fitrsvm
拟合支持向量金宝app机回归模型
语法
描述
fitrsvm训练或交叉验证支持向量机(SVM)回归模型的低通过中维预金宝app测器数据集。fitrsvm金宝app支持使用内核函数映射预测器数据,支持SMO、ISDA或l1利用二次规划实现目标函数最小化的软裕度最小化。
为了在高维数据集(即包含许多预测变量的数据集)上训练线性支持向量机回归模型,使用fitrlinear代替。
要训练二进制分类的支持向量机模型,请参见fitcsvm对于低通中维预测器数据集,或fitclinear对于高维数据集。
Mdl= fitrsvm (资源描述,ResponseVarName)Mdl使用表中的预测器值进行训练资源描述的响应值资源描述。ResponseVarName.
例子
训练线性支持向量机回归模型金宝app
使用存储在矩阵中金宝app的样本数据训练支持向量机(SVM)回归模型。
加载carsmall数据集。
负载carsmallrng“默认”%用于重现性
指定马力而且重量作为预测变量(X),英里/加仑作为响应变量(Y).
X =[马力,重量];Y = mpg;
训练一个默认的SVM回归模型。
Mdl = fitrsvm(X,Y)
Mdl = RegressionSVM ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' Alpha: [75x1 double] Bias: 57.3958 KernelParameters: [1x1 struct] NumObservations: 93 BoxConstraints: [93x1 double] ConvergenceInfo: [1x1 struct] Is金宝appSupportVector: [93x1 logical] Solver: 'SMO' Properties, Methods
Mdl是经过训练的RegressionSVM模型。
检查模型是否收敛。
Mdl.ConvergenceInfo.Converged
ans =逻辑0
0表示模型没有收敛。
使用标准化数据重新训练模型。
MdlStd = fitrsvm(X,Y,“标准化”,真正的)
MdlStd = RegressionSVM ResponseName: 'Y' CategoricalPredictors: [] Alpha: [77x1 double] Bias: 22.9131 KernelParameters: [1x1 struct] Mu: [109.3441 2.9625e+03] Sigma: [45.3545 805.9668] NumObservations: 93 BoxConstraints: [93x1 double] ConvergenceInfo: [1x1 struct] IsSupportVector: [93x1 logic金宝appal] Solver: 'SMO' Properties, Methods
检查模型是否收敛。
MdlStd.ConvergenceInfo.Converged
ans =逻辑1
1表明模型确实收敛。
计算新模型的复代(样本内)均方误差。
lStd = resubLoss(MdlStd)
lStd = 17.0256
训练支持向量金宝app机回归模型
使用UCI机器学金宝app习库中的鲍鱼数据训练支持向量机回归模型。
下载数据并将其保存在当前文件夹中“abalone.csv”.
url =“https://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data”;websave (“abalone.csv”url);
将数据读入表中。指定变量名。
变量名= {“性”;“长度”;“直径”;“高度”;“Whole_weight”;...“Shucked_weight”;“Viscera_weight”;“Shell_weight”;“戒指”};Tbl =可读(“abalone.csv”,“文件类型”,“文本”,“ReadVariableNames”、假);Tbl.Properties.VariableNames = varnames;
样本数据包含4177个观测值。所有的预测变量都是连续的性,这是一个具有可能值的类别变量“米”(男性)“F”(女性),和“我”(婴儿)。目标是预测存储在环),并用物理测量方法测定鲍鱼的年龄。
训练支持向量机回归模型,使用具有自动核尺度的高斯核函数。标准化数据。
rng默认的%用于重现性n) n; n;“戒指”,“KernelFunction”,“高斯”,“KernelScale”,“汽车”,...“标准化”,真正的)
Mdl = RegressionSVM PredictorNames: {1×8 cell} ResponseName: 'Rings' CategoricalPredictors: 1 ResponseTransform: 'none' Alpha: [3635×1 double] Bias: 10.8144 KernelParameters: [1×1 struct] Mu: [1×10 double] Sigma: [1×10 double] NumObservations: 4177 BoxConstraints: [4177×1 double] ConvergenceInfo: [1×1 struct] Is金宝appSupportVector: [4177×1 logical] Solver: 'SMO'
命令窗口显示了这一点Mdl是经过训练的RegressionSVM建模并显示属性列表。
显示属性Mdl使用点表示法。例如,检查以确认模型是否收敛,以及它完成了多少次迭代。
convergenceinfo . converged iter = Mdl. convergenceinfo . convergenceinfo。NumIterations
Conv =逻辑1 iter = 2759
返回结果表明,该模型经过2759次迭代收敛。
交叉验证支持向量机回归模型
加载carsmall数据集。
负载carsmallrng“默认”%用于重现性
指定马力而且重量作为预测变量(X),英里/加仑作为响应变量(Y).
X =[马力重量];Y = mpg;
使用5倍交叉验证交叉验证两个SVM回归模型。对于这两个模型,指定以标准化预测器。对于其中一个模型,指定使用默认的线性核进行训练,而对于另一个模型则指定使用高斯核进行训练。
MdlLin = fitrsvm(X,Y,“标准化”,真的,“KFold”5)
MdlLin = RegressionPartitionedSVM CrossValidatedModel: 'SVM' PredictorNames: {'x1' 'x2'} ResponseName: 'Y' NumObservations: 94 KFold: 5 Partition: [1x1 cvpartition] ResponseTransform: 'none'属性,方法
MdlGau = fitrsvm(X,Y,“标准化”,真的,“KFold”5,“KernelFunction”,“高斯”)
MdlGau = RegressionPartitionedSVM CrossValidatedModel: 'SVM' PredictorNames: {'x1' 'x2'} ResponseName: 'Y' NumObservations: 94 KFold: 5 Partition: [1x1 cvpartition] ResponseTransform: 'none'属性,方法
MdlLin。训练有素的
ans =5×1单元格数组{1 x1 classreg.learning.regr。CompactRegressionSVM} {1x1 classreg.learning.regr.CompactRegressionSVM} {1x1 classreg.learning.regr.CompactRegressionSVM} {1x1 classreg.learning.regr.CompactRegressionSVM} {1x1 classreg.learning.regr.CompactRegressionSVM}
MdlLin而且MdlGau是RegressionPartitionedSVM旨在模型。的训练有素的属性是一个5 × 1的单元格数组CompactRegressionSVM模型。单元格中的模型存储了4层观测数据上的训练结果,将1层观测数据删除。
比较模型的泛化误差。在这种情况下,泛化误差是样本外均方误差。
mseLin = kfoldLoss(MdlLin)
mseLin = 17.4417
mseGau = kfoldLoss(MdlGau)
mseGau = 16.7355
使用高斯核的支持向量机回归模型优于使用线性核的支持向量机回归模型。
通过传递整个数据集来创建一个适合进行预测的模型fitrsvm,并指定所有产生性能更好的模型的名值对参数。但是,不要指定任何交叉验证选项。
MdlGau = fitrsvm(X,Y,“标准化”,真的,“KernelFunction”,“高斯”);
要预测一组车的MPG,通过Mdl还有一个表格,里面有这些车的马力和重量预测.
优化支持向量机回归
此示例演示如何使用自动优化超参数fitrsvm.该示例使用carsmall数据。
加载carsmall数据集。
负载carsmall
指定马力而且重量作为预测变量(X),英里/加仑作为响应变量(Y).
X =[马力重量];Y = mpg;
通过使用自动超参数优化找到最小化五倍交叉验证损失的超参数。
为了再现性,设置随机种子并使用“expected-improvement-plus”采集功能。
rng默认的Mdl = fitrsvm(X,Y,“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,...“expected-improvement-plus”))
|====================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | BoxConstraint | KernelScale |ε| | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | | | |====================================================================================================================| | 最好1 | | 6.8077 | 10.27 | 6.8077 | 6.8077 | 0.35664 | 0.043031 | 0.30396 | | 2 |最好| 2.9108 | 0.097504 | 2.9108 | 3.1259 | 70.67 | 710.65 | 1.6369 | | 3 |接受| 4.1884 | 0.18596 | 2.9108 | 3.1211 | 14.367 | 0.0059144 | 442.64 ||4 | Accept | 4.159 | 0.060684 | 2.9108 | 3.0773 | 0.0030879 | 715.31 | 2.6045 | | 5 | Best | 2.902 | 0.17193 | 2.902 | 2.9015 | 969.07 | 703.1 | 0.88614 | | 6 | Accept | 4.1884 | 0.052457 | 2.902 | 2.9017 | 993.93 | 919.26 | 22.16 | | 7 | Accept | 2.9307 | 0.07753 | 2.902 | 2.9018 | 219.88 | 613.28 | 0.015526 | | 8 | Accept | 2.9537 | 0.35015 | 2.902 | 2.9017 | 905.17 | 395.74 | 0.021914 | | 9 | Accept | 2.9073 | 0.096023 | 2.902 | 2.9017 | 24.242 | 647.2 | 0.17855 | | 10 | Accept | 2.9044 | 0.23756 | 2.902 | 2.9017 | 117.27 | 173.98 | 0.73387 | | 11 | Accept | 2.9035 | 0.082249 | 2.902 | 2.9016 | 1.3516 | 131.19 | 0.0093404 | | 12 | Accept | 4.0917 | 0.060391 | 2.902 | 2.902 | 0.012201 | 962.58 | 0.0092777 | | 13 | Accept | 2.9525 | 0.98384 | 2.902 | 2.902 | 77.38 | 65.508 | 0.0093299 | | 14 | Accept | 2.9352 | 0.082393 | 2.902 | 2.9019 | 21.591 | 166.43 | 0.035214 | | 15 | Accept | 2.9341 | 0.10258 | 2.902 | 2.9019 | 45.286 | 207.56 | 0.009379 | | 16 | Accept | 2.9104 | 0.057282 | 2.902 | 2.9018 | 0.064315 | 23.313 | 0.0093341 | | 17 | Accept | 2.9056 | 0.12011 | 2.902 | 2.9018 | 0.33909 | 40.311 | 0.053394 | | 18 | Accept | 2.9335 | 0.11486 | 2.902 | 2.8999 | 0.9904 | 41.169 | 0.0099688 | | 19 | Accept | 2.9885 | 0.18598 | 2.902 | 2.8994 | 0.0010647 | 32.9 | 0.013178 | | 20 | Accept | 4.1884 | 0.070586 | 2.902 | 2.9 | 0.0014524 | 1.9514 | 856.49 | |====================================================================================================================| | Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Epsilon | | | result | log(1+loss) | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 21 | Accept | 2.904 | 0.097499 | 2.902 | 2.8835 | 88.487 | 405.92 | 0.44372 | | 22 | Accept | 2.9107 | 0.080064 | 2.902 | 2.8848 | 344.34 | 992 | 0.28418 | | 23 | Accept | 2.904 | 0.063158 | 2.902 | 2.8848 | 0.92028 | 70.985 | 0.52233 | | 24 | Accept | 2.9145 | 0.067186 | 2.902 | 2.8822 | 0.0011412 | 18.159 | 0.16652 | | 25 | Best | 2.8909 | 0.18742 | 2.8909 | 2.8848 | 0.7614 | 17.3 | 1.9075 | | 26 | Accept | 2.9188 | 0.10836 | 2.8909 | 2.8816 | 0.31049 | 18.301 | 0.35285 | | 27 | Accept | 2.9327 | 0.065803 | 2.8909 | 2.8811 | 0.015362 | 20.395 | 1.6596 | | 28 | Accept | 2.897 | 0.11764 | 2.8909 | 2.8811 | 3.3454 | 46.537 | 2.224 | | 29 | Accept | 4.1884 | 0.061914 | 2.8909 | 2.881 | 983.2 | 0.52308 | 910.91 | | 30 | Accept | 2.9167 | 0.055172 | 2.8909 | 2.8821 | 0.0011533 | 10.597 | 0.029731 |
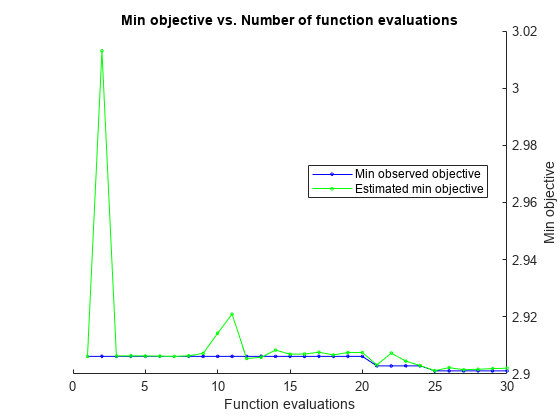
__________________________________________________________ 优化完成。最大目标:达到30。总函数评估:30总运行时间:46.34秒总目标函数评估时间:14.3647最佳观测可行点:BoxConstraint KernelScale Epsilon _____________ ___________ _______ 0.7614 17.3 1.9075观测目标函数值= 2.8909估计目标函数值= 2.8957函数评估时间= 0.18742最佳估计可行点(根据模型):BoxConstraint KernelScale Epsilon _____________ ___________ _______ 88.487 405.92 0.44372估计的目标函数值= 2.8821估计的函数评估时间= 0.10031
Mdl = RegressionSVM ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' Alpha: [86x1 double] Bias: 46.2480 KernelParameters: [1x1 struct] NumObservations: 93 HyperparameterOptimizationResults: [1x1 BayesianOptimization] BoxConstraints: [93x1 double] ConvergenceInfo: [1x1 struct] Is金宝appSupportVector: [93x1 logical] Solver: 'SMO' Properties, Methods
优化搜索BoxConstraint,KernelScale,ε.输出是估计交叉验证损失最小的回归。
输入参数
输出参数
限制
fitrsvm金宝app支持低通中维数据集。对于高维数据集,使用fitrlinear代替。
提示
除非您的数据集很大,否则总是尝试将预测器标准化(参见
标准化).标准化使得预测器对它们所测量的尺度不敏感。的交叉验证是一种很好的实践
KFold名称-值对参数。交叉验证结果决定了支持向量机模型的推广效果。支持向量的稀疏性是支持向金宝app量机模型的一个理想属性。若要减少支持向量的数量,请设置金宝app
BoxConstraint名称-值对参数设置为大值。这个动作也增加了训练时间。为最佳训练时间,设置
CacheSize您的计算机上的内存限制所允许的最大值。如果您期望的支持向量比训练集中的观察值要少得多,那金宝app么您可以使用名称-值对参数缩小活动集,从而显著加快收敛速度
“ShrinkagePeriod”.这是一个很好的练习“ShrinkagePeriod”,1000年.远离回归线的重复观测结果不会影响收敛。然而,只要在回归线附近出现一些重复的观察结果,就会大大减慢收敛速度。要加快收敛速度,请指定
“RemoveDuplicates”,真的如果:你的数据集包含许多重复的观察结果。
您怀疑一些重复的观察结果可能落在回归线附近。
然而,为了在训练过程中保持原始数据集,
fitrsvm必须临时存储不同的数据集:原始数据集和没有重复观测的数据集。因此,如果指定真正的对于包含少量副本的数据集,那么fitrsvm消耗的内存接近原始数据的两倍。在训练一个模型之后,您可以生成预测新数据响应的C/ c++代码。生成C/ c++代码需要MATLAB编码器™.详情请参见代码生成简介.
算法
关于线性和非线性支持向量机回归问题的数学公式和求解算法,请参见理解支持向量机回归金宝app.
南,<定义>,空字符向量(”,空字符串(""),< >失踪值表示丢失的数据值。fitrsvm删除与丢失响应对应的整行数据。当归一化权值时,fitrsvm忽略与至少一个缺失预测因子的观察结果相对应的任何权重。因此,观察箱的约束可能不相等BoxConstraint.fitrsvm删除权值为零的观察值。如果你设置
“标准化”,真的而且“重量”,然后fitrsvm使用相应的加权平均数和加权标准差对预测因子进行标准化。也就是说,fitrsvm标准化预测j(xj)使用xjk是观察k(行)的预测器j(列)。
如果你的预测数据包含分类变量,那么软件通常对这些变量使用全虚拟编码。该软件为每个类别变量的每一级创建一个虚拟变量。
的
PredictorNames属性为每个原始预测器变量名存储一个元素。例如,假设有三个预测器,其中一个是具有三个级别的类别变量。然后PredictorNames是包含预测器变量的原始名称的字符向量的1 × 3单元格数组。的
ExpandedPredictorNames属性为每个预测器变量(包括虚拟变量)存储一个元素。例如,假设有三个预测器,其中一个是具有三个级别的类别变量。然后ExpandedPredictorNames是一个1 × 5的字符向量单元格数组,其中包含预测变量和新的虚拟变量的名称。类似地,
β属性为每个预测器(包括虚拟变量)存储一个beta系数。的
金宝appSupportVectors属性存储支持向量(包括虚拟变量)的预测器值。金宝app例如,假设有米金宝app支持向量和三个预测因子,其中一个是三级分类变量。然后金宝appSupportVectors是一个米5矩阵。的
X属性将训练数据存储为原始输入。它不包括哑变量。当输入是一个表时,X只包含用作预测器的列。
对于表中指定的预测器,如果任何变量包含有序(序数)类别,则软件对这些变量使用序数编码。
对于一个变量k软件会创建有序的关卡k- 1虚拟变量。的j虚变量为-1适用于以下级别j,+1的水平j+ 1通过k.
对象中存储的虚拟变量的名称
ExpandedPredictorNames属性用值指示第一个级别+1.软件商店k- 1虚拟变量的其他预测器名称,包括级别2、3、…k.
所有求解器实现l1 .软边际最小化。
让
p是训练数据中你期望的异常值的比例。如果你设置OutlierFraction, p,然后软件实现强劲的学习.换句话说,该软件试图删除100个p优化算法收敛时观测值的%。被删除的观测值对应于量级较大的梯度。
参考文献
[1] D.克拉克,Z.施雷特,A.亚当斯。“反向传播和反向传播的定量比较”,提交给1996年澳大利亚神经网络会议。
[2]风扇,r.e。,林志信。和c.j。林。用二阶信息选择工作集来训练支持向量机。金宝app机器学习研究杂志, 2005年第6卷,1889-1918页。
凯克曼V., t。黄和M.沃格特。从巨大数据集训练核机器的迭代单数据算法:理论和性能。在金宝app支持向量机:理论与应用.王立波主编,255-274。柏林:Springer-Verlag, 2005。
利希曼,M。UCI机器学习库[http://archive.ics.uci.edu/ml]。加州尔湾:加州大学信息与计算机科学学院。
纳什,w.j., T. L.塞勒斯,S. R.塔尔博特,A. J.考索恩,W. B.福特。鲍鱼种群生物学(石决明物种)在塔斯马尼亚。一、黑唇鲍鱼(h . rubra)从北海岸和巴斯海峡的岛屿。”海洋渔业司,技术报告第48号,1994年。
哇,S。级联相关的扩展和基准测试:前馈监督人工神经网络的级联相关体系结构和基准测试的扩展。塔斯马尼亚大学计算机科学系论文, 1995年。
扩展功能
您也可以从以下列表中选择网站:
