semanticseg
基于深度学习的语义图像分割
句法
描述
pxds= semanticseg(DS.,网络)DS.,数据存储对象。
该功能支持使用多个MATL金宝appAB的并行计算®工人。您可以使用以下方式启用并行计算计算机视觉工具箱首选项对话框。
[___] = semanticseg(___,通过一个或多个名称值对参数指定的其他选项返回语义分段。名称,值)
例子
语义图像分割
在图像上叠加分割结果并显示结果。
加载备用网络。
data =负载('trianglesemationnetwork');net = data.net.
net = SeriesNetwork with properties: Layers: [10x1 net.cnn.layer. layer] InputNames: {'imageinput'} OutputNames: {'classoutput'}
列出网络层。
net.layers.
ANS = 10x1层阵列,带有层数:1'ImageInput'图像输入32x32x1图像与“Zerocenter”归一化2'CONC_1'卷积64 3x3x1卷绕卷曲[1 1]和填充[1 1 1 1] 3'Relu_1'Relu Relu 4“MaxPool”最大池2X2 MAX汇集步进[2 2]和填充[0 0 0 0] 5'CONC_2'卷积64 3x3x64卷绕卷曲[1 1]和填充[1 1 1 1] 6'Relu_2'Relu Relu7'转置-Cron'转换卷积64 4x4x64转向卷绕升降卷曲[2 2]和裁剪[1 1 1 1] 8'conv_3'卷积2 1x1x64卷曲的卷发[11]和填充[0 0 0 0] 9'softmax'softmax softmax 10'classoctput'像素分类层类加权交叉熵丢失,课程“三角形”和“背景”
读取并显示测试图像。
我= imread('triangletest.jpg');图imshow(我)
执行语义图像分割。
[c,scores] = semanticseg(i,net,“MiniBatchSize”、32);
将分割结果叠加在图像上并显示。
B = labeloverlay(I, C);图imshow (B)

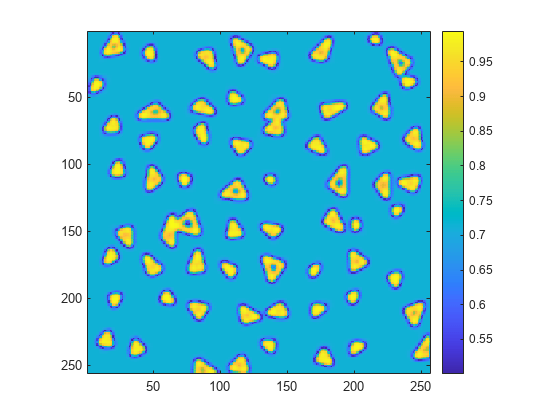
显示分类分数。
图ImageC(分数)轴正方形colorbar
创建一个只有三角形的二元遮罩。
Bw = c =='三角形';图imshow (BW)

评估语义分割测试集
对一组测试图像进行语义分割,并将分割结果与地面真实数据进行比较。
加载备用网络。
data =负载('trianglesemationnetwork');net = data.net;
负载测试图像使用imageDatastore.
datadir = fullfile(toolboxdir(“愿景”),'VisionData',“triangleImages”);testimagedir = fullfile(datadir,“testImages”);IMDS = ImageageAtastore(testimagedir)
images:{'…/toolbox/vision/visiondata/triangleImages/ testestimages /image_001.jpg';’……/工具箱/视觉/ visiondata / triangleImages / testImages / image_002.jpg”;’……/工具箱/视觉/ visiondata / triangleImages / testImages / image_003.jpg”……和97个更多的}文件夹:{'…/build/matlab/toolbox/vision/visiondata/triangleImages/testImages'} alteratefilesystemroots: {} ReadSize: 1标签:{}Supported金宝appOutputFormats: ["png" "jpg" "jpeg" "tif" "tiff"] DefaultOutputFormat: "png" ReadFcn: @readDatastoreImage
负载地面真值测试标签。
testlabeldir = fullfile(Datadir,'testlabels');一会= [“三角形”“背景”];pixelLabelID = [255 0];一会,pxdsTruth = pixelLabelDatastore (testLabelDir pixelLabelID);
在具有批量大小的所有测试图像上运行语义分割。您可以增加批量大小以增加基于系统内存资源的吞吐量。
pxdsResults = semanticseg (imd,净,“MiniBatchSize”,4,'writeelocation',Tempdir);
运行的语义分割网络 ------------------------------------- * 100张图片处理。
将结果与实际情况进行比较。
指标= evaluateSemanticSegmentation (pxdsResults pxdsTruth)
---------------------------------------- *选择指标:全局准确率,类准确率,IoU,加权IoU, BF评分。*处理100张图片。*完成……完成了。*数据集指标:GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore ______________ ____________ _______ ___________ ___________ 0.90624 0.95085 0.61588 0.87529 0.40652
metrics =具有属性的语义发行级别:confusionmatrix:[2x2表] normalizedconfusionmatrix:[2x2表] datasetmetrics:[1x5表]类测量仪:[2x3表] ImageMetrics:[100x5表]
使用TVERSKY丢失定义自定义像素分类层
这个例子展示了如何定义和创建一个使用Tversky损失的自定义像素分类层。
该层可用于训练语义分割网络。要了解更多关于创建自定义深度学习层的信息,请参见定义自定义深度学习层(深度学习工具箱).
特沃斯基损失
特沃斯基损耗是基于测量两幅分割图像重叠的特沃斯基指数[1]。TVERSKY索引 在一个图像之间 和相应的地面真相 是(谁)给的
对应于类和 相当于不上课 .
沿着的前两个维度的元素数是多少 .
和 控制每个班级的假阳性和假否定的贡献是对损失的加权因素。
损失 除以类的数量 是(谁)给的
分类层模板
复制分类层模板到一个新的文件在MATLAB®。此模板概述了分类层的结构,并包括定义该层行为的函数。示例的其余部分展示了如何完成TVERSKYPIXELCLASERICINCIONLAYER..
Classdef.tverskyPixelClassificationLayer < nnet.layer.ClassificationLayer特性%可选属性结束方法功能loss = forwardLoss(layer, Y, T)%层前向损失功能到这里结束结束结束
声明层属性
默认情况下,自定义输出层有以下属性:
名称层名,指定为字符向量或字符串标量。若要在层图中包含此层,必须指定非空的唯一层名。如果你用这一层训练一系列网络名称被设置为'',然后软件会在训练时自动指定一个名字。描述-层的单行描述,指定为字符向量或字符串标量。该描述出现在层显示在层数组中。如果不指定层描述,则软件将显示层类名称。类型- 图层的类型,指定为字符向量或字符串标量。的价值类型当图层显示在一个中时出现层数组中。如果未指定图层类型,则软件显示“分类层”要么'回归层'.
自定义分类层也有以下属性:
班级-输出层的类,指定为分类向量、字符串数组、字符向量单元数组或“汽车”.如果班级是“汽车”,然后软件在训练时自动设置课程。如果指定字符向量的字符串数组或单元格数组str.,然后软件将输出层的类设置为分类(str,str).默认值为“汽车”.
如果图层没有其他属性,那么您可以省略特性部分。
特沃斯基损失需要一个小的常数值,以防止被零除掉。指定属性,ε,以保持该值。它还需要两个变量属性Alpha和bet分别控制假阳性和假阴性的权重。
Classdef.tverskyPixelClassificationLayer < nnet.layer.ClassificationLayer特性(持续的)%小常数,以防止分割零。ε= 1 e-8;结束特性%默认的假阳性和假阴性加权系数alpha = 0.5;beta = 0.5;结束......结束
创建构造函数
创建构建图层并初始化图层属性的函数。指定将图层创建为构造函数的输入所需的任何变量。
指定要分配给的可选输入参数名称名称创作的财产。
功能图层= tverskyPixelClassificationLayer(name, alpha, beta)%layer = tverskypixelclassificationlayer(name)创建一个tversky具有指定名称的%像素分类层。设置图层名称层。名称=name;%设置图层属性层。α=α;层。bet=beta;%设置图层描述layer.description =.“特沃斯基损失”;结束
创建前向损耗功能
创建一个名为forwardLoss这返回网络和培训目标的预测之间的加权交叉熵损失。语法forwardLoss是损失= forwardLoss(层,Y, T),在那里Y前一层的输出是和吗T代表培训目标。
对于语义分割问题,尺寸为T匹配维度Y,在那里Y是一个4 d尺寸H——- - - - - -W——- - - - - -K——- - - - - -N,在那里K是班数,和N是迷你批量尺寸。
的大小Y取决于前一层的输出。为了保证Y大小是一样的吗T,您必须包含一个在输出层之前输出正确尺寸的图层。例如,确保Y4-D数组的预测得分是什么K类,您可以包含完全连接的大小层K或卷积层K过滤器后跟输出层之前的软MAX层。
功能loss = forwardLoss(layer, Y, T)% loss = forwardLoss(layer, Y, T)返回Tversky loss between%预测y和训练目标t。Pcnot = 1 y;Gcnot = 1 - t;TP =总和(总和(y * T, 1), 2);FP =总和(总和(y * Gcnot, 1), 2);FN =总和(总和(Pcnot。* T, 1), 2);number = TP + layer.Epsilon;denom = TP + layer。α* FP +层。bet*FN + layer.Epsilon;%compute tversky索引losstic = 1 - 数值/denom;lossti = sum(losstic,3);回报率平均特沃斯基指数损失n =尺寸(y,4);损失=总和(LOSSTI)/ n;结束
落后的损失函数
作为forwardLoss功能完全支持自动差异化,不需要金宝app为向后丢失创建功能。
有关支持自动区分的函数列表,请参见金宝app支持dlarray的函数列表金宝app(深度学习工具箱).
完成一层
所述完成层提供于tverskyPixelClassificationLayer.m.
Classdef.tverskyPixelClassificationLayer < nnet.layer.ClassificationLayer%此图层实现了用于培训的TVERSKY丢失功能%语义分割网络。% 参考%Salehi,Seyed Sadegh Mohseni,Deniz Erdogmus和Ali Ghotipour。% "Tversky损失函数的图像分割使用3D充分%卷积的深网络。“机器国际研讨会医学成像学习。Springer,Cham,2017。%----------特性(持续的)%小常数,以防止分割零。ε= 1 e-8;结束特性%默认权重系数为假阳性和假%否定alpha = 0.5;beta = 0.5;结束方法功能图层= tverskyPixelClassificationLayer(name, alpha, beta)%layer = tverskypixelclassificationlayer(名称,alpha,beta)创建一个tversky具有指定名称和属性Alpha和Beta的%像素分类层。%设置图层名称。层。名称=name; layer.Alpha = alpha; layer.Beta = beta;%设置图层描述。layer.description =.“特沃斯基损失”;结束功能loss = forwardLoss(layer, Y, T)% loss = forwardLoss(layer, Y, T)返回Tversky loss between%预测y和训练目标t。Pcnot = 1 y;Gcnot = 1 - t;TP =总和(总和(y * T, 1), 2);FP =总和(总和(y * Gcnot, 1), 2);FN =总和(总和(Pcnot。* T, 1), 2);number = TP + layer.Epsilon;denom = TP + layer。α* FP +层。bet*FN + layer.Epsilon;%compute tversky索引losstic = 1 - 数值/denom;lossti = sum(losstic,3);回报率平均特沃斯基指数损失。n =尺寸(y,4);损失=总和(LOSSTI)/ n;结束结束结束
GPU的兼容性
使用的MATLAB功能forwardLoss在TVERSKYPIXELCLASERICINCIONLAYER.所有的支金宝app持GPUArray.输入,所以该层是GPU兼容的。
检查输出层有效性
创建图层的实例。
tallay = tverskypixelclassificationlayer('tversky', 0.7, 0.3);
使用checkLayer(深度学习工具箱).将有效的输入大小指定为单个观察到图层的单个观察的大小。图层期待一个H——- - - - - -W——- - - - - -K——- - - - - -N数组的输入,K是班数,和N是迷你批处理中的观察数。
numClasses = 2;validInputSize = [4 4 numClasses];validInputSize checkLayer(层,“ObservationDimension”4)
跳过GPU测试。没有找到兼容的GPU设备。跳过代码生成兼容性测试。要检查代码生成层的有效性,请指定“CheckCodegenCompatibility”和“ObservationDimension”选项。运行nnet.checklayer.TestOutputLayerWithoutBackward……完成nnet.checklayer.TestOutputLayerWithoutBackward __________测试摘要:8通过,0失败,0不完整,2跳过。时间:1.5279秒。
测试摘要报告通过、失败、不完整和跳过的测试的数量。
在语义分割网络中使用自定义层
创建一个使用该网络的语义分段网络TVERSKYPIXELCLASERICINCIONLAYER..
图层= [imageInputlayer([32 32 1])卷积2dlayer(3,64,“填充”,1) batchNormalizationLayer reluLayer maxPooling2dLayer(2,'走吧',2)卷积2dlayer(3,64,“填充”64年,1)reluLayer transposedConv2dLayer(4日,'走吧'2,“种植”,1)Convolution2dlayer(1,2)SoftMaxLayer TVERSKYPIXELCLASICINGYLAYER('tversky',0.3,0.7)]
图层数组:1”的形象输入32 x32x1图像zerocenter正常化2”64 3 x3的卷积,卷积步伐[1]和填充[1 1 1 1]3“批量标准化批量标准化4”ReLU ReLU 5”麦克斯池2 x2马克斯池步(2 - 2)和填充[0 0 0 0]6”64 3 x3的卷积,卷积步伐[1]和填充[1 1 1 1]7 '' ReLU ReLU 8 '' Transposed Convolution 64 4x4 transposed convolutions with stride [2 2] and cropping [1 1 1 1] 9 '' Convolution 2 1x1 convolutions with stride [1 1] and padding [0 0 0 0] 10 '' Softmax softmax 11 'tversky' Classification Output Tversky loss
负载训练数据用于语义分割imageDatastore和PixellabeldAtastore..
datasetdir = fullfile(toolboxdir(“愿景”),'VisionData',“triangleImages”);imagedir = fullfile(datasetdir,'培训码');labelDir = fullfile (dataSetDir,'训练标签');imd = imageDatastore (imageDir);一会= [“三角形”“背景”];labelids = [255 0];pxds = pixellabeldataStore(Labeldir,ClassNames,LabelIds);
通过使用将图像和像素标记数据相关联pixelLabelImageDatastore.
ds = pixellabelimagedataStore(IMDS,PXD);
设置培训选项,培训网络。
选择= trainingOptions ('亚当',......“InitialLearnRate”,1e-3,......'maxepochs', 100,......“LearnRateDropFactor”, 5 e 1,......'学习ropperiod'20,......“LearnRateSchedule”,'分段',......“MiniBatchSize”,50);net = trainnetwork(ds,图层,选项);
单CPU训练。初始化输入数据规范化。|========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习 | | | | ( hh: mm: ss) | | |丧失准确性 | |========================================================================================| | 1 | 1 | 00:00:01 | | 1.2933 | 0.0010 50.32%||13 | 50 | 00:00:20 | 98.83% | 0.0987 | 0.0010 | | 25 | 100 | 00:00:39 | 99.33% | 0.0547 | 0.0005 | | 38 | 150 | 00:01:04 | 99.37% | 0.0473 | 0.0005 | | 50 | 200 | 00:01:25 | 99.48% | 0.0401 | 0.0003 | | 63 | 250 | 00:01:44 | 99.48% | 0.0384 | 0.0001 | | 75 | 300 | 00:02:05 | 99.54% | 0.0348 | 0.0001 | | 88 | 350 | 00:02:25 | 99.51% | 0.0352 | 6.2500e-05 | | 100 | 400 | 00:02:43 | 99.56% | 0.0330 | 6.2500e-05 | |========================================================================================|
通过分割测试图像并显示分割结果来评估训练的网络。
我= imread('triangletest.jpg');[c,得分] = SemanticSeg(I,Net);B = Labeloverlay(I,C);蒙太奇({i,b})
![]()
参考文献
[1] Salehi,Seyed Sadegh Mohseni,Deniz Erdogmus和Ali Ghotipour。“使用3D完全卷积的深网络的图像分割的TVERSKY损失功能。”医学影像中的机器学习国际研讨会.Springer,Cham,2017。
使用扩展卷积的语义分割
使用扩展卷积训练语义分割网络。
语义分割网络对图像中的每个像素进行分类,从而对图像进行分类。语义分割的应用包括用于自动驾驶的道路分割和用于医疗诊断的癌细胞分割。想要了解更多,请看使用深度学习开始语义分割.
像DeepLab[1]这样的语义分割网络广泛使用扩张卷积(也称为atrous卷积),因为它们可以增加层的接受域(层可以看到的输入区域),而不增加参数或计算的数量。
负荷训练数据
该示例使用32×32三角形图像的简单数据集以用于说明目的。数据集包括伴随像素标签地面真实数据。使用一个加载训练数据imageDatastoreA.PixellabeldAtastore..
datafolder = fullfile(toolboxdir(“愿景”),'VisionData',“triangleImages”);imageFolderTrain = fullfile (dataFolder,'培训码');labelfoldertrain = fullfile(datafolder,'训练标签');
创建一个imageDatastore的图像。
imdstrain = imageageataStore(imagefoldertrain);
创建一个PixellabeldAtastore.对于地面真值像素标签。
一会= [“三角形”“背景”];标签= [255 0];pxdstrain = pixellabeldataStore(LabelfoltTrain,ClassNames,标签)
pxdstrain = pixellabeldataStore与属性:文件:{200x1 cell} classNames:{2x1 cell} readsize:1 readfcn:@readdataStoreimage alternatefilesystemroots:{}
创建语义分段网络
此示例使用基于扩展卷积的简单语义分段网络。
为培训数据创建数据源,并获取每个标签的像素计数。
pximdsTrain = pixelLabelImageDatastore (imdsTrain pxdsTrain);台= countEachLabel (pxdsTrain)
台=2×3表名称pixelcount imagepixelcount ______________ _________________________ {'triangle'} 10326 2.048E + 05 {'背景'} 1.9447E + 05 2.048E + 05
大多数像素标签用于背景。这种阶级失衡使学习过程偏向于主导阶级。要解决这个问题,可以使用类权重来平衡类。可以使用几种方法来计算类权重。一种常见的方法是逆频率加权,其中类权重是类频率的倒数。这个方法增加了给予未表示的类的权重。使用反频率加权计算类别权重。
numberPixels =总和(tbl.PixelCount);频率=(资源。P我xelCount / numberPixels; classWeights = 1 ./ frequency;
通过使用与输入图像的大小对应的输入大小的图像输入层创建用于像素分类的网络。接下来,指定三个卷积块,批量标准化和Relu层。对于每个卷积层,指定32个3×3滤波器,随着扩张因子的增加并填充输入,使它们与输出相同,通过设置“填充”选择“相同”.要对像素进行分类,需要包含一个卷积层K1×1的卷积,K是类的数量,后跟一个softmax层和一个pixelClassificationLayer用相反的类权重。
inputSize = [32 32 1];filterSize = 3;numFilters = 32;numClasses =元素个数(类名);[imageInputLayer(inputSize)]卷积2dlayer (filterSize,numFilters,)“DilationFactor”, 1“填充”,“相同”) batchNormalizationLayer reluLayer卷积2dlayer (filterSize,numFilters,“DilationFactor”2,“填充”,“相同”) batchNormalizationLayer reluLayer卷积2dlayer (filterSize,numFilters,“DilationFactor”,4,“填充”,“相同”)BatchnormalizationLayer Rufulayer卷积2dlayer(1,numclasses)softmaxlayer pixelclasificationLayer('课程',classnames,“ClassWeights”,同等级)];
列车网络的
指定培训选项。
选择= trainingOptions ('sgdm',......'maxepochs',100,......“MiniBatchSize”, 64,......“InitialLearnRate”,1E-3);
使用培训网络trainNetwork.
net = trainnetwork(pximdstrain,图层,选项);
单CPU训练。初始化输入数据规范化。| ========================================================================================|时代|迭代|经过时间的时间迷你批量|迷你批量|基础学习| | | | (hh:mm:ss) | Accuracy | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:00 | 91.62% | 1.6825 | 0.0010 | | 17 | 50 | 00:00:20 | 88.56% | 0.2393 | 0.0010 | | 34 | 100 | 00:00:39 | 92.08% | 0.1672 | 0.0010 | | 50 | 150 | 00:00:57 | 93.17% | 0.1472 | 0.0010 | | 67 | 200 | 00:01:14 | 94.15% | 0.1313 | 0.0010 | | 84 | 250 | 00:01:33 | 94.47% | 0.1167 | 0.0010 | | 100 | 300 | 00:01:51 | 95.04% | 0.1100 | 0.0010 | |========================================================================================|
测试网络
加载测试数据。创建一个imageDatastore的图像。创建一个PixellabeldAtastore.对于地面真值像素标签。
imageFolderTest = fullfile (dataFolder,“testImages”);imdstest = imageageataStore(imagefoldertest);labelfoldertest = fullfile(datafolder,'testlabels');pxdstest = pixellabeldataStore(Labelfoldert,ClassNames,标签);
利用测试数据和训练网络进行预测。
pxdspred = semanticseg(Indstest,net,“MiniBatchSize”,32,'writeelocation',Tempdir);
运行的语义分割网络 ------------------------------------- * 100张图片处理。
使用预测精度评估预测精度评估评估.
metrics = evaluateManticSegation(PXDSPRED,PXDSTEST);
---------------------------------------- *选择指标:全局准确率,类准确率,IoU,加权IoU, BF评分。*处理100张图片。*完成……完成了。*数据集指标:GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore ______________ ____________ _______ ___________ ___________ 0.95237 0.97352 0.72081 0.92889 0.46416
有关评估语义分割网络的更多信息,请参见评估评估.
分段新映像
读取并显示测试图像triangleTest.jpg.
imgTest = imread ('triangletest.jpg');图imshow(imgtest)
段使用测试图像semanticseg并使用显示结果Labeloverlay..
C = semanticseg (imgTest,净);B = labeloverlay (imgTest C);图imshow (B)

输入参数
输出参数
扩展能力
另请参阅
功能
评估评估|Labeloverlay.|trainNetwork(深度学习工具箱)
应用
对象
ImageDatastore|PixellabeldAtastore.|dlnetwork.(深度学习工具箱)
主题
- 使用深度学习开始语义分割
- MATLAB中的深度学习(深度学习工具箱)
- 用于深度学习的数据存储(深度学习工具箱)
外部网站
您还可以从以下列表中选择一个网站:
