层次聚类
分层群集介绍
分层集群通过创建集群树或在不同规模上对数据进行分组系统树图.树不是单一的群集,而是一个多级层次结构,其中一个级别的群集在下一级别加入群集。这允许您决定最适合您应用程序的群集的级别或比例。功能clusterdata金宝app支持群集聚类,并为您执行所有必要的步骤。它包含了这一点pdist,联动,簇函数,您可以单独使用这些函数进行更详细的分析。这个系统树图函数绘制集群树。
算法描述
使用统计和机器学习工具箱对数据集执行聚集层次聚类分析™ 功能,请按照以下步骤操作:
在数据集中找到每对对象之间的相似性或不相似性。在这一步中,你计算距离对象之间使用
pdist函数。这个pdist功能支持计算此测量金宝app的许多不同方式。看到相似的措施为更多的信息。将对象分组到一个二元的分层集群树中。在此步骤中,将使用
联动函数。这个联动函数使用步骤1中生成的距离信息来确定对象彼此之间的接近程度。当对象配对成二进制簇时,新形成的簇被分组成更大的簇,直到形成层次树。看到联系为更多的信息。确定将分层树切成群集的位置。在此步骤中,使用
簇函数将层次树底部的分支修剪掉,并将每个修剪下的所有对象分配给单个集群。这将创建一个数据分区。这个簇函数可以通过检测层次树中的自然分组或在任意点切断层次树来创建这些簇。
以下部分提供有关这些步骤中的每一个的更多信息。
注
功能clusterdata为您执行所有必要的步骤。您不需要执行pdist,联动, 或者簇单独的功能。
相似的措施
您使用pdist函数来计算数据集中每对对象之间的距离。的数据集M对象,有M*(M– 1)/2数据集中的对。该计算的结果通常称为距离或异化矩阵。
有很多方法来计算该距离信息。默认情况下,pdist函数计算物体之间的欧氏距离;但是,您可以指定其他几个选项之一。看到pdist为更多的信息。
注
在计算距离信息之前,您可以选择对数据集中的值进行标准化。在现实世界的数据集中,可以根据不同的尺度测量变量。例如,一个变量可以测量智商(IQ)测试分数和另一个变量可以测量头围。这些差异可能会扭曲近似计算。使用zscore函数,可以将数据集中的所有值转换为使用相同的比例比例。请参阅zscore为更多的信息。
例如,考虑数据集,X,由五个物体组成,每个对象都是一组x、 y坐标。
对象1: 1、2
对象2: 2.5, 4.5
对象3.: 2、2
对象4.: 4、1.5
对象5.: 4、2.5
您可以将此数据定义为矩阵
rng默认;%的再现性X = [1 2; 2.5 4.5; 2 2; 4 1.5;......4 2.5);
把它传递给pdist.这个pdist函数计算对象1和对象2、对象1和对象3之间的距离,以此类推,直到计算出所有对之间的距离。下图将这些对象绘制成图形。物体2和物体3之间的欧几里得距离用来解释距离的一种解释。

距离信息
这个pdist函数在向量中返回此距离信息,Y,每个元素包含一对对象之间的距离。
Y=pdist(X)
y =1×102.9155 1.0000 3.0414 3.0414 2.5495 3.3541 2.5000 2.0616 2.0616 1.0000
为了使更容易看到由此产生的距离信息之间的关系pdist和原始数据集中的对象,你可以用squareform函数。在这个矩阵中,元素我,我对应于物体之间的距离我和对象J在原始数据集中。在下面的示例中,元素1,1表示对象1和自身之间的距离(为零)。元素1,2表示对象1和对象2之间的距离,依此类推。
squareform (Y)
ans =5×50 2.9155 1.0000 3.0414 3.0414 2.9155 0 2.5495 3.3541 2.5000 1.0000 2.5495 0 2.0616 2.0616 3.0414 3.3541 2.0616 0 1.0000 3.0414 2.5000 2.0616 1.0000 0
联系
计算出数据集中对象之间的接近度之后,可以使用联动函数。这个联动函数获取生成的距离信息pdist链接靠近二进制集群的对象对(由两个对象组成的群集)。这个联动函数将这些新形成的集群相互连接,并与其他对象连接,以创建更大的集群,直到原始数据集中的所有对象在一个层次树中连接在一起。
例如,给定距离矢量Y生成的pdist的样本数据集x- 和Y坐标,联动函数生成一个层次簇树,以矩阵形式返回链接信息,Z.
z =链接(Y)
z =4×34.0000 5.0000 1.0000 1.0000 3.0000 1.0000 6.0000 7.0000 2.0616 2.0000 8.0000 2.5000
在此输出中,每行标识对象或群集之间的链接。前两个列标识已链接的对象。第三列包含这些对象之间的距离。对于示例数据集x- 和Y坐标,联动函数首先对距离最近的对象4和5进行分组(距离值= 1.0000)。这个联动函数继续对对象1和3进行分组,它们的距离值也为1.0000。
第三行表示联动函数将对象6和7分组。如果原始样本数据集只包含5个对象,那么对象6和对象7是什么?物体6是由物体4和物体5组合而成的新形成的二元簇。当联动函数将两个对象分组到一个新的集群中,它必须给集群分配一个唯一的索引值,从该值开始M+ 1,M是原始数据集中的对象数。(值1到M类似地,对象7是通过将对象1和3分组而形成的集群。
联动使用距离来确定它聚类对象的顺序。距离矢量Y包含原始对象1到5之间的距离。但linkage也必须能够确定它所创建的簇的距离,比如物体6和7。默认情况下,联动使用称为单链路的方法。但是,有许多不同的方法可用。看看联动参考页获取更多信息。
作为最终集群,联动函数将对象8、由对象6和7组成的新聚类与原始数据集中的对象2进行分组。下图以图形的方式说明了这种方法联动将对象分组为簇的层次结构。

树文图
由。创建的分层的、二叉集群树联动当以图形方式查看时,函数最容易理解系统树图如下绘制树。
系统树图(Z)

图中横轴上的数字表示原始数据集中对象的指数。物体之间的连接用倒置的u形线表示。U的高度表示物体之间的距离。例如,表示包含对象1和3的集群的链接的高度为1。链接表示将对象2与对象1、3、4和5(它们已经作为对象8聚集在一起)分组的集群,其高度为2.5。高度代表距离联动对象2和8之间的计算。有关创建树形图的详细信息,请参见系统树图参考页面。
验证群集树
在将数据集中的对象链接到一个层次集群树之后,您可能需要验证树中的距离(即高度)是否准确地反映了原始距离。此外,您可能希望研究存在于对象之间的链接之间的自然划分。统计和机器学习工具箱函数可用于这两个任务,如下面的部分所述。
验证不同
在层次聚类树中,原始数据集中的任意两个对象最终在某个级别链接在一起。链接的高度表示包含这两个对象的两个聚类之间的距离。该高度称为拷贝距离在两个物体之间。有一种方法可以衡量由联动函数反映你的数据是比较亲和距离与原始距离数据生成的pdist函数。如果聚类有效,聚类树中对象的链接应该与距离向量中对象之间的距离有很强的相关性。这个科菲内函数比较这两组值并计算它们的相关性,返回一个名为同表象相关系数.亲和相关系数的值越接近1,聚类解决方案反映您的数据就越准确。
您可以使用CopHenetic相关系数来使用不同距离计算方法或聚类算法进行比较群集相同数据集的结果。例如,你可以使用科菲内函数来评估为示例数据集创建的集群。
c=柯菲内(Z,Y)
c = 0.8615
Z矩阵是由联动功能和Y距离向量是由pdist函数。
执行pdist同样是在同一个数据集上,这次指定的是城市街区指标。后运行联动新功能pdist输出采用平均联动方法,调用科菲内评估集群解决方案。
Y=pdist(X,'城市街区'); Z=悬挂机构(Y,“平均”);c=柯菲内(Z,Y)
C = 0.9047.
共生相关系数表明,使用不同的距离和链接方法创建的树能够更好地表示原始距离。
验证一致性
确定数据集中的自然群划分的一种方法是将群集树中的每个链路的高度与树中的相邻链路的高度进行比较。
如果链接的高度与下面的链接大致相同,则表明在层次结构的这个级别上连接的对象之间没有明显的划分。这些链接据说表现出高度的一致性,因为被连接的物体之间的距离与它们所包含的物体之间的距离大致相同。
另一方面,如果链接的高度与其下方链接的高度明显不同,则表明在集群树中这一级别连接的对象之间的距离比它们的组件连接时的距离要远得多。这个链接据说与下面的链接不一致。
在聚类分析中,不一致的链接可以指示数据集中自然划分的边界。这个簇函数使用不一致性的定量度量来确定将数据集划分到集群的位置。
下面的树状图说明了不一致的链接。请注意树状图中的对象如何分为两组,这两组由树中更高级别的链接连接。这些链接与层次结构中它们下面的链接相比是不一致的。
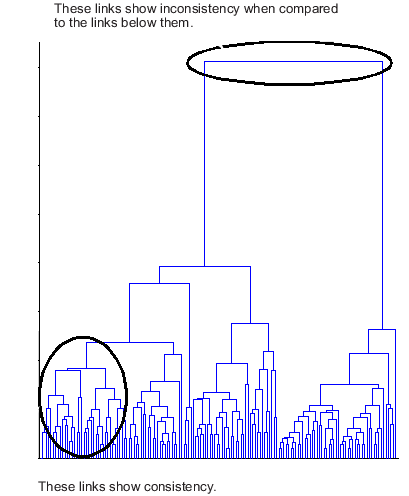
层次聚类树中各环节的相对一致性可以量化,表示为不一致系数. 此值将群集层次结构中链接的高度与其下方链接的平均高度进行比较。连接不同集群的链接具有较高的不一致系数;连接模糊簇的链接具有较低的不一致系数。
要生成群集树中每个链接的不一致系数的列表,请使用不一致的功能。默认情况下不一致的函数将群集层次结构中的每个链接与群集层次结构中低于它两级的相邻链接进行比较。这称为深度比较的结果。还可以指定其他深度。集群树底部的对象称为叶节点,它们下面没有其他对象,不一致系数为零。连接两片叶子的簇也具有零不一致系数。
例如,你可以使用不一致的方法创建的链接计算不一致值联动函数联系.
首先,使用默认设置重新计算距离和链接值。
Y = pdist (X);Z =连杆(Y);
下一步,使用不一致的来计算不一致值。
我=不一致(Z)
我=4×41.0000 0 1.0000 0 1.0000 0 1.0000 0 1.3539 0.6129 3.0000 1.1547 2.2808 0.3100 2.0000 0.7071
这个不一致的函数的作用是:返回一个(M-1) × 4矩阵,其列如下表所示。
| 列 | 描述 |
|---|---|
1. |
计算中所有环节高度的平均值 |
2. |
计算中包含的所有环节的标准差 |
3. |
计算中包含的链接数 |
4. |
不一致系数 |
在样本输出中,第一行表示对象4和5之间的链路。此集群被索引6分配联动函数。因为4和5都是叶节点,所以群集的不一致系数为零。第二行表示对象1和3之间的链路,两者也是叶节点。该群集通过链接函数分配索引7。
第三行评估连接这两个集群的链接,对象6和7。(这个新集群在联动输出)。第3列表示在计算中考虑了三个链接:链接本身和层次结构中位于其正下方的两个链接。第1列表示这些连接的平均高度。这个不一致的功能使用输出的高度信息联动函数来计算平均值。第2列表示链接之间的标准偏差。最后一列包含这些链接的不一致值1.1547。它是当前链接高度与平均值之间的差值,由标准偏差归一化。
(2.0616 - 1.3539) / .6129
ans=1.1547
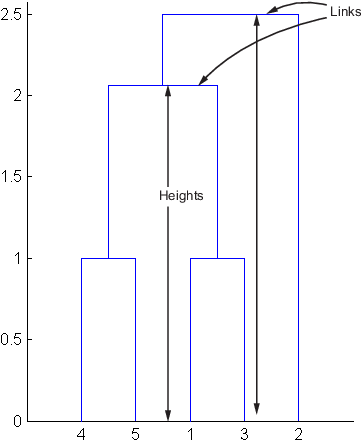
下图说明了计算中包含的链接和高度。

注
在上图中,上下限为Y-轴设置为0以显示链接的高度。设置下限为0, 选择轴特性从编辑菜单,单击Y轴选项卡,然后输入0就在田野的右边Y极限.
输出矩阵中的第4行描述了对象8和对象2.第3列之间的链路表示此计算中包含两个链接:链接本身和在层次结构中直接下方的链接。此链接的不一致系数为0.7071。
下图说明了计算中包含的链接和高度。
创建群集
创建二元集群的层次树之后,可以对树进行修剪,以便使用簇函数。这个簇函数允许您以两种方式创建群集,如以下部分所讨论的:
在数据中找到自然划分
层次聚类树可以自然地将数据划分为不同的、分离良好的聚类。这一点在树形图中表现得尤为明显,在树形图中,一组对象密集地分布在某些区域,而不是其他区域。聚类树中链接的不一致性系数可以识别对象之间相似性突然变化的区域。(见验证群集树有关不一致系数的更多信息。)您可以使用此值来确定其中的位置簇函数创建集群边界。
例如,如果你使用簇函数将样本数据集分组,指定不一致系数阈值1.2作为价值切断参数,簇函数将样本数据集中的所有对象分组为一个集群。在这种情况下,集群层次结构中的链接没有一个不一致系数大于1.2.
T=簇(Z,“截止”,1.2)
T =5×11 1 1 1
这个簇函数输出一个向量,T,与原始数据集的大小相同。此向量中的每个元素包含在放置原始数据集中的相应对象的群集的数量。
如果你降低不一致系数阈值为0.8这个簇函数将样本数据集划分为三个独立的集群。
T=簇(Z,“截止”, 0.8)
T =5×13 2 3 1 1
这个输出表明对象1和3在一个集群中,对象4和5在另一个集群中,对象2在它自己的集群中。
当以这种方式形成簇时,截止值应用于不一致系数。这些簇可以但不一定地对应于在一定高度的树枝上的水平切片。如果希望与水平切片对应的树形图相对应,则可以使用标准选项指定关闭应该基于距离而不是不一致,或者可以直接指定集群的数量,如下节所述。
指定任意的集群
而不是让簇函数“创建由数据集中的自然分段确定的簇”,可以指定要创建的簇的数目。
例如,您可以指定您想要的簇函数将样本数据集划分为两个集群。在这种情况下簇命令功能创建一个包含对象1、3、4和5的集群和另一个包含对象2的集群。
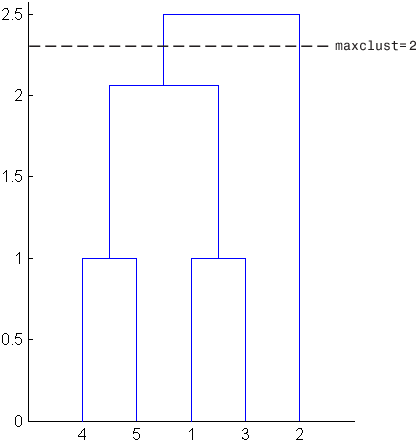
T=簇(Z,“maxclust”, 2)
T =5×12 1 2 2 2
来帮助你想象簇函数决定了这些簇,下图显示了分层簇树的树形图。水平虚线与树状图的两条线相交,对应设置“maxclust”到2.。这两条线将对象划分为两个簇:左侧线下的对象,即1、3、4和5,属于一个簇,而右侧线下的对象,即2,属于另一个簇。
另一方面,如果你设置“maxclust”到3.,群集功能将对象4和5分组在一个群集中,将对象1和3分组在第二个群集中,将对象2分组在第三个群集中。下面的命令演示了这一点。
T=簇(Z,“maxclust”3)
T =5×12 3 2 1 1
这次,簇函数在一个较低的点截断层次结构,对应于下图中与树状图的三条线相交的水平线。
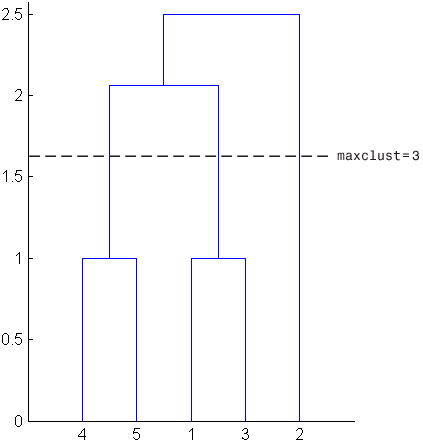
相关话题
你也可以从以下列表中选择一个网站:
