quantilePredict
班级:TreeBagger
使用袋子回归树预测响应量子
语法
描述
输入参数
输出参数
例子
预测培训样品中位数
加载Carsmall.数据集。考虑一种模型,该模型预测汽车的发动机位移的燃油经济性。
负载Carsmall.
使用整个数据集培训袋装回归树的集合。指定100个弱的学习者。
RNG(1);重复性的%mdl = treebagger(100,位移,mpg,'方法','回归');
MDL.是A.TreeBagger合奏。
执行量级回归以预测所有分类培训观察的中位MPG。
medianMPG = quantilePredict (Mdl、排序(位移));
中美洲是一个n- 给出了对应于响应的条件分布的中位数的1个数字矢量给出了分类的观察移位.n观察的次数在吗移位.
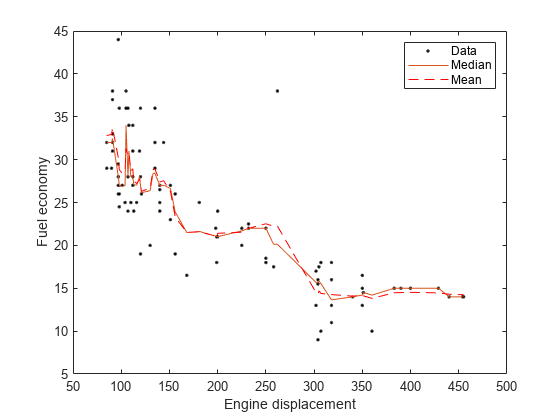
绘制同一个数字的观察和估计的中位数。比较中位数和均值的反应。
Makmpg =预测(MDL,Sort(位移));数字;情节(位移,MPG,'k。');抓住在情节((位移),medianMPG);情节(排序(位移)、meanMPG'r--');ylabel(的燃油经济性);包含('发动机排量');传奇('数据',“中值”,'意思');抓住离开;
使用百分位数估计预测区间
加载Carsmall.数据集。考虑一种模型,该模型预测汽车的发动机位移的燃油经济性。
负载Carsmall.
使用整个数据集培训袋装回归树的集合。指定100个弱的学习者。
RNG(1);重复性的%mdl = treebagger(100,位移,mpg,'方法','回归');
执行量级回归以预测最小和最大样本位移之间的十个同等间隔发动机位移的2.5%和97.5%百分比。
predX = linspace (min(位移),max(位移),10)';quantPredInts = quantilePredict (Mdl predX,分位数的[0.025, 0.975]);
Quantpredints.是一个10×2的数字矩阵,对应于观察的预测间隔predX.第一列包含2.5%百分比,第二列包含97.5%百分比。
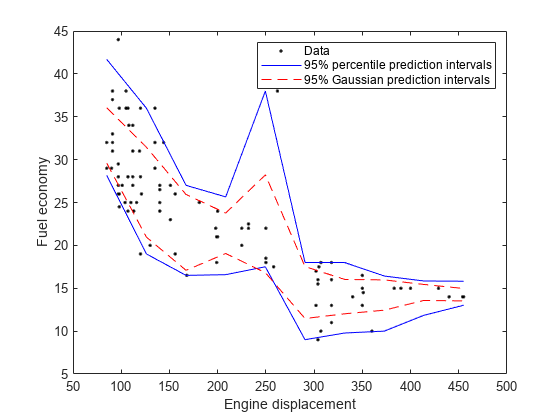
绘制同一个数字的观察和估计的中位数。比较百分位预测间隔和95%预测间隔假设条件分布MPG.是高斯。
[意思是,stemeanmpg] =预测(mdl,predx);STNDPREDINTS = MASHMPG + [-1 1] * NORMINV(0.975)。* stemeanmpg;数字;H1 =图(位移,MPG,'k。');抓住在h2 = plot(predx,quartpredints,'B');h3 = plot(predx,stndpredints,'r--');ylabel(的燃油经济性);包含('发动机排量');图例([H1,H2(1),H3(1)],{'数据','95%百分位预测间隔',......'95%高斯预测间隔'});抓住离开;
估计使用量子回归的条件累积分布
加载Carsmall.数据集。考虑一种模型,该模型预测汽车的发动机位移的燃油经济性。
负载Carsmall.
使用整个数据集培训袋装回归树的集合。指定100个弱的学习者。
RNG(1);重复性的%mdl = treebagger(100,位移,mpg,'方法','回归');
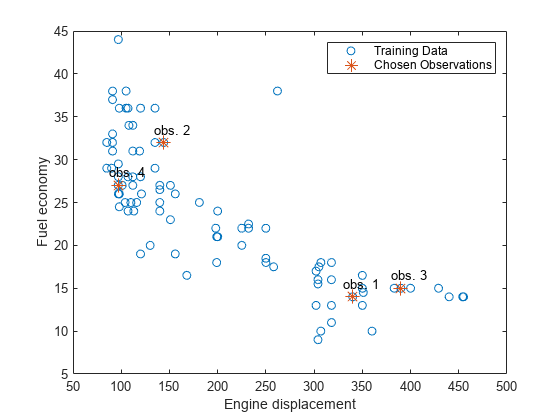
估计四种训练观察的随机样本的响应权重。绘制训练样本并确定所选的观察。
[predx,idx] = dataMple(mdl.x,4);[〜,YW] = SmianilePredict(MDL,Predx);n = numel(mdl.y);数字;绘图(mdl.x,mdl.y,'o');抓住在plot(predx,mdl.y(idx),'*','Markersize',10);文本(predx-10,mdl.y(idx)+1.5,{'Obs。1''Obs。2''Obs。3''Obs。4 '});传奇('培训数据',“选择观察”);包含('发动机排量')ylabel(的燃油经济性) 抓住离开
yw.是一个n-4稀疏矩阵,包含响应权值。列对应于测试观察值,行对应于训练样本中的响应。响应权值独立于指定的分位数概率。
估计答复的条件累积分配函数(C.C.D.F.):
排序响应是升序顺序,然后使用通过对响应进行排序引起的索引来排序响应权重。
计算排序响应权重的每列上的累积和。
[sorty,sortidx] = sort(mdl.y);cpdf = full(yw(sortIdx,:));ccdf = cumsum(cpdf);
ccdf (:, j)是经验的C.C.D.F.给定考察观察的响应j.
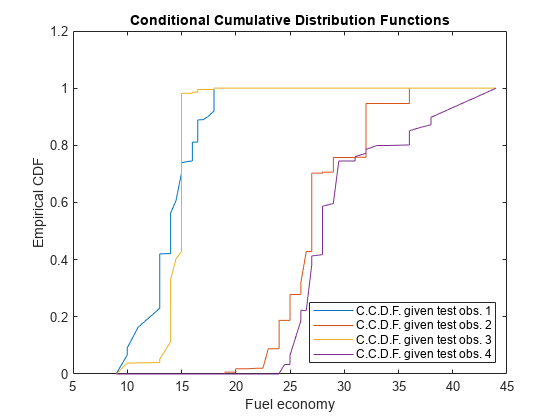
绘制四个经验的C.C.F.F.在同一个图中。
数字;情节(Sorty,CCDF);传奇(" C.C.D.F.做了检查。1'," C.C.D.F.做了检查。2',......" C.C.D.F.做了检查。3'," C.C.D.F.做了检查。4 ',......'地点','东南') 标题('有条件累积分配功能')Xlabel(的燃油经济性)ylabel(“经验提供”)
更多关于
提示
quantilePredict每次调用它时都会使用培训数据估算响应的条件分布。要有效地预测许多定量,或者有效地定量许多观察结果,您应该通过X作为观察的矩阵或表格,并使用载体中的所有定量使用分位数名称-值对的论点。也就是说,避免呼唤quantilePredict在一个循环。
算法
TreeBagger使用训练数据增长回归树的随机森林。然后,实施斯蒂利随机森林,quantilePredict使用响应的经验条件分布预测定量,给出了预测变量的观察。获得响应的经验条件分布:这个过程描述了
quantilePredict使用所有指定的权重。所有训练观察j= 1,......,n和所有选中的树t= 1,......,T,
quantilePredict产品属性vTJ.=bTJ.wj,Obs.训练观察j(存储在mdl.x.(和j:)mdl.y.().bTJ.是观察的次数j是否在树的引导样本中t.wj,Obs.观察权重在吗j)mdl.w.(.j)对于每个选择的树,
quantilePredict识别每个训练观察落下的叶子。让年代t(xj)是包含在树叶子中的所有观察值的集合t的观察j是会员。对于每个选择的树,
quantilePredict将特定叶片内的所有重量标准化为1,即对于每个训练观察和树,
quantilePredict包含树权重(wt,树)指定的TreeWeights, 那是,w*TJ.,树=wt,树vTJ.*未被选择用于预测的树的权重为0。所有测试观察k= 1,......,K在
X和所有选中的树t= 1,......,TquantilePredict预测观察结果下降的独特叶子,然后识别预测叶片内的所有培训观察。quantilePredict属于重量uTJ.这样quantilePredict将重量汇总所有所选树木,即,quantilePredict通过归一化权重创建响应权重,使得它们总和为1,即,
参考
[1] Breiman,L。“随机森林。”机器学习45,pp。5-32,2001。
[2] Meinshausen,N。“斯蒂利回归森林。”机器学习研究杂志,第7卷,2006年,第983-999页。
您还可以从以下列表中选择一个网站:
