从加速度计数据裂缝识别
这个例子展示了如何使用小波和深度学习技术来检测横向路面裂缝和定位自己的位置。的例子演示了使用小波散射序列作为输入到一个封闭的复发性单元(格勒乌)和一维卷积网络分类时间序列基于裂纹的存在与否。数据从一个传感器安装在垂直加速度测量获得的悬浮关节副驾驶座上。早期识别发展横向裂缝对路面性能评价和维护很重要。可靠的自动检测方法使更频繁和广泛的监控。
请阅读数据描述和必需的归因在运行这个例子之前。所有的数据导入和预处理中描述数据导入和数据预处理部分。如果你想跳过训练测试集的创建,预处理,特征提取,和模型训练,你可以直接到分类和分析部分。你可以加载测试数据预处理以及提取的特征和训练模式。
数据描述和必需的归因
在本例中使用的数据是从Mendeley打开数据存储库中检索2]。数据分布在Creative Commons (CC) 4.0许可证。下载这个示例中使用的数据和模型在你的临时目录中指定的MATLAB®tempdir命令。如果您选择下载一个文件夹中的数据不同tempdir在随后的指令,改变目录的名字。将数据解压到一个文件夹指定为TransverseCrackData。
dataURL =“https://ssd.mathworks.com/金宝appsupportfiles/wavelet/crackDetection/transverse_crack.zip”;saveFolder = fullfile (tempdir,“TransverseCrackData”);zipFile = fullfile (tempdir,“transverse_crack.zip”);websave (zipFile dataURL);解压缩(zipFile saveFolder)
你解压缩数据后,TransverseCrackData文件夹包含一个子文件夹transverse_crack_latest。所有后续命令必须运行在这个文件夹中,或者你可以将这个文件夹matlabpath。
文本文件,vehiclevibrationdata.rights,包括在zip文件包含的文本CC 4.0许可证。数据已经从最初的Excel格式重新包装成mat文件。
数据采集是详细描述1]。十二个四米长的部分沥青包含位于横裂和十二个等长未裂开的部分。数据来自三个独立的道路。横向裂缝宽度从2 - 13毫米的裂缝间距编毫米。部分被赶在三个不同的速度:30公里/小时,40公里/小时,50公里/小时。垂直加速度测量从前面乘客悬挂关节获得1.28 kHz的采样频率。的速度30、40和50公里/小时对应传感器测量每6.5毫米在30公里/小时,在40公里/小时8.68毫米,10.85毫米在50公里/小时。参见[1)的详细分析的小波分析这些数据不同的这个例子。
符合规定的CC 4.0许可,我们注意到原始数据的速度信息是不保留在本例中使用的数据。的速度和道路信息是保留的road1.mat,road2.mat,road3.mat数据文件包含在数据文件夹的完整性。
数据下载并导入
加载加速度计数据及其对应的标签。有327个加速度计记录。
负载(fullfile (saveFolder“transverse_crack_latest”,“allroadData.mat”));负载(fullfile (saveFolder“transverse_crack_latest”,“allroadLabel.mat”));
数据预处理
获得所有的时间序列的长度。显示一个条形图的数量每长度时间序列。
tslen = cellfun (@length allroadData);uLen =独特(tslen);Ng = histcounts (tslen);Ng = Ng (Ng > 0);栏(uLen, Ng, 0.5)网格在甘氨胆酸AX =;斧子。YLim =[0马克斯(Ng) + 15);文本(uLen (1), Ng (1) + 10, num2str (Ng(1)))文本(uLen (2), Ng (2) + 10, num2str (Ng(2)))文本(uLen (3), Ng (3) + 10, num2str (Ng(3)))包含(“样本长度”)ylabel (系列的数量)标题(的时间序列长度)

有三个独特的数据集的长度:369年、461年和615年样本。汽车旅行是在三个不同的速度,但距离遍历和采样率是恒定的导致不同的数据记录长度。确定有多少记录“破解”(CR)和“无裂缝的”(UNCR)类。
countlabels (allroadLabel)
ans =2×3表标签数百分比_____ _____ CR 109 33.333 UNCR 218 66.667
这个数据集是显著不平衡。有两倍的时间序列没有裂纹(UNCR)系列包含裂纹(CR)。这意味着一个分类器预测“无裂缝的”每个记录将实现67%的准确性没有任何学习。
不同长度的时间序列也。使用卷积网络,共同输入形状是必要的。在复发性网络可以使用不平等的长度时间序列作为输入,但所有时间序列在mini-batch垫或截断基于培训选项。这需要在创建mini-batches进行训练和测试,确保适当的填充序列的分布。此外,它要求你不洗在训练的数据。用小数据集,拖着每个时代的训练数据是可取的。因此,一个共同的时间序列长度。
最常见的长度是461个样本。此外,裂缝,如果存在,集中位于记录。因此,我们可以用369个样本系列对称扩展长度461通过反射初始和最终46样本。615年的录音样本,除去最初的77年和77年最终样品。
培训——特征提取和网络培训
以下部分产生训练集和测试集,建立小波散射序列,和火车都封闭的复发性单元(格勒乌)和一维卷积网络。首先,延长或缩短时间序列在两组获得常见的461个样本长度。
allroadData = equalLenTS (allroadData);(cellfun (@numel allroadData) = = 461)
ans =逻辑1
现在破裂和未破裂中的每个时间序列数据集有461个样本。划分训练集的数据组成的80%的时间序列在每个类和持有剩余的20%的每个类进行测试。验证不平衡的比例在每组保留。
splt8020 = splitlabels (allroadLabel, 0.80);countlabels (allroadLabel (splt8020 {1}))
ans =2×3表标签数百分比_____ _____ CR 87 33.333 UNCR 174 66.667
countlabels (allroadLabel (splt8020 {2}))
ans =2×3表标签数百分比_____ _____ CR 22 33.333 UNCR 44 66.667
创建训练集和测试集。
TrainData = allroadData (splt8020 {1});TrainLabels = allroadLabel (splt8020 {1});TestData = allroadData (splt8020 {2});TestLabels = allroadLabel (splt8020 {2});
洗牌和标签的数据一次培训。
idx = randperm(长度(TrainData));TrainData = TrainData (idx);TrainLabels = TrainLabels (idx);idx = randperm(长度(TrainData));TrainData = TrainData (idx);TrainLabels = TrainLabels (idx);
计算散射序列的每个培训系列。散射序列存储在一个单元阵列与格勒乌网络兼容。这些序列随后改造成一个四维数组输入用于一维卷积网络。
XTrainSCAT =细胞(大小(TrainData));为kk = 1:元素个数(TrainData) XTrainSCAT {kk} = helperscat (TrainData {kk});结束npaths = cellfun (@ (x)大小(x, 1), XTrainSCAT);inputSize = npaths (1);
培训——格勒乌网络
构建格勒乌网络层。使用两个格勒乌层30隐藏单位以及两个辍学层。输入尺寸散射路径的数量。原始时间序列训练这个网络,改变inputSize1、转置每个时间序列行向量(1 -到- 461)。如果你想跳过网络培训,你可以直接到分类和分析部分。在那里你可以加载训练格勒乌网络以及预处理训练集和测试集。
numHiddenUnits1 = 30;numHiddenUnits2 = 30;numClasses = 2;GRUlayers = […sequenceInputLayer (inputSize“名字”,“InputLayer”,…“归一化”,“zerocenter”)gruLayer (numHiddenUnits1“名字”,“GRU1”,“OutputMode”,“序列”)dropoutLayer (0.35,“名字”,“Dropout1”)gruLayer (numHiddenUnits2“名字”,“GRU2”,“OutputMode”,“最后一次”)dropoutLayer (0.2,“名字”,“Dropout2”)fullyConnectedLayer (numClasses“名字”,“FullyConnected”)softmaxLayer (“名字”,“smax”);classificationLayer (“名字”,“ClassificationLayer”));
火车格勒乌网络。使用一个mini-batch 15 150时代的大小。
maxEpochs = 150;miniBatchSize = 15;选择= trainingOptions (“亚当”,…“ExecutionEnvironment”,“图形”,…“L2Regularization”1 e - 3,…“MaxEpochs”maxEpochs,…“MiniBatchSize”miniBatchSize,…“洗牌”,“every-epoch”,…“详细”0,…“阴谋”,“没有”);iterPerEpoch =地板(长度(XTrainSCAT) / miniBatchSize);[scatGRUnet, infoGRU] = trainNetwork (XTrainSCAT、TrainLabels GRUlayers,选项);
画出平滑每迭代训练精度和损失。
图次要情节(2,1,1)smoothedACC =过滤器(1 / iterPerEpoch *的(iterPerEpoch, 1), 1,…infoGRU.TrainingAccuracy);smoothedLoss =过滤器(1 / iterPerEpoch *的(iterPerEpoch, 1), 1,…infoGRU.TrainingLoss);情节(smoothedACC)标题(的训练精度(平滑)”…num2str (iterPerEpoch)“迭代每个时代”])ylabel (的精度(%)100.1)ylim([0])网格在xlim(长度(smoothedACC)[1])次要情节(2,1,2)情节(smoothedLoss) ylim网格(-0.01 [1])在xlim(长度(smoothedLoss) [1]) ylabel (“损失”)包含(“迭代”)

得到小波散射变换了测试数据的分类。
XTestSCAT =细胞(大小(TestData));为kk = 1:元素个数(TestData) XTestSCAT {kk} = helperscat (TestData {kk});结束
训练——一维卷积网络
火车一维卷积网络与小波散射序列。散射序列是28-by-58, 58时间步骤的数目和28散射路径的数量。在一维卷积网络,使用这个转置和重塑散射序列58-by-1-by-28-by-Nsig, Nsig在哪训练实例的数量。如果你想跳过网络培训,你可以直接到分类和分析部分。在那里你可以加载训练卷积网络以及预处理训练集和测试集。
scatCONVTrain = 0(1, 28日,58长度(XTrainSCAT),“单一”);为kk = 1:长度(XTrainSCAT) scatCONVTrain (:,:,: kk) =重塑(XTrainSCAT {kk}’, [58 1 28]);结束
构建和训练一维卷积网络。
conv1dLayers = [imageInputLayer ([58 1 28]);64年convolution2dLayer (1 [3],“步”1);batchNormalizationLayer;reluLayer;2 maxPooling2dLayer ([1]);convolution2dLayer (1 [3], 32);reluLayer;2 maxPooling2dLayer ([1]);fullyConnectedLayer (500);fullyConnectedLayer (2);softmaxLayer; classificationLayer; ]; convoptions = trainingOptions(“个”,…“InitialLearnRate”,0.01,…“LearnRateSchedule”,“分段”,…“LearnRateDropFactor”,0.5,…“LearnRateDropPeriod”5,…“阴谋”,“没有”,…“MaxEpochs”,50岁,…“详细”0,…“阴谋”,“没有”,…“MiniBatchSize”15);[scatCONV1Dnet, infoCONV] =…trainNetwork (scatCONVTrain TrainLabels、conv1dLayers convoptions);
画出平滑每迭代训练精度和损失。
iterPerEpoch =地板(大小(scatCONVTrain 4) / 15);图次要情节(2,1,1)smoothedACC =过滤器(1 / iterPerEpoch *的(iterPerEpoch, 1), 1,…infoCONV.TrainingAccuracy);smoothedLoss =过滤器(1 / iterPerEpoch *的(iterPerEpoch, 1), 1,…infoCONV.TrainingLoss);情节(smoothedACC)标题(的训练精度(平滑)”…num2str (iterPerEpoch)“迭代每个时代”])ylabel (的精度(%)100.1)ylim([0])网格在xlim(长度(smoothedACC)[1])次要情节(2,1,2)情节(smoothedLoss) ylim网格(-0.01 [1])在xlim(长度(smoothedLoss) [1]) ylabel (“损失”)包含(“迭代”)

重塑散射序列的测试集兼容网络分类。
scatCONVTest = 0(1, 28日,58长度(XTestSCAT));为kk = 1:长度(XTestSCAT) scatCONVTest (:,:,: kk) =重塑(XTestSCAT {kk}’, 58岁,28);结束
分类和分析
加载训练封闭的复发性单元(格勒乌)和一维卷积网络测试数据和散射序列。所有数据、特性和网络了培训——特征提取和网络培训部分。
负载(fullfile (saveFolder“transverse_crack_latest”,“TestData.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“TestLabels.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“XTestSCAT.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“scatGRUnet”)加载(fullfile (saveFolder“transverse_crack_latest”,“scatCONV1Dnet.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“scatCONVTest.mat”))
如果你另外需要预处理数据、标签和小波散射序列训练数据,你可以用以下命令加载这些。这些数据和标签不习惯在这个例子的其余部分如果你想跳过以下负载命令。
负载(fullfile (saveFolder“transverse_crack_latest”,“TrainData.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“TrainLabels.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“XTrainSCAT.mat”)加载(fullfile (saveFolder“transverse_crack_latest”,“scatCONVTrain.mat”))
检验时间序列的数量每个类在测试集。注意讨论的测试集是显著不平衡数据预处理部分。
countlabels (TestLabels)
ans =2×3表标签数百分比_____ _____ CR 22 33.333 UNCR 44 66.667
XTestSCAT包含原始时间序列的小波散射序列计算TestData。
显示格勒乌模型性能测试数据中未使用模型的训练。
miniBatchSize = 15;ypredSCAT =分类(scatGRUnet XTestSCAT,…“MiniBatchSize”,miniBatchSize);图confusionchart (TestLabels ypredSCAT,“RowSummary”,“row-normalized”,…“ColumnSummary”,“column-normalized”);标题({“格勒乌网络——小波散射序列”;…“混乱图精度和召回”});

尽管大不平衡类和小数据集,精度和召回值表明网络测试数据上表现良好。具体来说,“破解”数据的精确值是接近98%,召回大约是96%。这些值特别好,因为一个完整的67%的训练集的记录是“无裂缝的”。网络都不灵敏把时间序列分类为“无裂缝的”尽管不平衡。
如果你设置inputSize= 1和转置训练的时间序列数据,您可以再培训格勒乌网络原始时间序列数据。这样做是在相同的数据网络的训练集,你可以加载和检查测试集上的性能。
负载(fullfile (saveFolder“transverse_crack_latest”,“tsGRUnet.mat”));rawTest = cellfun (@transpose TestData,“UniformOutput”、假);miniBatchSize = 15;YPredraw =分类(tsGRUnet rawTest,…“MiniBatchSize”,miniBatchSize);confusionchart (TestLabels YPredraw,“RowSummary”,“row-normalized”,…“ColumnSummary”,“column-normalized”);标题({格勒乌网络——原始时间序列的;…“混乱图精度和召回”});

这个网络的性能不是很好。具体来说,“破解”数据的回忆很差。假阴性的数量“裂纹”数据是相当大的。这正是你所期望的不平衡数据集模型时没有学得很好。
测试小波散射的一维卷积网络训练序列。
miniBatchSize = 15;YPredSCAT =分类(scatCONV1Dnet scatCONVTest,…“MiniBatchSize”,miniBatchSize);图confusionchart (TestLabels YPredSCAT,“RowSummary”,“row-normalized”,…“ColumnSummary”,“column-normalized”);标题({“一维卷积网络——小波散射序列”;…“混乱图精度和召回”});

与散射序列卷积网络的性能很好,超过了格勒乌网络的性能。精度和召回少数类展示强劲的学习。
训练一维卷积网络原始序列集合inputSize = (461 1)在imageInputLayer。你可以加载和测试网络。
负载(fullfile (saveFolder“transverse_crack_latest”,“tsCONV1Dnet.mat”));XTestData = cell2mat (TestData ');XTestData =重塑(XTestData [461 1 66]);miniBatchSize = 15;YPredRAW =分类(tsCONV1Dnet XTestData,…“MiniBatchSize”,miniBatchSize);confusionchart (TestLabels YPredRAW,“RowSummary”,“row-normalized”,…“ColumnSummary”,“column-normalized”);标题({“一维卷积网络——原始序列”;…“混乱图精度和召回”});

原始序列的一维卷积网络比格勒乌网络性能更好,但不是以及卷积网络训练小波散射序列。进一步减少在时间维度与散射变换的数据导致了网络,大约是8.5倍小于卷积网络训练的原始数据。
小波推理和分析
本节演示了如何使用小波分析单个时间序列分类pretrained模型。模型使用一维卷积网络训练小波散射序列。负荷训练网络和一些测试数据,如果您还没有加载这些在前一节中。
负载(fullfile (saveFolder“transverse_crack_latest”,“scatCONV1Dnet.mat”));负载(fullfile (saveFolder“transverse_crack_latest”,“TestData.mat”));
构造小波散射网络转换数据。选择一个时间序列的测试数据和分类数据。如果模型分类时间序列作为“破解”,调查系列裂纹的位置的波形。
科幻小说= waveletScattering (“SignalLength”,461,…“OversamplingFactor”,1“qualityfactors”8 [1],…“InvarianceScale”,0.05,“边界”,“反映”,“SamplingFrequency”,1280);idx = 1;data = TestData {idx};[smat x] = featureVectors(数据,科幻小说);PredictedClass =分类(scatCONV1Dnet smat);如果isequal (PredictedClass“CR”)流(裂纹检测。计算小波变换模极大值。\ n”)wtmm(数据,“缩放”,“本地”);结束
裂纹检测。计算小波变换模极大值。
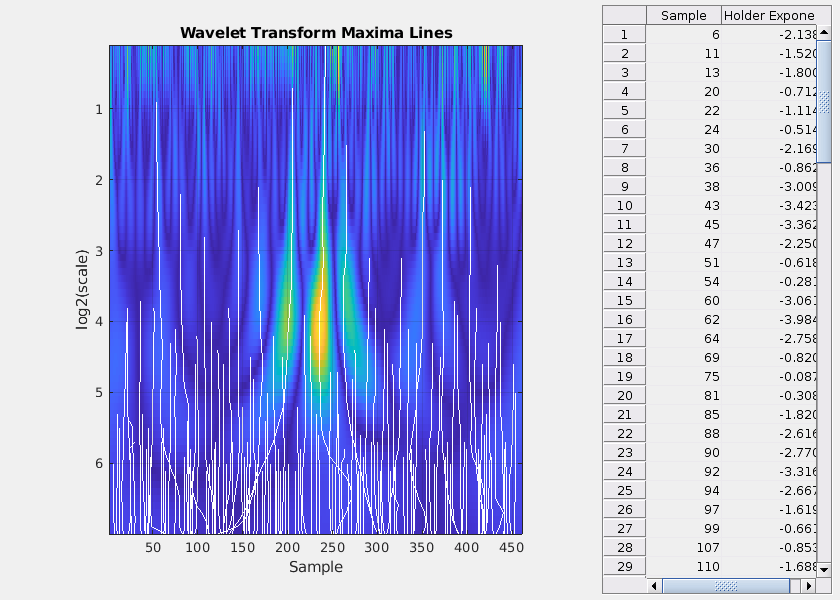
小波变换模极大值(WTMM)技术显示了极大值线收敛于最优秀的规模在205样品。极大值线收敛于细尺度是一个很好的估计的奇点在时间序列。这使得样本205良好的裂缝的位置估计。
情节(x,数据)轴紧持有在情节([x (205) (205)], [min(数据)max(数据)],“k”网格)在标题([“裂纹位于”num2str (x (205))“米”])包含(“距离(m)”)ylabel (“振幅”)

你可以增加你的信心在这个位置,利用多分辨率分析(MRA)技术和识别的变化斜率长刻度小波多分辨系列。看到实用介绍多分辨率分析MRA技术概论。在[1)之间的能量差异“破解”和“未”系列发生在低频段,特别的间隔(10、20)赫兹。因此,关注以下MRA信号组件从[80]赫兹频段。在这些乐队,识别线性变化的数据。情节变化点随着MRA组件。
[mra, chngpts] = helperMRA(数据,x);

的MRA-based changepoint分析有助于确认WTMM分析确定该地区约1.8米的可能的裂纹的位置。
总结
这个例子展示了如何使用小波散射序列与复发和卷积网络对时间序列进行分类。例子进一步说明了小波技术可以帮助本地化特征在同一空间(时间)规模与原始数据。
引用
[1],群和石狮。“沥青路面横向裂缝的识别车辆振动信号分析的基础上。”,2020岁的道路材料和路面设计研究-。https://doi.org/10.1080/14680629.2020.1714699。
[2]周,石狮。“车辆振动数据。”https://data.mendeley.com/datasets/3dvpjy4m22/1。数据使用下CC 4.0。从原始数据重新包装Excel mat文件数据格式。速度标签删除,只保留“裂纹”或“nocrack”标签。
附录
这个示例中所使用的辅助函数。
函数smat = helperscat (datain)%这个helper函数只支持小波工具箱的例子。金宝app%,它可能改变或在将来的版本中被删除。datain =单(datain);sn = waveletScattering (“SignalLength”、长度(datain),…“OversamplingFactor”,1“qualityfactors”8 [1],…“InvarianceScale”,0.05,“边界”,“反映”,“SamplingFrequency”,1280);smat = sn.featureMatrix (datain);结束% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -函数dataUL = equalLenTS(数据)%这个函数只支持小波工具箱的例子。金宝app%,它可能改变或在将来的版本中被删除。N =长度(数据);dataUL =细胞(N, 1);为kk = 1: N L =长度(数据{kk});开关l情况下461年dataUL {kk} = {kk}数据;情况下369年Ndiff = 461 - 369;垫= Ndiff / 2;dataUL {kk} =[翻转(数据{kk}(1:垫);数据{kk};…翻转(数据{kk} (L-pad + 1: L)));否则Ndiff = l - 461;zr = Ndiff / 2;dataUL {kk} = {kk}数据(zr: end-zrs-1);结束结束结束% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -函数(fmat x) = featureVectors(数据、科幻小说)%这个函数只支持小波工具箱的例子。金宝app%,它可能改变或在将来的版本中被删除。data =单(数据);N =长度(数据);dt = 1/1280;如果N < 461 Ndiff = 461 - N;垫= Ndiff / 2;dataUL =[翻转(数据(1:垫);数据;…翻转(数据(N-pad + 1: N)));率= 5 e4/3600;dx =速度* dt;x = 0: dx: dx (N * dx);elseifN > 461 Ndiff = N - 461;zr = Ndiff / 2;dataUL =数据(zr: end-zrs-1);率= 3 e4/3600;dx =速度* dt;x = 0: dx: dx (N * dx);其他的dataUL =数据;率= 4 e4/3600;dx =速度* dt;x = 0: dx: dx (N * dx);结束fmat = sf.featureMatrix (dataUL);fmat =重塑(fmat”, [58 1 28]);结束% - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -函数[mra, chngpts] = helperMRA(数据,x)%这个函数只支持小波工具箱的例子。金宝app%,它可能改变或在将来的版本中被删除。mra = modwtmra (modwt(数据,“sym3”),“sym3”);mraLev = mra (4:6 -:);Ns =大小(mraLev, 1);打= (2、4、8);chngpts = false(大小(mraLev));%确定changepoints。我们希望不同的阈值不同%的分辨率水平。为2 = 1:Ns chngpts (ii):) = ischange (mraLev (ii):)“线性”2,“阈值”打(ii));结束为kk = 1: Ns idx =双(chngpts (kk,:));idx (idx = = 0) =南;次要情节(Ns, 1 kk)情节(x, mraLev (kk,:))如果kk = = 1标题(“MRA组件”)结束yyaxis正确的hs =茎(x, idx);海关。ShowBaseLine =“关闭”;海关。标志=“^”;海关。MarkerFaceColor = (1 0 0);结束网格在轴紧包含(“距离(m)”)结束