TreeBagger
班级:TreeBagger
创建决策树包
单个决策树倾向于过度拟合。Bootstrap-aggregated (袋装)决策树结合大量的决策树,从而降低过度拟合的效果,提高了泛化的结果。TreeBagger使用数据的引导样本在集成中生长决策树。同时,TreeBagger选择预测器的随机子集在每个决定分割使用如随机森林算法[1].
默认情况下,TreeBagger包分类树。要打包回归树,请指定“方法”,“回归”.
对于回归问题,TreeBagger金宝app支持均值和大分回归(即定量回归森林[5])。
句法
ResponseVarName Mdl = TreeBagger (NumTrees(资源)
Mdl = TreeBagger (NumTrees、资源描述、公式)
mdl = treebagger(numtrees,tbl,y)
B = TreeBagger (NumTrees, X, Y)
B = TreeBagger (NumTrees, X, Y,名称,值)
描述
Mdl= TreeBagger (NumTrees,TBL.,responsevarname.)NumTrees使用表中样本数据训练的袋装分类树TBL..responsevarname.是在响应变量的名称TBL..
Mdl= TreeBagger (NumTrees,TBL.,公式)TBL..公式是否有一个反应的解释模型和一个预测变量子集TBL.适合使用Mdl.指定公式使用Wilkinson表示法。有关更多信息,请参见Wilkinson表示法.
Mdl= TreeBagger (NumTrees,TBL.,Y)TBL.和类别标签在矢量Y.
Y是响应数据数组。的元素Y对应于的行TBL..分类,Y是一组真正的类标签。标签可以是任何分组变量,即数字或逻辑向量、字符矩阵、字符串数组、字符向量单元格数组或分类向量。TreeBagger标签转换为字符向量的单元阵列。对于回归,Y是一个数字向量。要生成回归树,必须指定名称-值对“方法”,“回归”.
B= TreeBagger (NumTrees,X,Y)B的NumTrees用于预测响应的决策树Y作为预测的在训练数据的数字矩阵的函数,X.在每一行X表示一个观察结果,每一列表示一个预测器或特征。
B = TreeBagger (NumTrees, X, Y,名称,值)指定可选参数名称-值对:
“InBagFraction” |
输入数据的分数与从用于生长每个新树中的输入数据的替换样品。默认值是1。 |
'成本' |
方阵 或者,
默认值为 如果 |
“SampleWithReplacement” |
“上”取样用替换或'离开'无需更换采样。如果您品尝无需更换,需要设置“InBagFraction”小于1的值。默认是“上”. |
“OOBPrediction” |
“上”存储的信息是什么观测袋每个树出来。这个信息可以通过使用oobPrediction来计算预测的类概率在合奏每个树。默认是'离开'. |
'Oobpredictorimportance' |
“上”存储在整体功能的重要性了球袋估计。默认是'离开'.指定“上”还设置了“OOBPrediction”价值“上”.如果预测器的重要性分析是您的目标,那么也要指定'PredictorSelection', '弯曲'或“PredictorSelection”,“相互作用曲率”.有关更多详细信息,请参阅fitctree或fitrtree. |
“方法” |
任何一个'分类'或'回归'.回归需要一个数字Y. |
“NumPredictorsToSample” |
对于每个决策拆分,随机选择的变量数。默认是分类的变量数的平方根,以及回归数量的三分之一。有效值是'全部'或者一个正整数。将此参数设置为任何有效值,但是'全部'调用Breiman的随机森林算法[1]. |
“NumPrint” |
培训周期数(成年树)之后,TreeBagger显示诊断消息,显示培训进度。默认值是没有诊断消息。 |
'minleafsize' |
每片树叶的最低观察次数。默认值是1表示分类,5表示回归。 |
'选项' |
一种结构,它指定在增长决策树集合时控制计算的选项。一个选项要求在多个引导复制上的决策树计算使用多个处理器,如果并行计算工具箱™可用的话。两个选项指定在选择引导复制时使用的随机数流。可以通过调用来创建此参数
|
'事先的' |
每个班级的先前概率。指定为以下之一:
如果您为两者设置值 如果 |
“PredictorNames” |
预测器变量名,指定为逗号分隔的一对组成的
|
“CategoricalPredictors” |
分类预测列表中,指定为逗号分隔的一对组成的
|
ChunkSize的 |
块大小,指定为逗号分隔对,由 笔记 此选项仅适用于使用时 |
除了上面的可选参数,TreeBagger接受这些可选fitctree和fitrtree论点。
金宝app支持fitctree争论 |
金宝app支持fitrtree争论 |
|---|---|
AlgorithmForCategorical |
MaxNumSplits |
MaxNumCategories |
MergeLeaves |
MaxNumSplits |
预测互联 |
MergeLeaves |
修剪 |
预测互联 |
PruneCriterion |
修剪 |
QuadraticErrorTolerance |
PruneCriterion |
SplitCriterion |
SplitCriterion |
代理 |
代理 |
权重 |
“重量” |
例子
袋装分类树的序列集合
装载Fisher的Iris数据集。
加载fisheriris
使用整个数据集培训袋装分类树的集合。指定50.弱学习者。存储哪些观察袋为每棵树袋。
RNG(1);%的再现性Mdl = TreeBagger(50、量、物种,“OOBPrediction”,“上”,......“方法”,'分类')
MDL = TreeBagger合奏用50个袋装决策树:培训X:[150x4]培训Y:[150x1]方法:分类NumPredictors:4个NumPredictorsToSample:2 MinLeafSize:1个InBagFraction:1 SampleWithReplacement:1个ComputeOOBPrediction:1个ComputeOOBPredictorImportance:0接近:[]类名:“setosa'菌“弗吉尼亚”的属性,方法
Mdl是A.TreeBagger合奏。
Mdl。树木存储培训的分类树的50×1个细胞矢量(CompactClassificationTree模型对象)组成该合奏。
绘制第一训练分类树的图表。
视图(Mdl。{1},“模式”,“图”)

默认情况下,TreeBagger长深树。
Mdl.OOBIndices将包外索引存储为逻辑值矩阵。
用已生长的分类树的数量绘制出包外误差。
图;oobErrorBaggedEnsemble = oobError (Mdl);情节(oobErrorBaggedEnsemble)包含“种植的树木数”;ylabel“乱袋分类错误”;
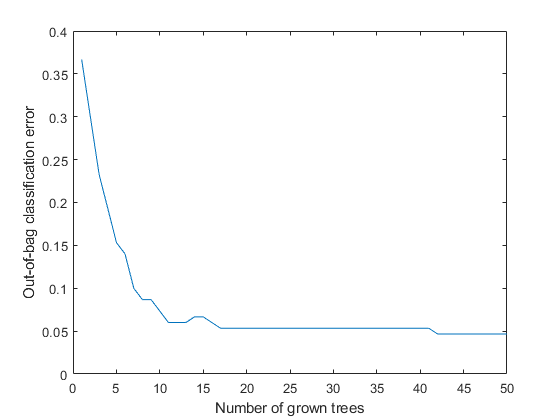
袋外误差随着树木的生长而减小。
标记袋子外观察,通过Mdl来oobPredict.
袋装回归树的火车合奏
加载carsmall数据集。考虑一个模型,它可以预测给定发动机排量的汽车的燃油经济性。
加载carsmall
列车采用整个数据集袋装回归树的集合。指定100个弱学习。
RNG(1);%的再现性Mdl = TreeBagger(位移,100英里,“方法”,'回归');
Mdl是A.TreeBagger合奏。
使用训练过的回归树包,您可以估计条件均值响应或执行分位数回归来预测条件分位数。
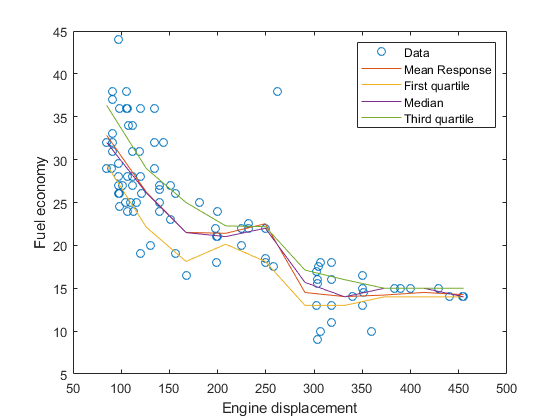
对于样本的位移最小值和最大值之间10个相等间隔的发动机的位移,预测条件均值反应和条件的四分位数。
predx = linspace(min(位移),max(位移),10)';mpgmean =预测(mdl,predx);mpgquartiles = smileilepredict(mdl,predx,分位数的, 0.25, 0.5, 0.75);
在同一图中绘制观察结果、估计平均响应和四分位数。
图;图(位移,MPG,'o');持有在情节(predX mpgMean);情节(predX mpgQuartiles);ylabel (“燃油经济性”);xlabel('发动机排量');传奇(“数据”,'意思是回应',“第一个四分位数”,“中位数”,'第三个四分位数');
无偏预测重要估计
加载carsmall数据集。考虑一个模型,它可以预测一辆汽车的平均燃油经济性,该模型给出了汽车的加速度、汽缸数、发动机排量、马力、制造商、车型年份和重量。考虑气缸,制造行业,Model_Year作为分类变量。
加载carsmall气缸=分类(缸);MFG =分类(cellstr(MFG));Model_Year =分类(Model_Year);X =表(加速度,缸,排气量,马力,厂家批号,......Model_Year、重量、MPG);rng ('默认');%的再现性
显示类别变量中表示的类别数量。
numCylinders =元素个数(类别(气缸))
numCylinders = 3
numMfg =元素个数(类别(有限公司))
numMfg = 28
numModelYear = numel(类别(Model_Year))
numModelYear = 3
因为有3个类别只在气缸和Model_Year在标准CART中,预测器分割算法更喜欢分割连续预测器而不是这两个变量。
使用整个数据集训练一个包含200棵回归树的随机森林。要种植无偏的树,指定使用曲率测试的分裂预测器。由于数据中缺少值,请指定代理拆分的用法。存储包外信息用于预测因子的重要性估计。
mdl = treebagger(200,x,“英里”,“方法”,'回归',“代孕”,“上”,......'PredictorSelection',“弯曲”,'Oobpredictorimportance',“上”);
TreeBagger卖场预测因素属性重要性的估计OobpermutedPredictordeltaError.用条形图比较估计值。
小鬼= Mdl.OOBPermutedPredictorDeltaError;图;酒吧(imp);标题('曲率测试');ylabel ('预测重点估计');xlabel(“预测器”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
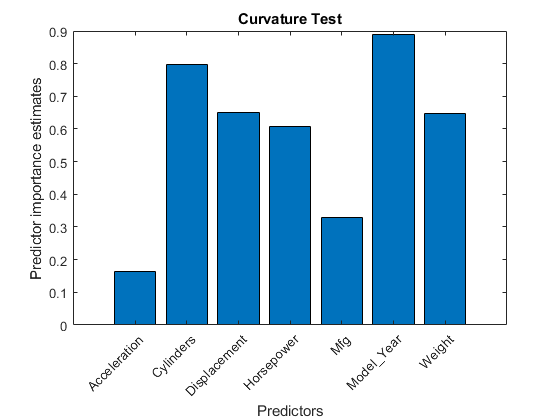
在这种情况下,Model_Year是最重要的预测因素,其次是重量.
比较偶尔预测来自使用标准推车的随机林计算的重要性估计。
MdlCART = TreeBagger (200 X,“英里”,“方法”,'回归',“代孕”,“上”,......'Oobpredictorimportance',“上”);impCART = MdlCART.OOBPermutedPredictorDeltaError;图;酒吧(impCART);标题(“标准车”);ylabel ('预测重点估计');xlabel(“预测器”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
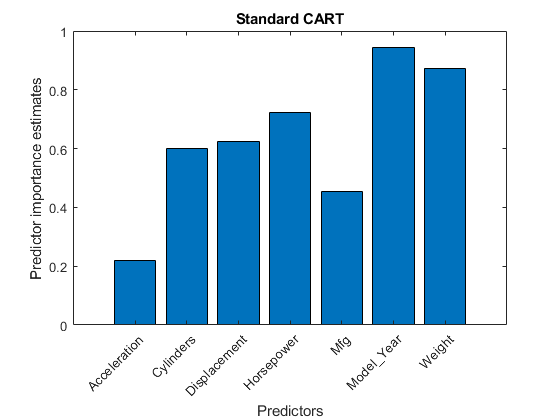
在这种情况下,重量,连续预测,是最重要的。接下来的两个最重要的预测是Model_Year紧随其后的是马力,这是一个连续的预测器。
高阵列上袋装分类树的序列集合
将观测数据的袋装分类树集合训练成一个高数组,并找出加权观测数据模型中每棵树的误分类概率。样本数据集Airlinesmall.csv.是包含航空公司的航班数据的表格文件中的大型数据集。
当您在高数组上执行计算时,MATLAB®使用一个并行池(如果您有parallel Computing Toolbox™,则默认)或本地MATLAB会话。要在使用并行计算工具箱时使用本地MATLAB会话运行示例,请使用Mapreducer.函数。
mapreduce (0)
创建一个数据存储,它引用包含数据集的文件夹的位置。选择变量的子集以与其合作,并处理'na'值作为缺失数据,以便数据存储它们替换南价值观。创建一个包含数据存储中的数据的高表。
DS =数据存储区(“airlinesmall.csv”);ds.selectedvariablenames = {“月”,“DayofMonth”,“星期几”,......“DepTime”,“ArrDelay”,“距离”,“DepDelay”};ds.TreatAsMissing ='na';tt =高(ds)%高表
TT = MX7高大表月DAYOFMONTH DAYOFWEEK DepTime ArrDelay距离DepDelay _____ __________ _________ _______ ________ ________ ________ 10 21 3 642 8 308 12 10 26 1 1021 8 296 1 10 23 5 2055 21 480 20 10 23 5 1332 13 296 12 10 22 4629 4 373 -1 10 28 3 1446 59 308 63 10 8 4 928 3 447 10 -2 10 6 859 11 954 -1::::::::::::::
通过定义一个对迟到航班适用的逻辑变量来确定迟到10分钟或更长时间的航班。这个变量包含类标签。这个变量的预览包括前几行。
Y = tt.DepDelay> 10%类标签
Y =的Mx1高逻辑阵列1 0 1 1 0 1 0 0:
为预测器数据创建一个高数组。
X = tt {: 1: end-1}%的预测数据
X = Mx6双矩阵10 21 3 642 8 308年10 26 1 1021 8 296 1332年10 23 5 2055 21 480 23日5 13 296 10 22 4 629 4 373 10 28 3 1446 59 308 859 8 4 928 447 10 10 6 11 954 : : : : : : : : : : : :
通过任意为1类的观察分配双重权重来为观察权重创建一个高阵列。
w = y + 1;%的重量
删除行X,Y,W包含丢失的数据。
R = rmmissing([X Y W]);%数据去掉缺少的项X = R(:,1:端-2);Y = R(:,端-1);W = R(:,端);
列车使用整个数据集的20个袋装决策树合奏。指定的权重向量和均匀的先验概率。对于重复性,使用设定的随机数生成器的种子RNG和tallrng.结果可以根据工人数量和高大阵列的执行环境而有所不同。有关详细信息,请参阅控制自己的代码运行.
rng ('默认')Tallrng('默认'tMdl = TreeBagger(20,X,Y,)“重量”,w,'事先的','制服')
评估高表达式使用当地的MATLAB会话:通过1 1:在1.4秒完成评估在1.8秒完成评估高表达式使用本地MATLAB会话:-通过1对1:在2.6秒完成评估在2.8秒完成评估高表达式使用本地MATLAB会话:-通过1的1:6.6秒完成评估6.6秒
TMDL = CompactTreeBagger合奏用20个袋装决策树:方法:分类NumPredictors:6类名: '0' '1' 的属性,方法
tMdl是A.CompactTreeBagger合奏与20架袋装决策树。
计算模型中各树的误分类概率。属性向量中包含的权重W通过使用“重量”名称-值对的论点。
TERR =错误(TMDL,X,Y,“重量”,w)
using the Local MATLAB Session: - Pass 1 of 1: Completed in 9.4 sec
恐怖分子=20×10.1420 0.1214 0.1115 0.15 0.1078 0.1037 0.1027 0.1005 0.0997 0.0981 0.0983
求决策树集合的平均误分类概率。
avg_terr =意味着(恐怖分子)
avg_terr = 0.1022
提示
通过设置更平衡的误分类代价矩阵或更少扭曲的先验概率向量,避免估计出的较大的包外误差方差。
的
树木财产B存储的单元阵列B.NumTreesCompactClassificationTree或CompactRegressionTree模型对象。用于树的文本或图形显示t在单元格数组中,输入视图(B.Trees {t})标准CART倾向于选择包含在含有几个不同的值,例如,分类变量那些许多不同的值,例如,连续的变量,分裂的预测[4].如果下列任意一个为真,考虑指定曲率或交互测试:
如果存在具有比其他预测相对较少不同的值,例如,如果预测的数据集是异质的预测因子。
如果对预测的重要性分析是您的目标。
TreeBagger商店预测的重要性估计OobpermutedPredictordeltaError财产Mdl.
算法
另类功能
Statistics and Machine Learning Toolbox™提供了三种对象用于套袋和随机森林:
TreeBagger由...制作TreeBagger用于分类和回归
有关之间差异的详细信息TreeBagger和袋装合奏(ClassificationBaggedensemble.和RegressionBaggedEnsemble),看套袋式和套袋式的比较.
参考
[1] Breiman, L。随机森林。机器学习45,pp. 5-32, 2001。
[2] Breiman, L., J. Friedman, R. Olshen, C. Stone。分类与回归树.佛罗里达州Boca Raton:CRC出版社,1984年。
[3] LOH,W.Y.“具有无偏的变量选择和相互作用检测的回归树。”STATISTICA SINICA.,卷。12,2002年,第361-386。
[4]蕙,W.Y.和Y.S.施。“拆分选择方法对于分类树”。STATISTICA SINICA., 1997年第7卷,第815-840页。
[5] Meinshausen,N“位数回归森林”。杂志的机器学习研究的,卷。7,2006年,第983-999。
扩展能力
您还可以从以下列表中选择一个网站:
