kmedoids
k-medoids集群
语法
描述
idx= kmedoids (X,k)X成k,并返回一个n1的向量idx包含每个观测值的聚类指标。行X对应点,列对应变量。默认情况下,kmedoids使用平方欧几里得距离度量和k——+ +算法用于选择初始集群中间位置。
例子
将数据分成两组
随机生成数据。
rng (“默认”);%用于再现性X = [randn(100,2)*0.75+ones(100,2);randn(100 2) * 0.55的(100 2)];图;情节(X (: 1) X (:, 2),“。”);标题(“随机生成的数据”);
将数据分组到两个集群kmedoids.使用cityblock距离度量。
Opts = statset(“显示”,“通路”);[idx,C,sumd,d,midx,info] = kmedoids(X,2,“距离”,“cityblock”,“选项”、选择);
rep iter sum 1 1 209.856 1 2 209.856最佳距离总和= 209.856
信息是一个结构体,其中包含关于如何执行算法的信息。例如,bestReplicate字段指示用于生成最终解决方案的复制。在本例中,使用了复制数1,因为默认算法的默认复制数为1,即帕姆在这种情况下。
信息
信息=带字段的结构:算法:“pam”开始:“plus”距离:“cityblock”迭代:2 bestreplduplicate: 1
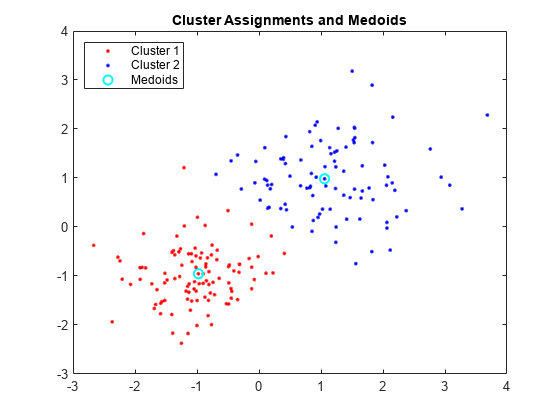
画出星团和星团中圆。
图;情节(X (idx = = 1,1) X (idx = = 1、2),“r”。,“MarkerSize”, 7)在情节(X (idx = = 2, 1), X (idx = = 2, 2),“b”。,“MarkerSize”7)情节(C (: 1), C (:, 2),“有限公司”,...“MarkerSize”7“线宽”传说,1.5)(“集群1”,《集群2》,“Medoids”,...“位置”,“西北”);标题(“集群分配和中位数”);持有从
使用k-Medoids的聚类分类数据
本例使用“Mushroom”数据集[3][4][5][6][7]来自UCI机器学习档案[7],详见http://archive.ics.uci.edu/ml/datasets/Mushroom。数据集包括22个预测因子,用于8124个不同蘑菇的观察。预测器是分类数据类型。例如,帽形是根据的特征进行分类的“b”用于钟形帽和“c”为锥形。蘑菇的颜色也有分类的特点“n”对于棕色,和“p”为粉红色。该数据集还包括每种蘑菇的可食用或有毒的分类。
由于蘑菇数据集的特征是分类的,因此不可能定义几个数据点的平均值,因此被广泛使用k-means聚类算法无法有意义地应用于该数据集。k-medoids是将数据划分为k不同的集群,通过寻找最小化数据中点和它们最近的中点之间的差异之和的中点。
一个集合的中位数是该集合中与其他集合成员的平均差异最小的成员。相似度可以定义为不允许计算平均值的许多类型的数据,允许k-medoids用于更广泛的问题比k则。
使用k-medoids,这个例子根据提供的预测器将蘑菇分为两组。然后,它探讨了这些集群和蘑菇的分类之间的关系,如可食用或有毒。
这个例子假设您已经下载了“Mushroom”数据集[3][4][5][6][7]从UCI数据库(http://archive.ics.uci.edu/ml/machine-learning-databases/mushroom/),并将其保存到当前目录中,作为一个名为agaricus-lepiota.txt的文本文件。数据中没有列标头,所以readtable使用默认变量名。
清晰的所有数据=可读数据(“agaricus-lepiota.txt”,“ReadVariableNames”、假);
展示前5个蘑菇的前几个特征。
数据(1:5,1:10)
ans = Var1 Var2 Var3 Var4 Var5 Var6 Var7 Var8 Var9 Var10 ____ ____ ____ ____ ____ ____ ____ ____ ____ _____ ' p ' ' x ' s ' ' n ' ' t ' p ' f ' c ' ' n ' k ' ' e ' x ' s ' y ' ' t ' ' ' ' f ' c ' ' b ' k ' ' e ' b ' s ' w ' ' t ' l ' f ' c ' ' b ' n ' p ' x ' y ' w ' ' t ' p ' f ' c ' ' n ' n ' ' e ' x ' s ' g ' ' f ' n ' f ' w ' ' b ' k '
提取第一列,标记数据为食用组和有毒组。然后删除该列。
Labels = data(:,1);标签= categorical(标签{:,:});Data (:,1) = [];
存储预测器(特性)的名称,在http://archive.ics.uci.edu/ml/machine-learning-databases/mushroom/agaricus-lepiota.names中有描述。
VarNames = {“cap_shape”“cap_surface”“cap_color”“淤青”“气味”...“gill_attachment”“gill_spacing”“gill_size”“gill_color”...“stalk_shape”“stalk_root”“stalk_surface_above_ring”...“stalk_surface_below_ring”“stalk_color_above_ring”...“stalk_color_below_ring”“veil_type”“veil_color”“ring_number”....“ring_type”“spore_print_color”“人口”“栖息地”};
设置变量名。
data.Properties.VariableNames = VarNames;
总共有2480个缺失值,表示为“?”.
sum (char(数据{:,:})= =“?”)
Ans = 2480
根据对数据集的检查及其描述,缺失的值只属于第11个变量(stalk_root).从表中删除列。
Data (:,11) = [];
kmedoids只接受数值数据。您需要将您拥有的类别转换为数字类型。用于定义数据不相似度的距离函数将基于分类数据的双重表示。
Cats = categorical(data{:,:});数据=双(猫);
kmedoids可以使用pdist2支持的任何距离度量来进行集群。金宝app对于本例,您将使用汉明距离对数据进行聚类,因为这是一个适用于分类数据的距离度量,如下所示。两个向量之间的汉明距离是不同向量分量的百分比。例如,考虑这两个向量。
V1 = [1 0 2 1];
V2 = [1 1 2 1];
它们在第一,三,四坐标上相等。由于4个坐标中的1个不同,这两个向量之间的汉明距离是。25。
你可以使用这个函数pdist2测量第一行和第二行数据之间的汉明距离,数值表示分类蘑菇数据。值。2857意味着蘑菇的21个特征中有6个不同。
: pdist2(数据(1),数据(2:)“汉明”)
Ans = 0.2857
在本例中,您将根据特征将蘑菇数据聚类为两个聚类,以查看聚类是否对应于可食性。的kmedoids函数保证收敛到聚类准则的局部最小值;然而,这可能不是这个问题的全局最小值。类对该问题进行几次聚类是个好主意“复制”参数。当“复制”设置为一个值,n,大于1,则运行k-medoids算法n,并返回最好的结果。
运行kmedoids要根据汉明距离将数据聚类为2个聚类,并返回3个重复的最佳结果,您可以运行以下命令。
rng (“默认”);%用于再现性[IDX, C, SUMD, D, MIDX, INFO] = kmedoids(data,2,“距离”,“汉明”,“复制”3);
让我们假设预测的第一组蘑菇是有毒的,第二组蘑菇都是可食用的。为了确定聚类结果的性能,根据已知标签,计算组1中有多少蘑菇确实有毒,组2中有多少蘑菇是可食用的。换句话说,计算假阳性、假阴性,以及真阳性和真阴性的数量。
构造一个混淆矩阵(或匹配矩阵),其中对角线元素分别表示真阳性和真阴性的数量。非对角线元素分别表示假阴性和假阳性。为方便起见,请使用confusionmat函数,计算已知标签和预测标签的混淆矩阵。中获取预测的标签信息IDX变量。IDX每个数据点包含值1和2,分别表示有毒组和可食用组。
predLabels =标签;为预测的标签初始化一个向量。predLabels(IDX==1) = category ({“p”});指定第1组是有毒的。predLabels(IDX==2) = categorical({“e”});指定第2组为可食用。confMatrix = confemat (labels,predLabels)
confMatrix = 4176 32 816 3100
在4208个食用菌中,4176个被正确预测为第2组(食用组),32个被错误预测为第1组(有毒组)。同样,在3916种有毒蘑菇中,有3100种被正确预测为第1组(有毒组),816种被错误预测为第2组(可食用组)。
给出这个混淆矩阵,计算准确率,这是真实结果(真阳性和真阴性)与整体数据的比例,以及精度,这是真实阳性结果与所有阳性结果(真阳性和假阳性)的比例。
精度= (confMatrix(1,1)+confMatrix(2,2))/(sum(sum(confMatrix)))
准确度= 0.8956
precision = confMatrix(1,1) / (confMatrix(1,1)+confMatrix(2,1))
精度= 0.8365
结果表明,将k-medoids算法应用于蘑菇的分类特征,可以得到与可食性相关的聚类。
输入参数
输出参数
更多关于
参考文献
[1]考夫曼,L.和卢梭,P. J.(2009)。在数据中寻找组:聚类分析导论。新泽西州霍博肯:约翰·威利父子公司
[2] Park H-S和Jun C-H。(2009)。一种简单快速的k - meddoids聚类算法。专家系统与应用。36,3336-3341。
[3] Schlimmer, j.s(1987)。通过表征调整获得概念(技术报告87-19)。加州大学欧文分校信息与计算机科学系博士论文。
[4] Iba, W。,Wogulis,J., and Langley,P. (1988). Trading off Simplicity and Coverage in Incremental Concept Learning. In Proceedings of the 5th International Conference on Machine Learning, 73-79. Ann Arbor, Michigan: Morgan Kaufmann.
杜赫W, a.r.,和Grabczewski, K.(1996)使用反向传播网络从训练数据中提取逻辑规则。第1届软计算在线研讨会,19-30,第25-30页。
杜赫,W., Adamczak, R., Grabczewski, K.,石川,M.和上田,H.(1997)。利用约束反向传播网络提取清晰逻辑规则-两种新方法的比较。欧洲人工神经网络研讨会(ESANN'97),布鲁日,比利时16-18。
[7]巴赫,K.和利希曼,M.(2013)。UCI机器学习知识库[http://archive.ics.uci.edu/ml]。加州欧文市:加州大学信息与计算机科学学院。
扩展功能
另请参阅
您也可以从以下列表中选择一个网站:
