treebaggerclass
袋决策树
Description
treebagger袋子为分类或回归的决策树的集合。装袋代表引导聚合。合奏中的每棵树都在独立绘制的输入数据的自主绘制复制品上生长。此副本中未包含的观察是“从包中的”这棵树。
treebaggerrelies on theClassificationTree和RegressionTree种植个体树木的功能。特别是,ClassificationTree和RegressionTree接受随机选择的功能数量,每个决定拆分为可选的输入参数。那是,treebagger一世mplements the random forest algorithm[1]。
For regression problems,treebaggersupports mean and quantile regression (that is, quantile regression forest[2])。
To predict mean responses or estimate the mean-squared error given data, pass a
treebagger模型和数据到预测要么error, 分别。执行类似的操作以进行袋袋观察,使用oobPredict要么ooberror.。估计响应分布的定量或给定数据的定量误差,通过a
treebagger模型和数据到standilepredict.要么quantileError, 分别。执行类似的操作以进行袋袋观察,使用OOBQUANTILEPREDICT要么ooberror.。
Construction
| treebagger | 创造决策树 |
方法s
| 附加 | 添加新树合奏 |
| compact | 决策树的紧凑型集合 |
| error | 错误(错误分类概率或MSE) |
| fillprox | Proximity matrix for training data |
| Growtees. | 培训额外的树木并添加到合奏 |
| margin | 分类保证金 |
| mdsprox. | 多维标度的距离矩阵 |
| meanMargin | Mean classification margin |
| ooberror. | Out-of-bag error |
| oobMargin | Out-of-bag margins |
| Oobmeanmargin. | 袋子的平均边距 |
| oobPredict | Ensemble predictions for out-of-bag observations |
| oobQuantileError | 袋子袋数丢失的袋子 |
| OOBQUANTILEPREDICT | 从袋子袋袋中观测到回归树的分量预测 |
| 预测 | 使用袋装决策树的集合来预测响应 |
| quantileError | Quantile loss using bag of regression trees |
| standilepredict. | 使用袋子回归树预测响应量子 |
Properties
|
包含响应变量的类名的单元格数组 |
|
应计算指定是否应该计算用于训练观察的袋子预测的逻辑标志。默认为 If this flag is
If this flag is
|
|
应计算指定是否应计算可变重要性外包估计的逻辑标志。默认为 If this flag is
|
|
Square matrix, where 这个属性是:
|
|
Default value returned by
|
|
一个数字1-by-的数字数组Nvars分裂标准的变化总结了每个变量的分裂,平均整个成长树的整体。 |
|
随机选择的观察分数,用于替换每个引导副本。每个副本的大小是谈判× |
|
一个逻辑标志,指定与同一父级的决策树是否留下的拆分是不降低总风险的拆分。默认值是 |
|
树木使用的方法。可能的值是 |
|
每棵树叶的最小观察数。默认, |
|
标量值等于合奏中的决策树数。 |
|
一个数字1-by-的数字数组Nvars那where every element gives a number of splits on this predictor summed over all trees. |
|
Number of predictor or feature variables to select at random for each decision split. By default, |
|
逻辑阵列大小谈判-by-NumTrees那where谈判是培训数据和培训数据的观察数NumTrees是集合中的树木数量。一种 |
|
大小的数字数组谈判-1包含用于计算每次观察的禁止袋响应的树木数量。谈判是T.he number of observations in the training data used to create the ensemble. |
|
一个数字1-by-的数字数组Nvarscontaining a measure of variable importance for each predictor variable (feature). For any variable, the measure is the difference between the number of raised margins and the number of lowered margins if the values of that variable are permuted across the out-of-bag observations. This measure is computed for every tree, then averaged over the entire ensemble and divided by the standard deviation over the entire ensemble. This property is empty for regression trees. |
|
一个数字1-by-的数字数组Nvars包含每个预测变量(特征)的重要性衡量标准。对于任何变量,如果在袋袋外观察结果允许该变量的值,则测量值是预测误差的增加。对于每棵树计算此措施,然后在整个集合上平均并除以整个集合的标准偏差。 |
|
一个数字1-by-的数字数组Nvars包含每个预测变量(特征)的重要性衡量标准。For any variable, the measure is the decrease in the classification margin if the values of that variable are permuted across the out-of-bag observations. This measure is computed for every tree, then averaged over the entire ensemble and divided by the standard deviation over the entire ensemble. This property is empty for regression trees. |
|
一个数字大小数组谈判-by-1, where谈判是T.he number of observations in the training data, containing outlier measures for each observation. |
|
每个班级的先前概率的数字矢量。元素的顺序 这个属性是:
|
|
一个数字矩阵的大小谈判-by-谈判那where谈判是培训数据中的观察数,含有观察之间的邻近度的措施。对于任何两个观察,它们的接近程度被定义为这些观察结果在同一叶上造成的树木的一部分。这是一个对照矩阵,对角线和非对角线元件上的1S,范围为0到1。 |
|
该 |
|
一种logical flag specifying if data are sampled for each decision tree with replacement. This property is |
|
|
|
细胞阵列的大小NumTrees- 1含有集合中的树木。 |
|
大小的矩阵Nvars-by-Nvars具有可变关联的预测措施,平均整个成长树的整体。如果你长大了集合设置 |
|
包含预测器变量的名称(特征)的单元格数组。 |
|
Numeric vector of weights of length谈判那where谈判是T.he number of observations (rows) in the training data. |
|
一种T.able or numeric matrix of size谈判-by-Nvars那where谈判是观察数(行)和Nvars是培训数据中的变量(列)的数量。如果您使用预测值的表培训集合,那么 |
|
尺寸谈判array of response data. Elements of |
Examples
袋装分类树的列车集合
Load Fisher's iris data set.
加载渔民
Train an ensemble of bagged classification trees using the entire data set. Specify50weak learners. Store which observations are out of bag for each tree.
RNG(1);% For reproducibilitymdl = treebagger(50,meas,speies,'OOBPrediction'那'上'那。。。'Method'那'classification')
MDL = TreeBagger合奏与50个袋装决策树:训练X:[150x4]训练Y:[150x1]方法:分类NumPredictors:4 NumPredictorstosample:2 minleafsize:1个土松效:1个样品释放:1 ComputeOobprediction:1 ComputeOobpredictorImportance:[]ClassNames:'Setosa''Versicolor''Virginica'属性,方法
MDL.是atreebaggerensemble.
MDL.。树木stores a 50-by-1 cell vector of the trained classification trees (CompactClassificationTree.模型对象)构成合奏。
Plot a graph of the first trained classification tree.
view(Mdl.Trees{1},'模式'那'graph')

默认,treebagger生长深沉的树木。
mdl.oobindices.stores the out-of-bag indices as a matrix of logical values.
Plot the out-of-bag error over the number of grown classification trees.
数字;Ooberrorbaggedensemble = OobError(MDL);绘图(Ooberrorbaggedensemble)Xlabel'成长树数';ylabel'Out-of-bag classification error';
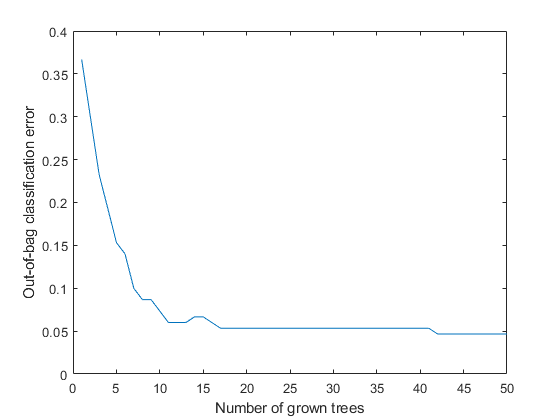
该out-of-bag error decreases with the number of grown trees.
To label out-of-bag observations, passMDL.T.ooobPredict。
袋装回归树的火车合奏
Load theCarsmall.data set. Consider a model that predicts the fuel economy of a car given its engine displacement.
加载Carsmall.
Train an ensemble of bagged regression trees using the entire data set. Specify 100 weak learners.
RNG(1);% For reproducibilityMDL.= TreeBagger(100,Displacement,MPG,'Method'那'regression');
MDL.是atreebaggerensemble.
使用训练有素的回归树,您可以估计条件平均响应或执行量级回归以预测条件量数。
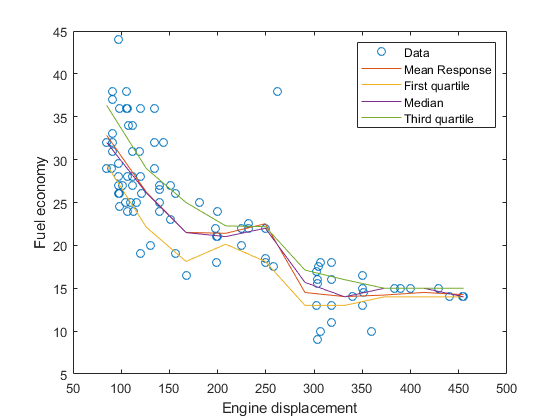
对于十个同等间隔的发动机位移在最小和最大的样本位移之间,预测有条件的平均响应和条件四分位数。
predX = linspace(min(Displacement),max(Displacement),10)'; mpgMean = predict(Mdl,predX); mpgQuartiles = quantilePredict(Mdl,predX,'standile',[0.25,0.5,0.75]);
Plot the observations, and estimated mean responses and quartiles in the same figure.
数字;情节(位移,MPG,'o');保持上plot(predX,mpgMean); plot(predX,mpgQuartiles); ylabel('燃油经济');Xlabel('Engine displacement');legend('Data'那'Mean Response'那'第一个四分位数'那'中位'那'Third quartile');
无偏见的预测性重视估计
Load theCarsmall.data set. Consider a model that predicts the mean fuel economy of a car given its acceleration, number of cylinders, engine displacement, horsepower, manufacturer, model year, and weight. ConsiderCylinders那MFG.,和Model_Year作为分类变量。
加载Carsmall.汽缸=分类(圆柱);MFG =分类(CellStr(MFG));model_year =分类(model_year);X =表(加速,圆柱,位移,马力,MFG,。。。model_year,重量,mpg);RNG('default');% For reproducibility
显示分类变量中表示的类别数。
num cinders = numel(类别(圆柱体))
numCylinders = 3
nummfg = numel(类别(MFG))
nummfg = 28.
numModelYear = numel(categories(Model_Year))
nummodelyear = 3
B.ecause there are 3 categories only inCylinders和Model_Year,这standard CART, predictor-splitting algorithm prefers splitting a continuous predictor over these two variables.
Train a random forest of 200 regression trees using the entire data set. To grow unbiased trees, specify usage of the curvature test for splitting predictors. Because there are missing values in the data, specify usage of surrogate splits. Store the out-of-bag information for predictor importance estimation.
MDL.= TreeBagger(200,X,'mpg'那'Method'那'regression'那'Surrogate'那'上'那。。。'预测圈'那'曲率'那'OOBPredictorImportance'那'上');
treebagger在物业中存储预测原则重要性估计OOBPermutedPredictorDeltaError。使用条形图比较估计值。
一世mp = Mdl.OOBPermutedPredictorDeltaError; figure; bar(imp); title('Curvature Test');ylabel('Predictor importance estimates');Xlabel('预测器');H = GCA;h.xticklabel = mdl.predictornames;H.xticklabelrotation = 45;H.TicklabelInterpreter =.'没有';
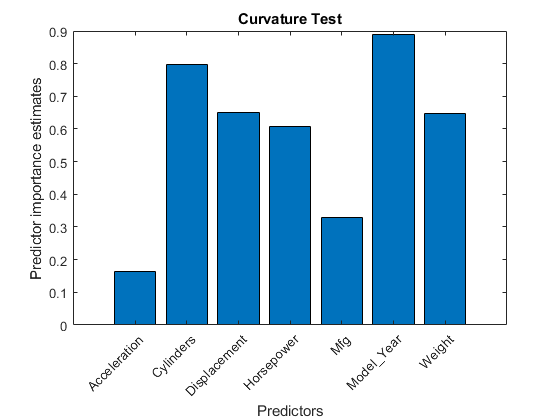
In this case,Model_Year是T.he most important predictor, followed by重量。
比较一世mpT.o predictor importance estimates computed from a random forest that grows trees using standard CART.
mdlcart = treebagger(200,x,'mpg'那'Method'那'regression'那'Surrogate'那'上'那。。。'OOBPredictorImportance'那'上');一世mpCART = MdlCART.OOBPermutedPredictorDeltaError; figure; bar(impCART); title('标准购物车');ylabel('Predictor importance estimates');Xlabel('预测器');H = GCA;h.xticklabel = mdl.predictornames;H.xticklabelrotation = 45;H.TicklabelInterpreter =.'没有';
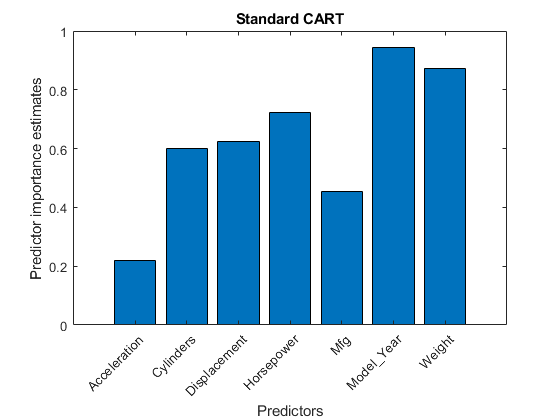
In this case,重量是一个连续的预测因子,是最重要的。接下来的两个最重要的预测因子是Model_Yearfollowed closely by马力那which is a continuous predictor.
Copy Semantics
值。要了解这会如何影响您对类的使用,请参阅Comparing Handle and Value Classes(Matlab)在Matlab中®面向对象的编程文档。
小费s
For atreebagger模型对象B.,这树木property stores a cell vector ofB.numtrees.CompactClassificationTree.要么Compactregressiontree.模型对象s. For a textual or graphical display of treeT.一世n the cell vector, enter
view(B.Trees{T.})
替代功能
统计和机器学习工具箱™为袋装和随机森林提供三个物体:
ClassificationBaggedEnsemble由...制作fitcensemble用于分类回归释迦缩短由...制作fitrensemble.回归treebagger由...制作treebagger用于分类和回归
有关差异之间的详细信息treebagger和袋装合奏(ClassificationBaggedEnsemble和回归释迦缩短)那seeTreeBagger和Bagged Senembles的比较。
References
[1] Breiman,L.随机森林。机器学习45,pp。5-32,2001。
[2]Meinshausen, N. “Quantile Regression Forests.”机床学习研究,卷。7,2006,第983-999页。
选择一个网站
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select:。
Select网站您还可以从以下列表中选择一个网站:
美洲
- 一种mérica Latina(Español)
- 加拿大(English)
- 美国(English)
欧洲
- Netherlands(English)
- 挪威(English)
- Österreich.(德意志)
- 葡萄牙(English)
- Sweden(English)
- 瑞士
- United Kingdom(English)
一种sia Pacific
- 一种ustralia(English)
- 印度(English)
- New Zealand(English)
- 中国
- 日本语(日本語)
- 한국(한국어)
