所有点传递的。该阶段会聚到局部最小值,尽管可能存在其他局部最小值,但距离较低。通常,通过详尽的起点选择来解决全局最小值,但是使用随机起点的几个复制通常会导致作为全局最小的解决方案。
如果
复制=R.> 1,开始是加(默认值),然后软件选择R.根据的可能不同的种子K.-means ++算法。如果您启用
使用并行选项选项和复制>1,然后每个辅助进程并行选择种子和簇。
参考文献
[1] Arthur,David和Sergi Vassilvitskii.“K-means++:小心播种的优势。”SODA'07:第十八届ACM-SIAM年度离散算法研讨会论文集。2007年,页1027 - 1035。
[2] 《PCM中的最小二乘量化》IEEE信息论学报。1982年第28卷,129-137页。
g.a. F. Seber多变量的观察。John Wiley & Sons, Inc., 1984。
[4] Spath, H。聚类解剖和分析:理论,Fortran计划,例子。由J. Goldschmidt翻译。纽约:Halsted Press,1985年。
扩展功能
你也可以从以下列表中选择一个网站:
