OOBQUANTILEPREDICT
班级:treebagger
从袋子袋袋中观测到回归树的分量预测
句法
描述
输入参数
输出参数
例子
使用量子回归预测袋袋中的中位数
加载Carsmall.数据集。考虑一种模型,该模型在鉴于其发动机位移给出汽车的燃料经济性(以MPG)。
加载Carsmall.
使用整个数据集培训袋装回归树的集合。指定100名弱学习者并保存出袋子索引。
RNG(1);重复性的%mdl = treebagger(100,位移,mpg,'方法'那'回归'那......'Oobprediction'那'上');
MDL.是A.treebagger合奏。
执行量级回归以预测所有培训观察的袋装中位燃料经济性。
Oobmedianmpg = OOBQUANTILEPREDICT(MDL);
Oobmedianmpg.是一个N- 给出了对应于响应的条件分布的中位数的1个数字矢量给出了分类的观察mdl.x.。N是观察的数量,尺寸(mdl.x,1)。
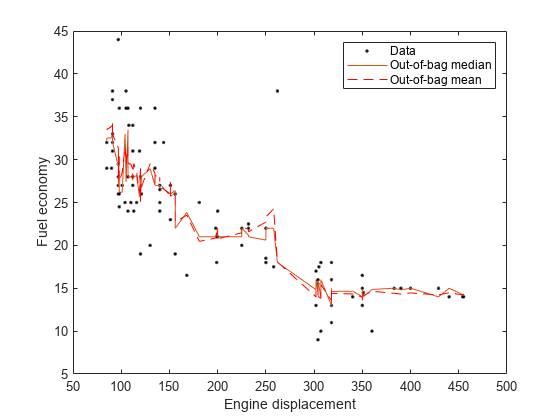
按升序对观察进行排序。绘制同一个数字的观察和估计的中位数。比较袋子外中位数和平均反应。
[sx,idx] = sort(mdl.x);Oobmeanmpg = Oobpredict(MDL);数字;情节(位移,MPG,'k。');抓住上图(SX,OOBMEDIANMPG(IDX));绘图(SX,OobmeAnmpg(IDX),'r--');ylabel('燃油经济');Xlabel('发动机排量');传奇('数据'那'袋子中位数'那'袋子意味着');抓住离开;
使用百分比估计袋袋预测间隔
加载Carsmall.数据集。考虑一种模型,该模型预测汽车(MPG)的燃料经济性给出其发动机位移。
加载Carsmall.
使用整个数据集培训袋装回归树的集合。指定100名弱学习者并保存出袋子索引。
RNG(1);重复性的%mdl = treebagger(100,位移,mpg,'方法'那'回归'那......'Oobprediction'那'上');
执行量级回归以预测袋子外的2.5%和97.5%百分比。
OOBQUANTPREDINTS = OOBQUANTILEPREDICT(MDL,'standile',[0.025,0.975]);
Oobquantpredints.是一个N-2-2数值矩阵对应于袋外观察的预测间隔mdl.x.。N是观察人数,尺寸(mdl.x,1)。第一列包含2.5%百分比,第二列包含97.5%百分位数。
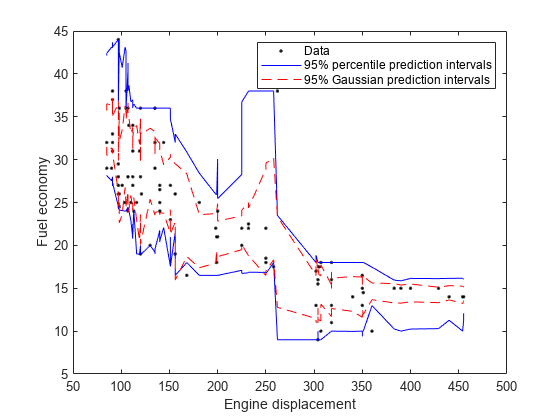
绘制同一个数字的观察和估计的中位数。比较百分点预测间隔和95%的预测间隔,假设条件分布MPG.是高斯。
[Oobmeanmpg,OobstealeAnmpg] = Oobpredict(MDL);STDNPREDINTS = OOBMEANMPG + [-1 1] * NORMINV(0.975)。* OOBSTEMEANMPG;[sx,idx] = sort(mdl.x);数字;H1 =图(位移,MPG,'k。');抓住上h2 = plot(sx,oobquantpredints(idx,:),'B');h3 = plot(sx,stdnpredints(idx,:),'r--');ylabel('燃油经济');Xlabel('发动机排量');图例([H1,H2(1),H3(1)],{'数据'那'95%百分位预测间隔'那......'95%高斯预测间隔'});抓住离开;
使用量子回归估计袋袋条有条件的累积分布
加载Carsmall.数据集。考虑一种模型,该模型预测汽车(MPG)的燃料经济性给出其发动机位移。
加载Carsmall.
使用整个数据集培训袋装回归树的集合。指定100个弱的学习者并保存禁止外索引。
RNG(1);重复性的%mdl = treebagger(100,位移,mpg,'方法'那'回归'那......'Oobprediction'那'上');
估计禁止袋响应权重。
[〜,YW] = OOBQUANTILEPREDICT(MDL);
yw.是包含响应权重的N-by n稀疏矩阵。N是培训观察的数量,numel(y)。观察的响应权重mdl.x(j,:)是yw(:,j)。响应权重独立于任何指定的分位式概率。
估计答复的袋子外,条件累积分配函数(CCDF):
排序响应是升序顺序,然后使用通过对响应进行排序引起的索引来排序响应权重。
计算排序响应权重的每列上的累积和。
[sorty,sortidx] = sort(mdl.y);cpdf = full(yw(sortIdx,:));ccdf = cumsum(cpdf);
CCDF(:,j)是响应的经验外禁止CCDF,给予观察j。
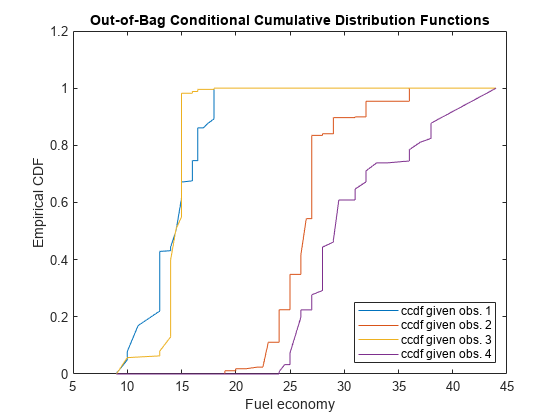
选择四种培训观察的随机样本。绘制训练样本并确定所选的观察。
[randx,IDX] =数据征(MDL.x,4);数字;绘图(mdl.x,mdl.y,'o');抓住上绘图(RANDX,MDL.Y(IDX),'*'那'Markersize',10);文本(RANDX-10,MDL.Y(IDX)+1.5,{'Obs。1''Obs。2''Obs。3''Obs。4'});传奇('培训数据'那'选择观察');Xlabel('发动机排量')ylabel('燃油经济') 抓住离开

为同一图中的四个所选响应绘制袋子外CCDF。
数字;绘图(Sorty,CCDF(:,IDX));传奇('CCDF给予OBS。1'那'CCDF给予OBS。2'那......'CCDF给予OBS。3'那'CCDF给予OBS。4'那......'地点'那'东南') 标题('袋不良条件累积分配功能')xlabel('燃油经济')ylabel('经验CDF')
更多关于
算法
OOBQUANTILEPREDICT通过申请估计袋子超定量standilepredict.致培训数据的所有观察(mdl.x.)。对于每个观察,该方法仅使用观察袋的树木。
对于在集合中所有树木的袋子的观察,OOBQUANTILEPREDICT分配响应数据的样本量级。换句话说,OOBQUANTILEPREDICT不使用量子回归进行袋袋的观察。相反,它分配smianile(mdl.y,, 在哪里TAU)TAU是值的价值斯蒂利韦名称值对参数。
参考
[1] Meinshausen,N。“斯蒂利回归森林。”机床学习研究,卷。7,2006,第983-999页。
[2] Breiman,L。“随机森林。”机器学习。卷。45,2001,第5-32页。
您还可以从以下列表中选择一个网站:
