主要内容
开始主题建模
此示例显示如何将主题模型拟合到文本数据并可视化主题。
潜在的Dirichlet分配(LDA)模型是一个主题模型,用于在文件集中发现底层主题。主题,其特征在于单词的分布,对应于通常共同的单词组。LDA是一个无人监督的主题模型,这意味着它不需要标记数据。
加载和提取文本数据
加载示例数据。文件factoryreports.csv.包含出厂报告,包括每个事件的文本描述和分类标签。
使用该数据导入数据可阅读函数并从中提取文本数据描述柱子。
filename =.“factoryreports.csv”;数据= readtable(文件名,'texttype'那'细绳');textdata = data.description;
准备分析的文本数据
令垂化和预处理文本数据并创建一个单词袋式模型。
授权文本。
文档= tokenizeddocument(textdata);
为了改进模型拟合,从文档中删除标点符号和“和”,“和”“和”“)的标点符号(如”)的标点符号。
文档= Removestopwords(文件);文件=侵蚀(文件);
创建一个单词袋式模型。
bag = bagofwords(文件);
适合LDA模型
适合使用七个主题的LDA模型菲达功能。要抑制详细输出,请设置'verbose'选择0.。
numtopics = 7;mdl = fitlda(袋子,numtopics,'verbose',0);
可视化主题
使用Word云可视化前四个主题。
数字为了TopicIDX = 1:4子图(2,2,TopicIDX)WordCloud(MDL,TopicIDX);标题(“话题 ”+ topicidx)结尾
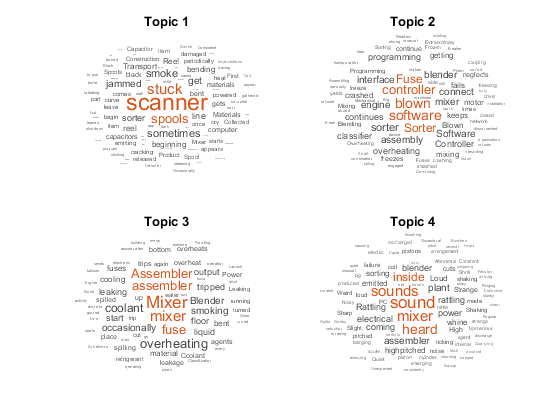
对于文本分析中的后续步骤,您可以尝试通过使用不同的预处理步骤来改进模型拟合并可视化主题混音。例如,看到使用主题模型分析文本数据。
也可以看看
Bagofwords.|侵蚀|菲达|Removestopwords.|令人畏缩的鳕文|WordCloud.
相关话题
您还可以从以下列表中选择一个网站:
